Rotary Position Embedding (RoPE) deep dive
0. Why positional encoding (PE)?
Standard attention has no sense of order.
- Give it “I ate food” or “food ate I” —> same output
- We need to inject position info explicitly
Two flavors:
- Absolute PE: assign each token a position index, embed it, add to the token embedding before projection. Transformer’s sinusoidal PE, BERT’s learned PE are both absolute.
- Formula:
- Applied before
, , projection.
- Formula:
- Relative PE: encode the relative distance between tokens directly inside the attention score computation.
- The model doesn’t care “token 5 is at position 5”, it cares “token 5 is 3 steps away from token 2.”
- Better extrapolation to longer sequences.
RoPE is relative PE. It’s now the standard for most LLMs (Qwen, LLaMA, etc.).
1. Rotation encodes relative position
Start simple: 2D vectors.
Let
Key insight:
- rotating both vectors by the same angle doesn’t change their dot product
- only the angle between them matters, not their absolute orientation in space.
So what if we rotate
rotated → angle increases by rotated → angle increases by - New angle between them:
The dot product now encodes the relative position
To rotate a 2D vector
2. From 2D to d-dimensional RoPE
In practice,
RoPE handles this by splitting the
Why different
- If all groups used the same
, different pairs would be redundant -> they’d all encode position at the same granularity. - Using different
values gives each pair a different “clock speed”, allowing the model to represent position at multiple scales simultaneously.
The
: fastest. completes a full rotation every tokens : slowest. needs around tokens for one full rotation
Think of it like a clock with many hands:
- Early pairs: fast-ticking seconds hand → sensitive to local differences
- Later pairs: slow-ticking hour hand → sensitive to global position
This is the same intuition as sinusoidal position encoding in the original Transformer, just applied via rotation instead of addition.
3. Long-distance decay
Long-distance decay
- A desirable property for attention: nearby tokens should attend to each other more strongly than distant ones.
- RoPE naturally achieves this
- With the decreasing
schedule, the attention score between and tends to decrease as grows.
Intuition
- when positions are far apart, the fast-rotating pairs (large
) swing rapidly and average out - only the slow pairs contribute coherently, and there are fewer of them.
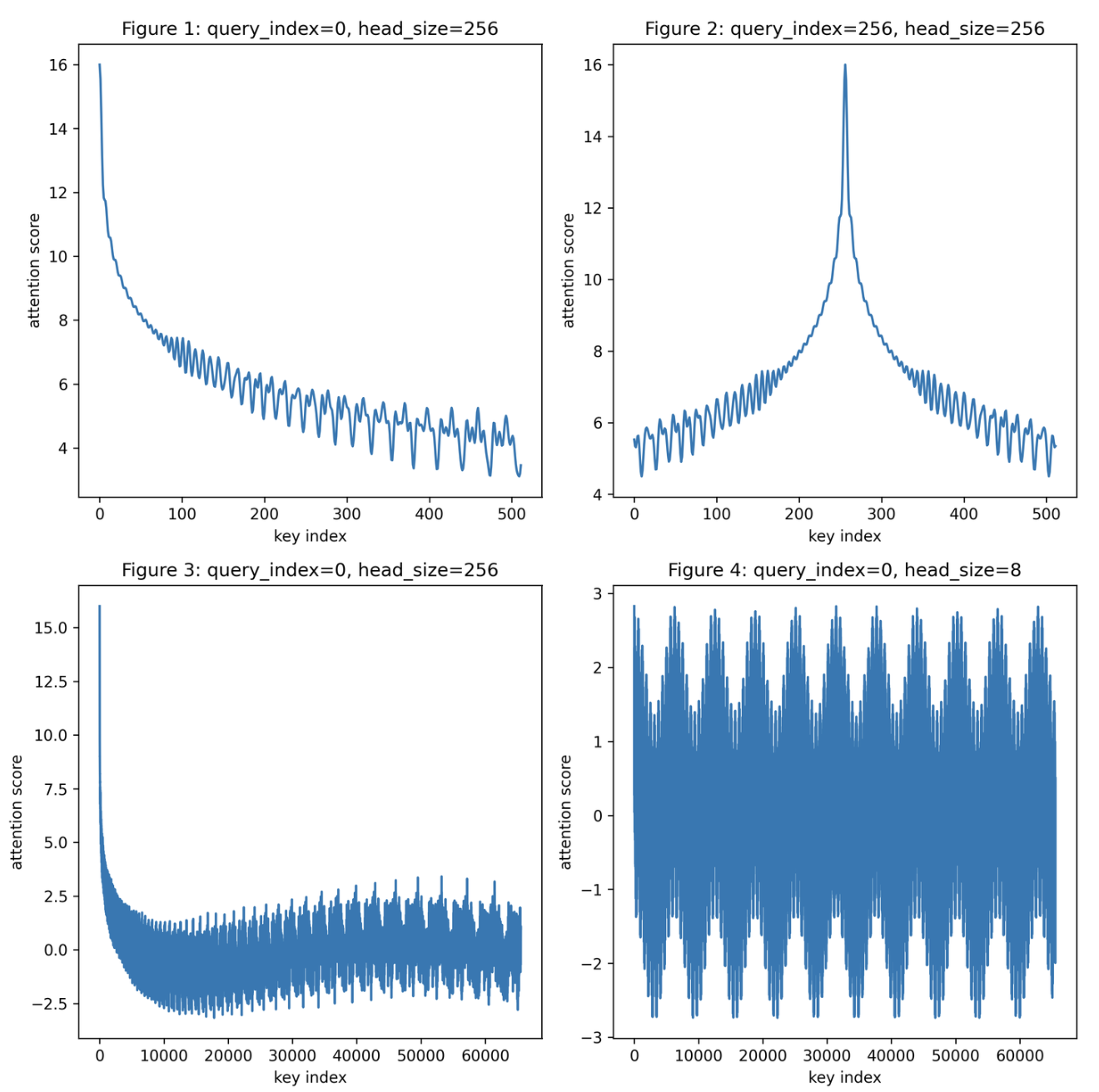
Four regimes:
- Fig 1 (short range, normal head size): clean decay. attention drops as key moves away from query.
- Fig 2 (query in the middle): symmetric decay on both sides.
- Fig 3 (long range, normal head size): decay holds even at 65k token distances.
- Fig 4 (tiny head size = 8): decay degrades — too few dimension pairs to maintain the property.
This confirms the NLP prior: adjacent tokens are semantically related more often than distant ones.
