DeepSeek V4 attention: how it handles longer context (Video + Blog)
English Video Link: https://www.youtube.com/watch?v=x8r5EWuelwk
Chinese Video Link: https://www.youtube.com/watch?v=Lj0XXRRny70
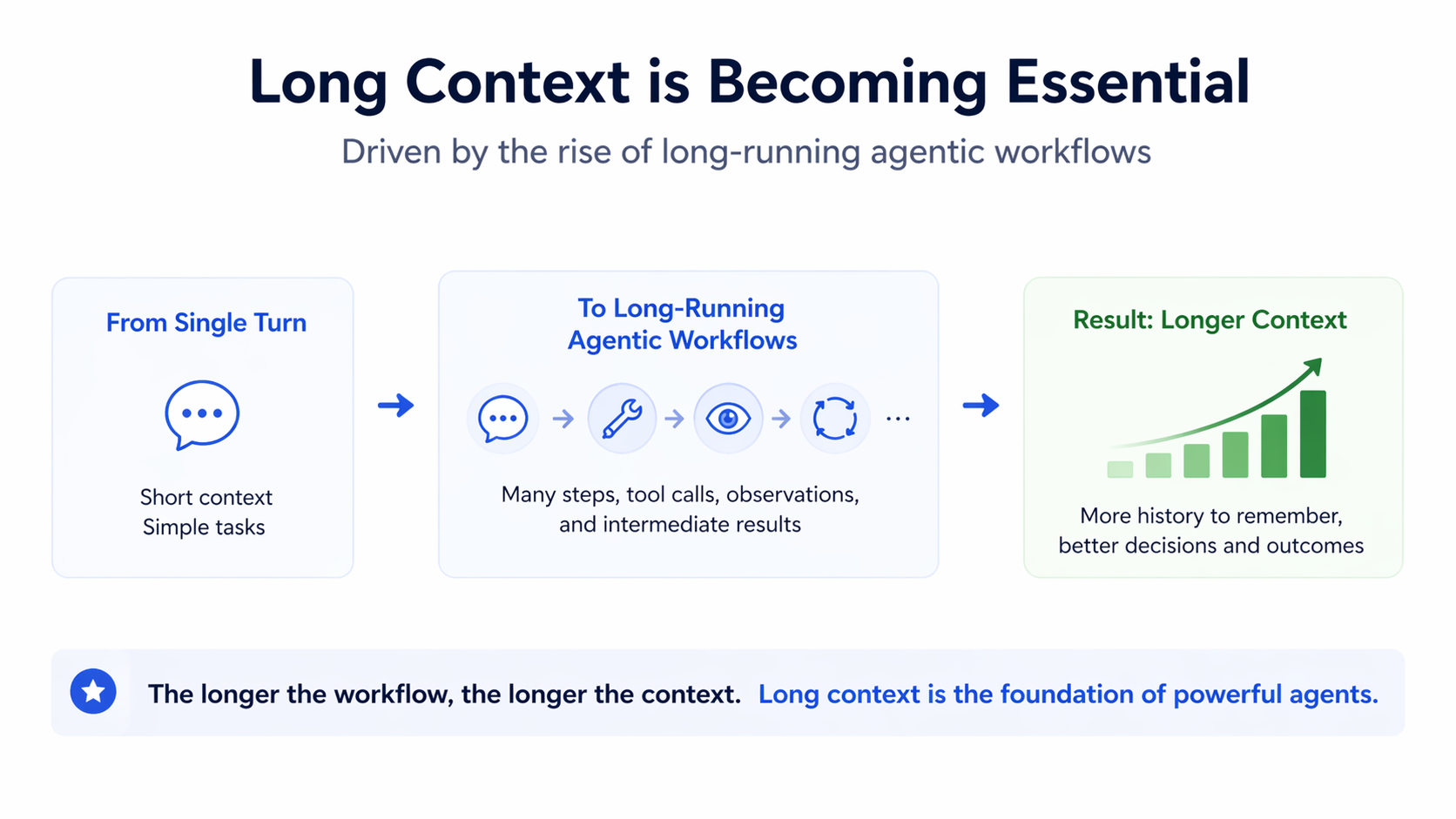
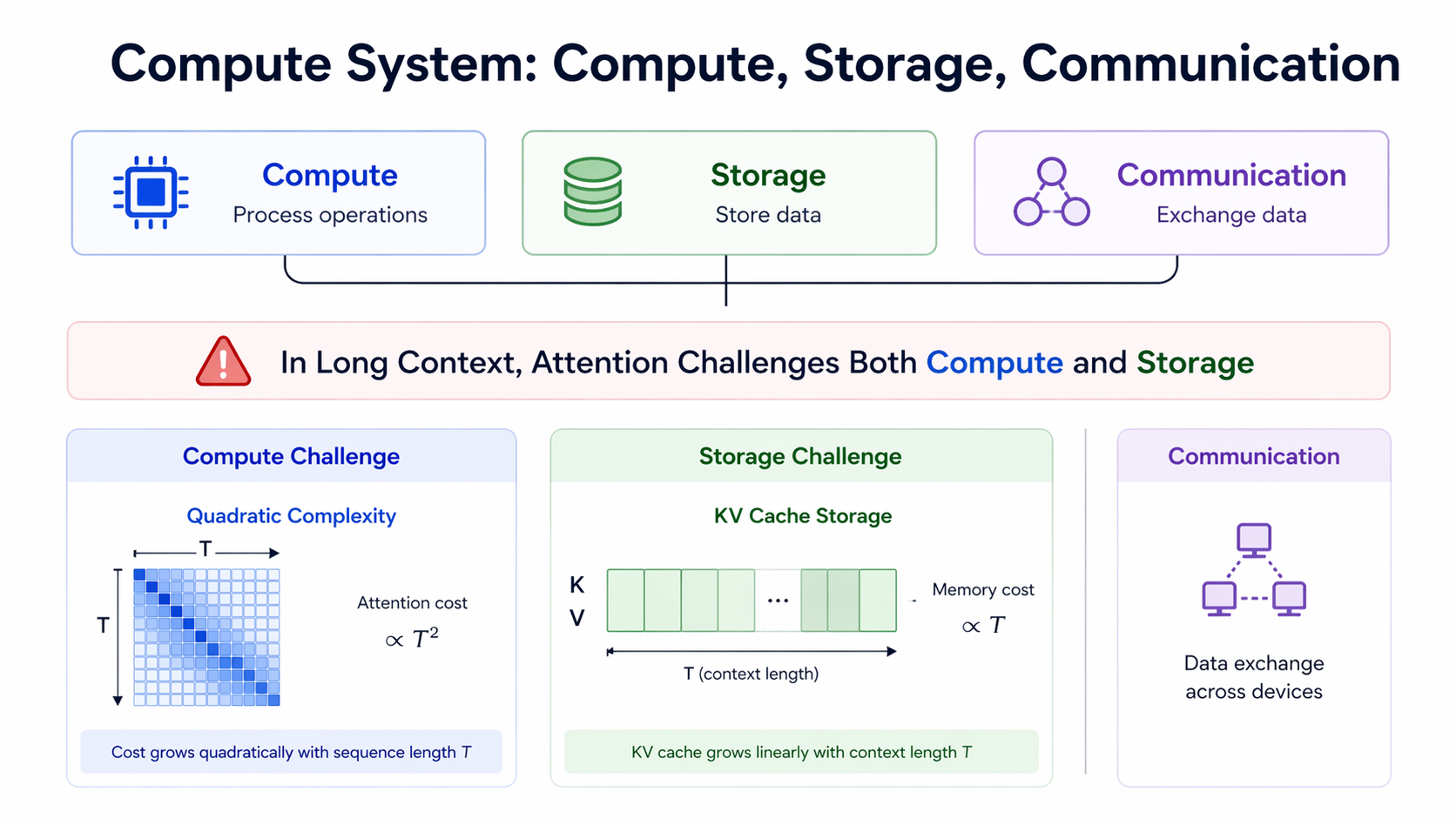
1. Long context challenges

2. From MLA, DSA to HCA/CSA

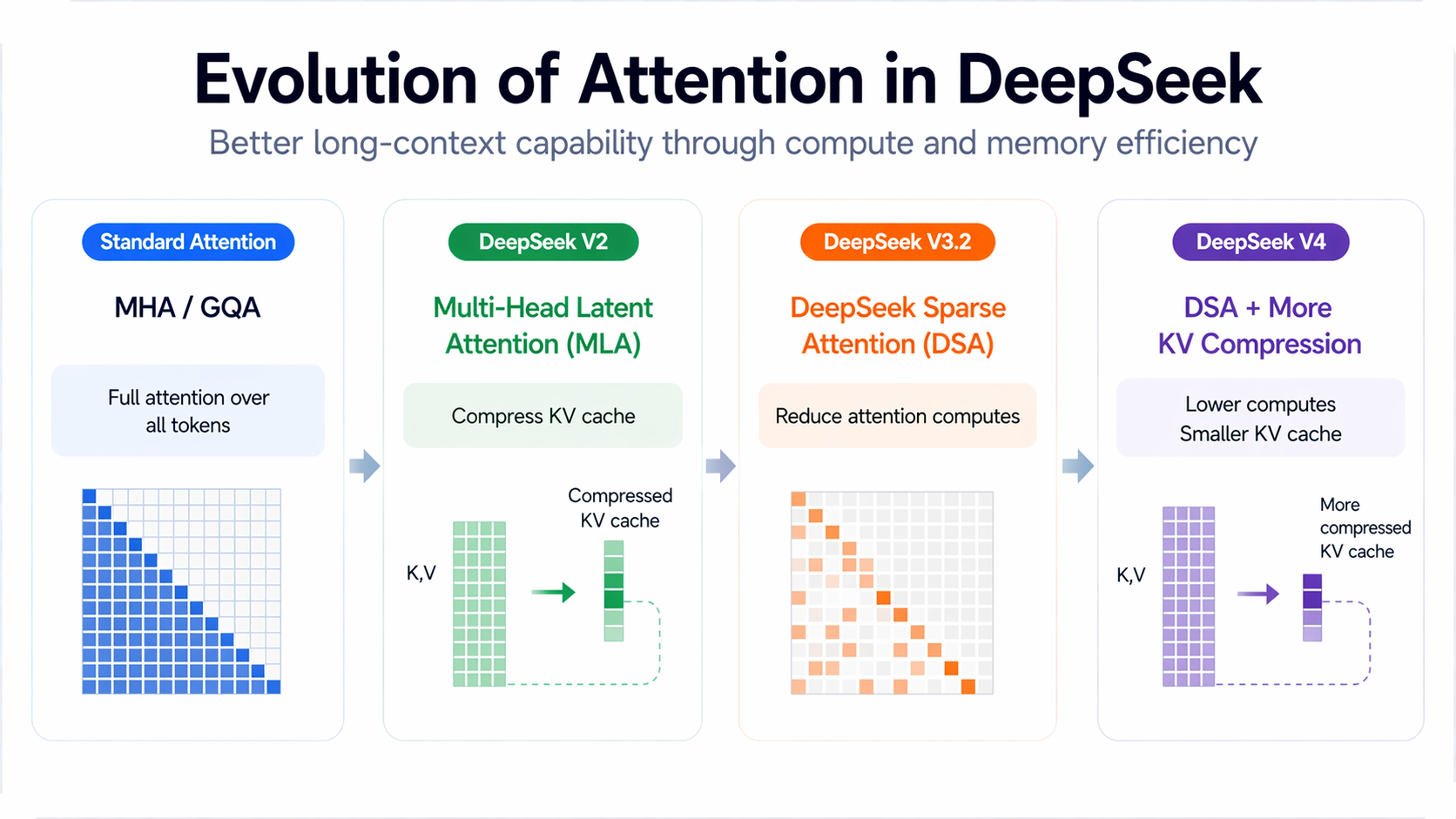
3. MLA: low-rank KV cache
Purpose: reduce KV cache size
Method: compress KV into a low-rank latent space (D → R)
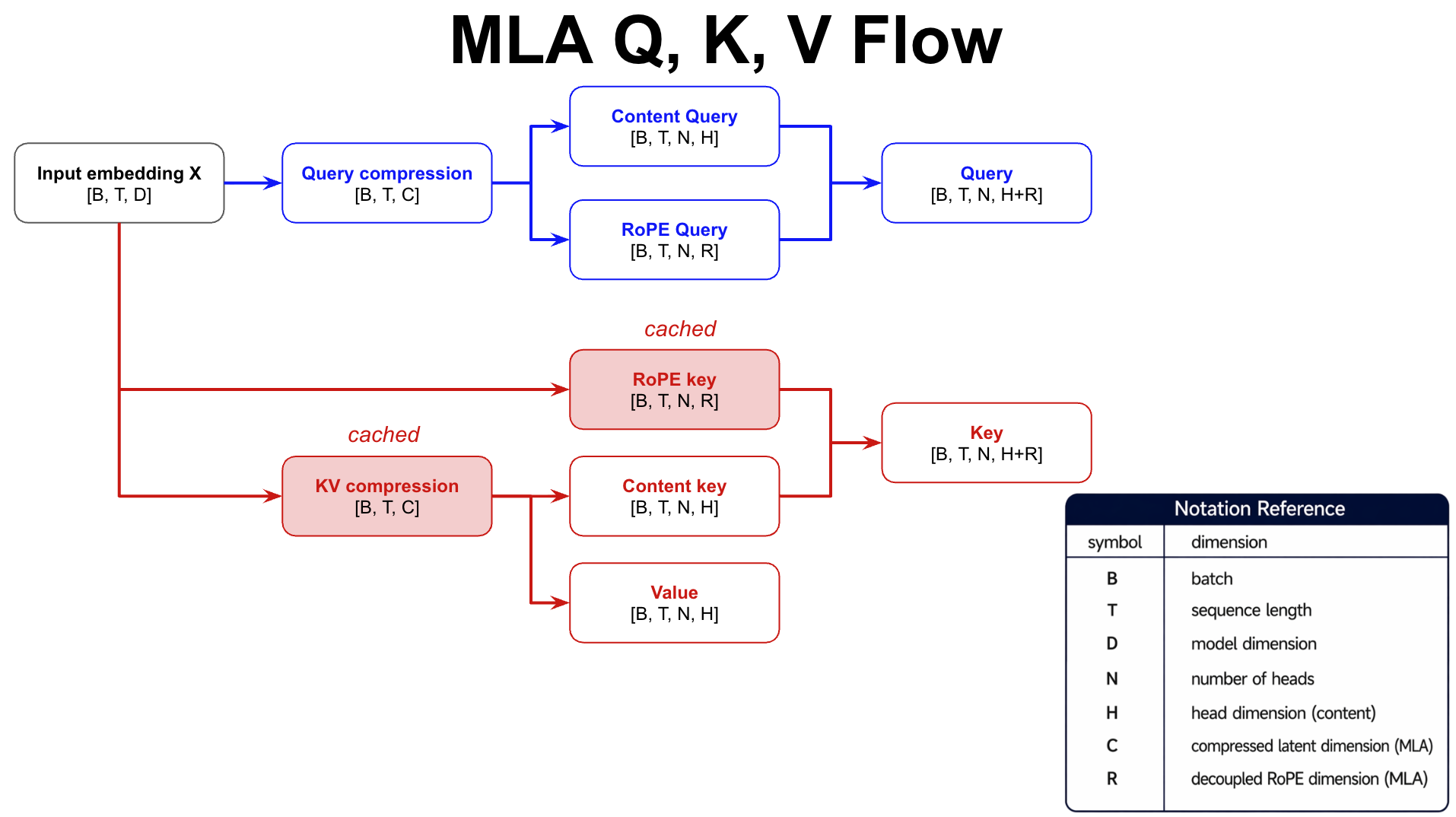
Decoupled RoPE
without RoPE
$$
Q K^\top = (C_QW_{UQ} )( C_{KV}W_{UK} )^\top \ = C_Q W_{UQ} W_{UK}^\top C_{KV}^\top \ = C_Q (W_{UQ} W_{UK}^\top) C_{KV}
$$
with RoPE
$$
Q K^\top = (C_QW_{UQ} R_Q)( C_{KV}W_{UK}R_K )^\top \ = C_Q W_{UQ}R_Q R_K^\top W_{UK}^\top C_{KV}^\top \ = C_Q W_{UQ}R_\Delta W_{UK}^\top C_{KV}^\top
$$
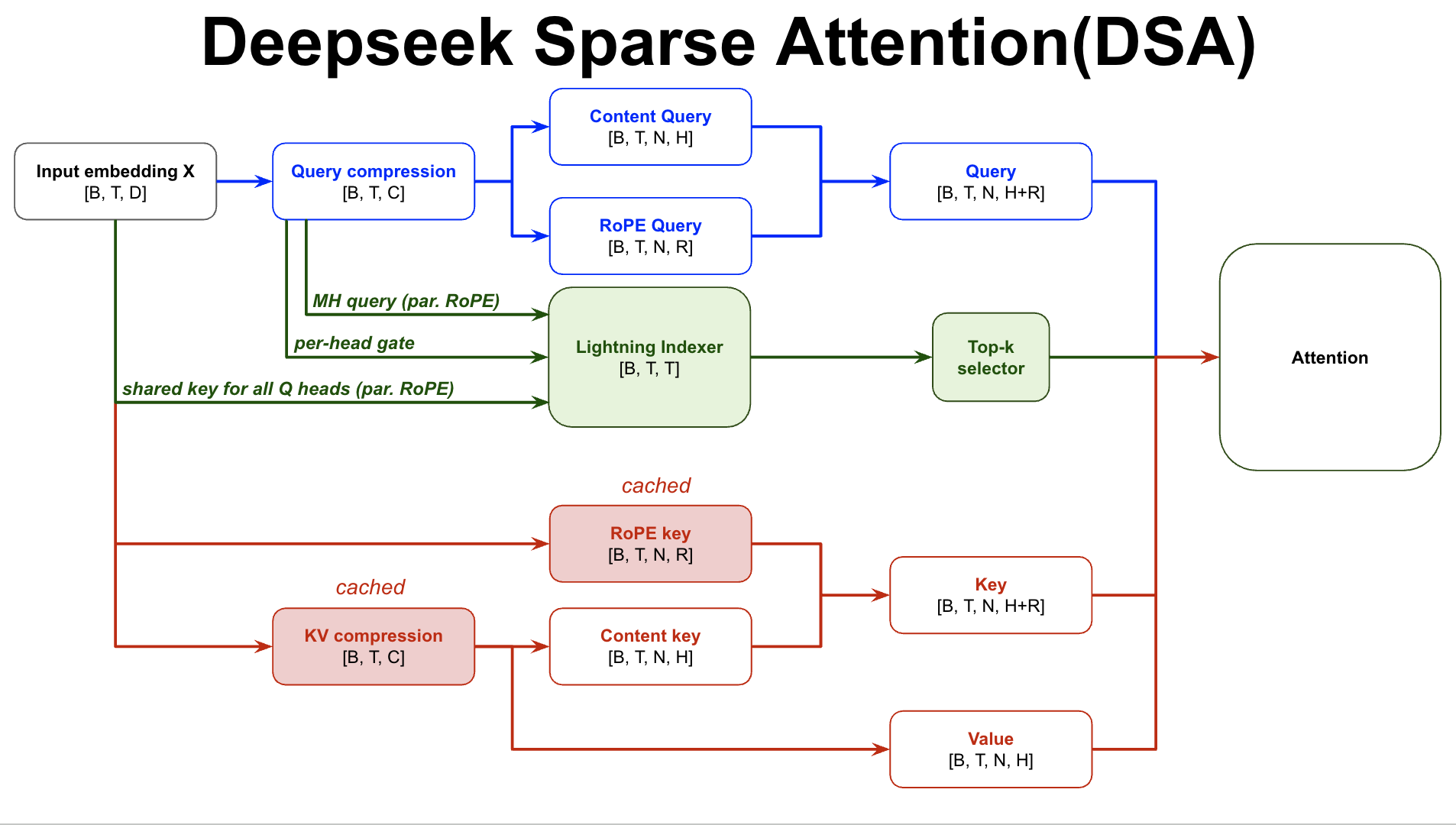
4. DSA: top-k attention
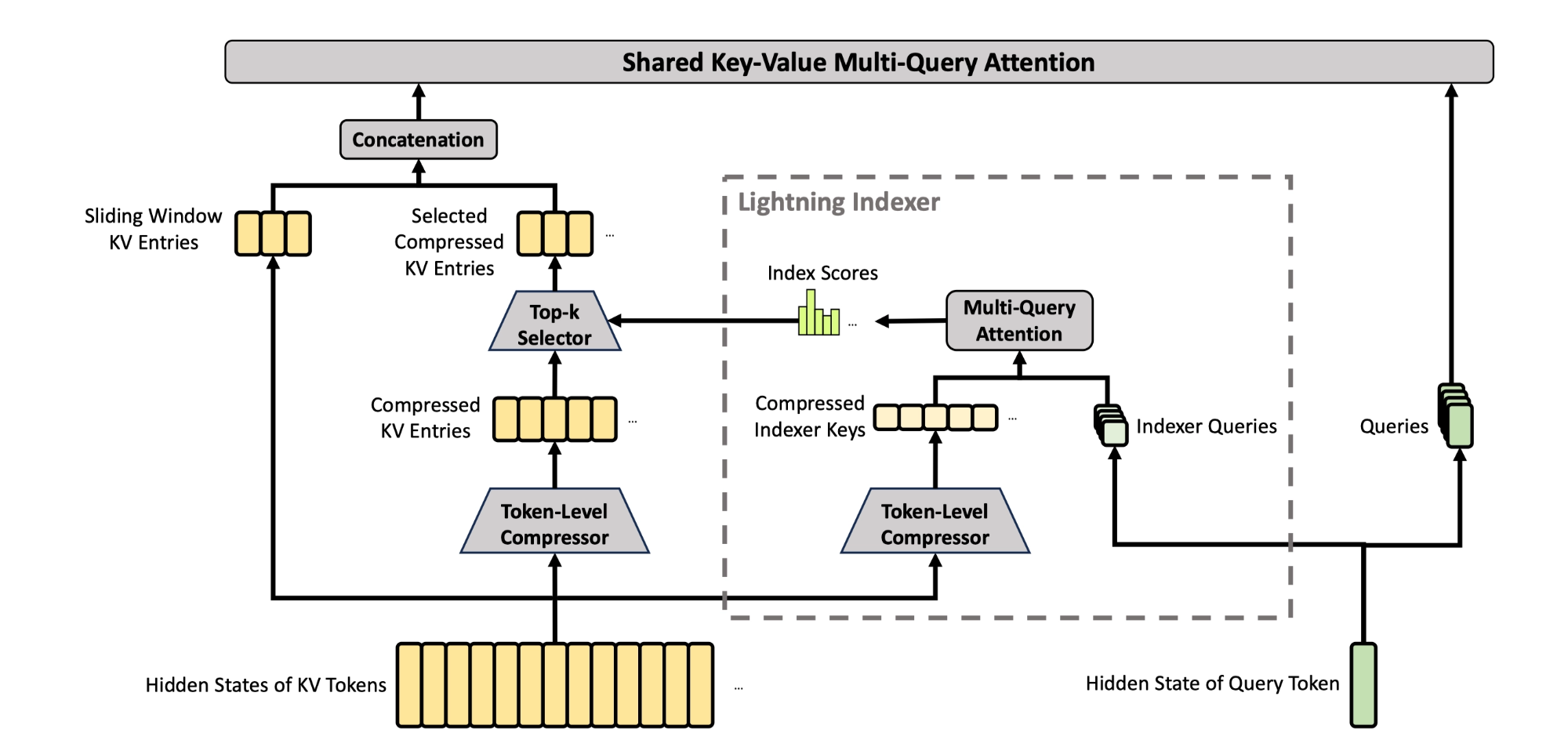
5. V4 Hybrid attention
CSA (C4A)
- compress the KV cache of every 4 tokens into one entry
- then apply DSA where each query token attends to only 𝑘 compressed KV entries
- sliding-window branch: attend to previous 128 uncompressed tokens
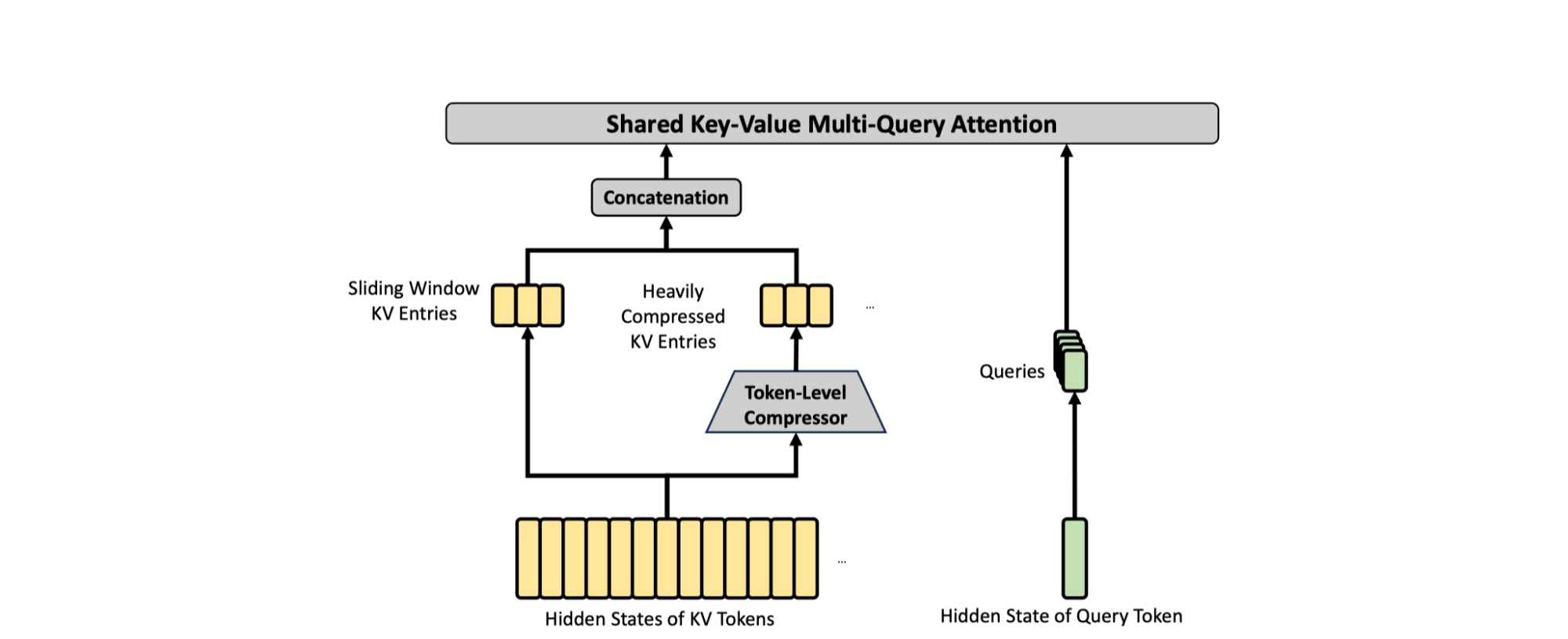
HCA (C128A)
- compress the KV cache of every 128 tokens into one entry
- then apply dense attention
- same sliding-window branch
References
DeepSeek V4 attention: how it handles longer context (Video + Blog)
https://gdymind.github.io/2026/04/27/DeepSeek-V4-attention-deep-dive-say-yes-to-longer-context/