4. How RoPE plugs into attention
RoPE is applied after projection, before the attention dot product:
- Applied to
and only, not . - Each token’s query/key vector gets rotated by an angle proportional to its position index.
Why here and not earlier?
- Absolute PE is added before projection (
), so it bakes position into every downstream operation. - RoPE injects position only into the attention score computation, keeping the rest of the network position-agnostic. This is cleaner.
5. Efficient implementation
Doing a full
where:
- original vector
: repeated per pair : element-wise multiplication : swap and negate within each pair
No matrix multiply. Just element-wise operations. Pre-compute the sin/cos tables once and reuse.
1 | |
6. Extrapolation
Extrapolation: can the model handle sequences longer than its training length?
For absolute PE, no — position indices beyond the training range were never seen.
For RoPE, the situation is subtler. Direct extrapolation (just use larger position indices) sounds fine in theory but fails in practice.
Here’s why. Recall
- For
: . A training length of 2048 lets and rotate up to full turns. Fine. - For
: . Needs tokens for one full rotation. - At training length 2048, the last few pairs have barely rotated at all (less than
of a turn) - These pairs carry long-range position signal.
- At inference with longer sequences, the model encounters rotation angles it was never trained on for these slow pairs → extrapolation fails.
7. Position interpolation
Fix: scale down position indices so inference positions map back into the training range.
If training length is
- Position indices
are mapped to . - The model sees rotation angles within the range it was trained on.
Trade-off
- adjacent tokens now have a smaller angular gap → the model must distinguish finer differences
- needs a small amount of fine-tuning (≈ 1000 steps) to recover full quality
- Experimentally: linear interpolation without fine-tuning is worse than direct extrapolation, but with fine-tuning the results match the original
8. NTK-aware Scaled RoPE
Linear interpolation compresses all frequency groups equally. But:
- High-frequency pairs (
large) already rotate many times within training length -> compressing them further just loses resolution. - Low-frequency pairs (
small) are the bottleneck and need the rescaling.
NTK-aware Scaled RoPE: scale high frequencies less, low frequencies more. The rescaled base becomes:
Equivalently:
- When
(highest freq): multiplied by → no scaling. - When
(lowest freq): multiplied by → same as linear interpolation. - Everything in between: smooth interpolation of scaling.
This works without any fine-tuning and significantly outperforms direct extrapolation. Fine-tuning on top pushes it further.
Implementations:
LlamadynamicNTKScalingRotaryEmbeddingin HuggingFace transformers- Dynamic Scaled RoPE further improves performance for long-context LLaMA
Sources: