vLLM-Omni deep dive

0. What is Omni-modality?
- Omni- is a Latin prefix meaning “all” or “every”
- Omnipotent: All-powerful
- Omniscient: All-knowing
- OAI released GPT-4o (GPT-4 Omni), shifting from unimodal (text-only) to omni-modal (all-modalities, including text, image/video, audio/speech)
- “Omni” marks a paradigm shift in AI
- from chaining separate models (e.g., Whisper + Llama + TTS)
- toward unified, single-tower arch that process text, image, audio, and video through a shared latent space
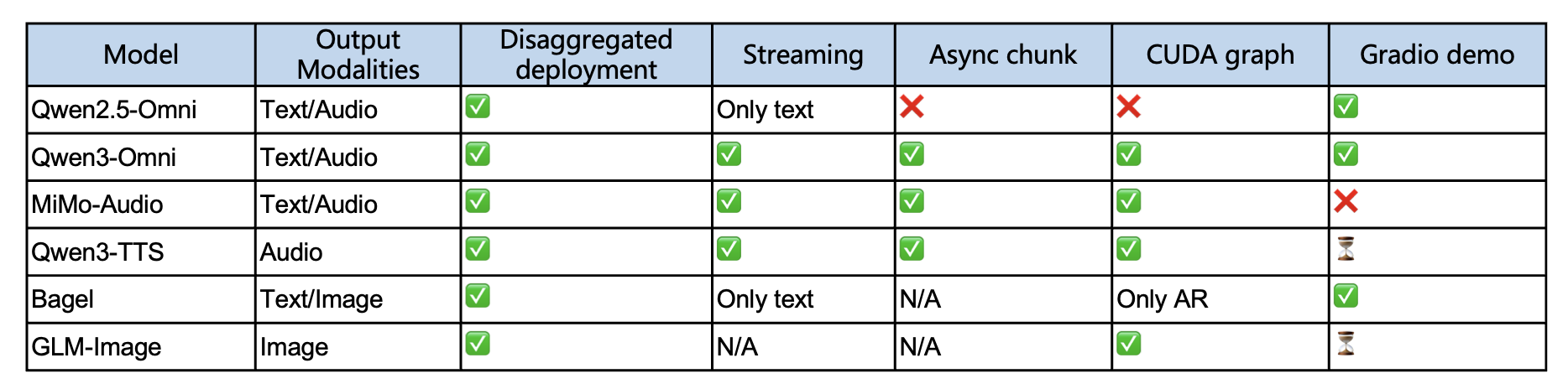
OSS Omni models
- Qwen:
- Qwen2-VL / Qwen2-Audio: early models
- Qwen2.5-Omni: introducing Thinker-Talker
- Qwen3-Omni (Flash): lightweight, low-latency version for real-time
- Qwen3.5-Omni (March 2026): current flagship
- GLM
- GLM-4-Omni (August 2024): 1st major open-source “Omni” model from China
- CogVLM2-Video: visual backbone for their Omni-capable infra
- MiMo-V2-Omni
- Mini-Omni / Mini-Omni2
- …
1. Why starting vLLM-Omni?
by Roger Wang
TLDR: end-to-end Omni-modality models need efficient multi-stage management
1.1 end-to-end models
vLLM-Omni was started shortly after Qwen2.5-Omni / MiniCPM-o releases (Apr 2025)
both were e2e models
- supporting Omni understanding (as inputs)
- AND supporting Omni generation (as outputs)
1.2 difficulties to support e2d models
- encoding was larger and larger
- diffusion models era: T5 for encoding was suffieicent
- Qwen-Image dual-encoding: Qwen2.5-VL + VAE encoder
- more complicated pipelines/workflows
- diffusion before: one encoding + one DiT decoding
- now: Qwen2.5-Omni has Thinker, Talker, Vision/Audio encoder, etc.
- TTS before: one encoding + one audio generation step
- now: Xiao MiMo-Audio has more inteactions during encoding
- https://github.com/XiaomiMiMo/MiMo-Audio
1.3 multi-stage management
Needed a good framework for multi-stage management
- conventional LLMs have two stages: prefill and decode
- e2e Omni models can have various and quite different stages
- Omni encoding, Omni input process
- Omni generation
- interactions between different modalities
- …
- more data transfers and interactions among stages
- data transfer: not only KV cache, but also various embeddings
- interaction: transfer can be bidrectional / back and forth
- the workflow was quite complicated and not stablized → need a dedicated framwork that envloes with model developments (stages may change a lot)
… multiple stages are processed by different LLMEngines, DiffusionEngines or other types of engines.
Depending on different types of stages, such as AR stage or DiT stage, each can choose corresponding schedulers, model workers to load with the Engines in a plug-in fashion.
FAQ
Q1: How large will Omni models be?
It will continue to scale (not clear what a good Omini model is at this point)
- Qwen2.5-Omni: 7B
- Qwen3-Omni: 30B
- Qwen3.5-Omni: even larger
Q2: difference between Omni models and VLM
- VLM can handle Omni understading tasks
- Omni focuses more on Omni generation
Q3: does Omni need autoscaling for individual stages in the future?
- yes
Q4: does AR and diffusion models have a unified abstracion?
- no unified abstraction
- the unified abstraction in vLLM-Omni is “stage”
2. vLLM-Omni overview
vLLM supports Omni inputs, while vLLM-Omni also supports Omni outputs
Omni-modality: Text, image, video, and audio data processing
Non-AR Architectures: extend the AR support of vLLM to Diffusion Transformers (DiT) and other parallel generation models
Heterogeneous outputs: from traditional text generation to multimodal outputs
Broad model support

3. System walkthrough
by Zhipeng Wang
Goal
- understand how vLLM-Omni processes a multi-modal request and generates its multi-modal outputs.
- learn where to modify if you would like to make a specific modification/contribution.
3.1 Model types
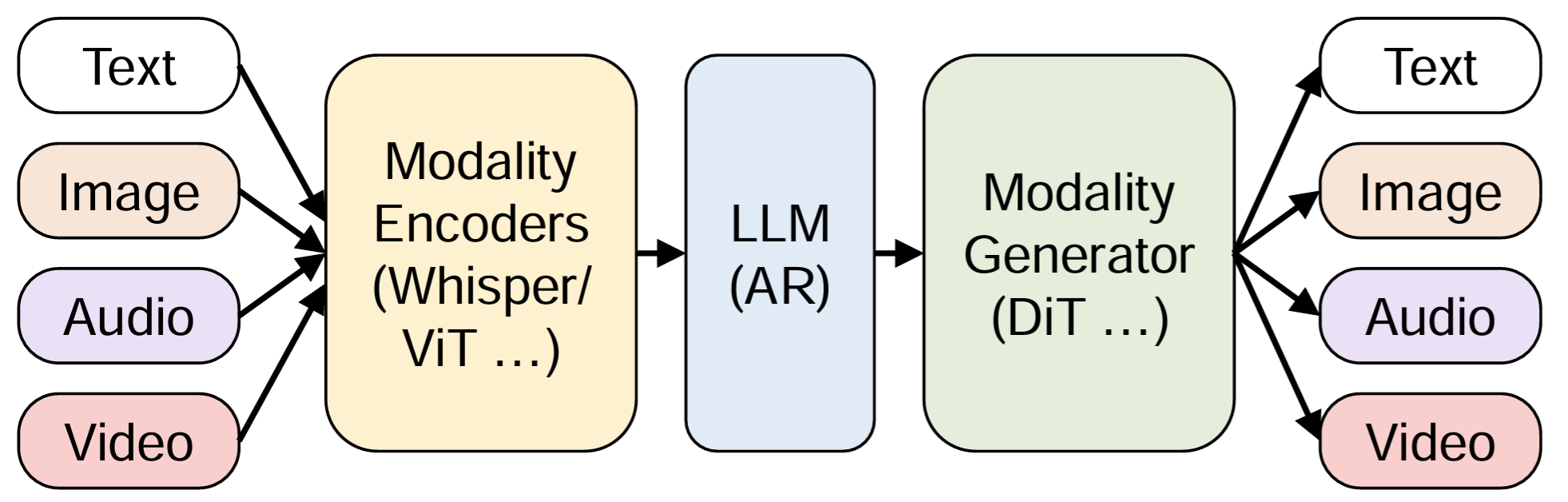
(a) Thinker-talker
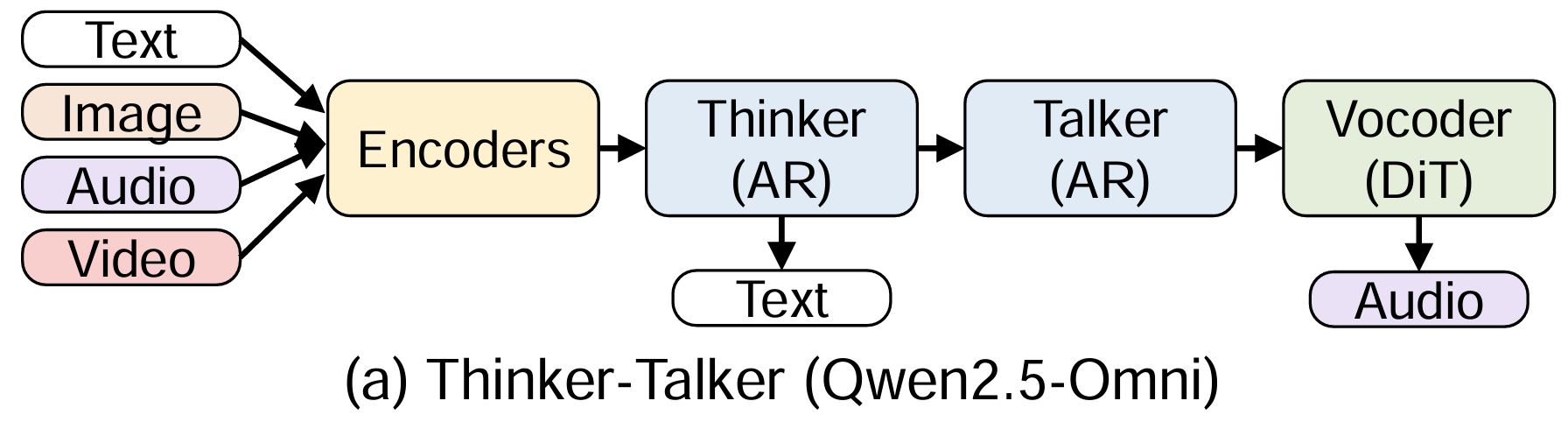
Tasks
- any-to-any
- a natively e2e omni-modal LLM for multimodal inputs (text/image/audio/video…) and outputs (text/audio…)
Backbone: multiple AR decoders + DiT
Models: Qwen-Omni/Ming-Omni
(b) AR + DiT
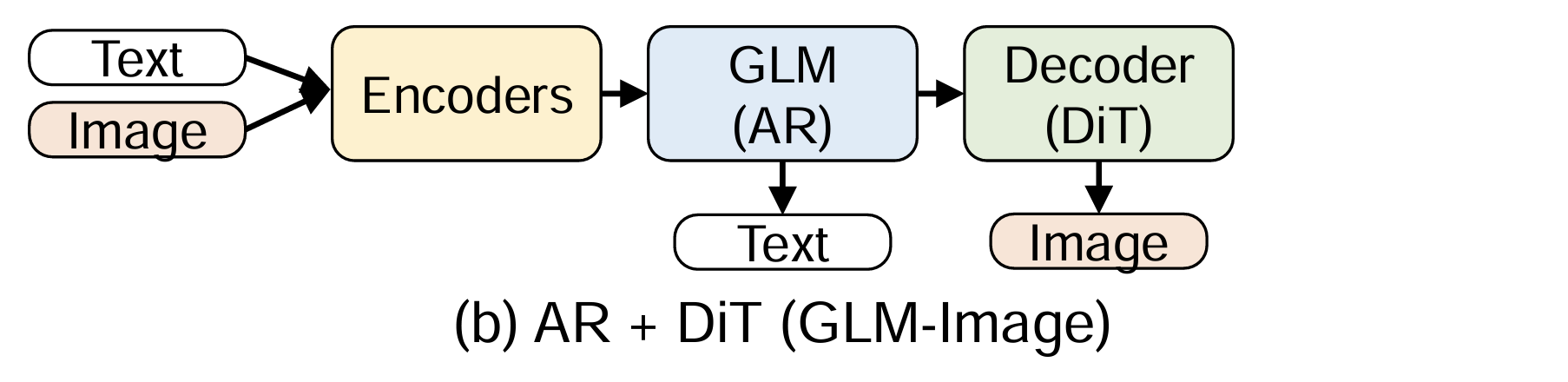
Tasks
- text2image, text2video, image2image, etc.
- a powerful image generation foundation model capable of complex text rendering and precise image editing
Backbone: AR + DiT
- DiT as a main structure, with AR as text encoder
Models: Qwen-Image/GLM-Image
(c) AR + specialized generator
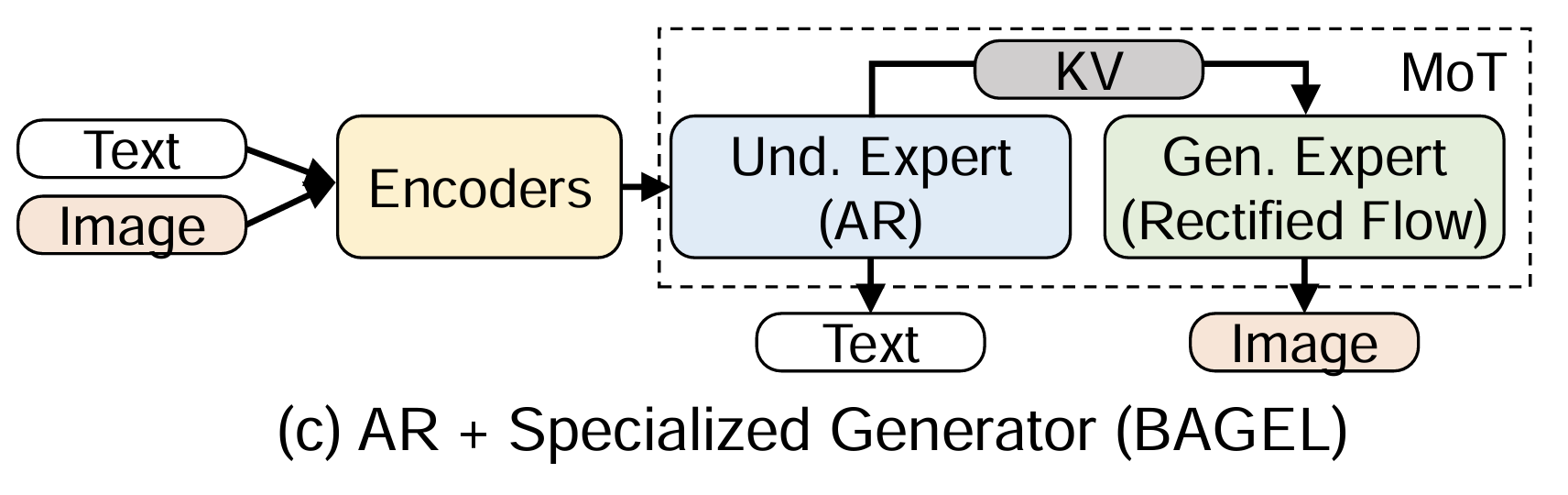
Tasks
- text2image, image2image, image2text, etc.
- a unified multimodal comprehension and generation model, with CoT text output and visual generation
Backbone: AR + Spec. Gen.
Models: BAGEL, Hunyuan Image 3.0
3.2 AR vs DiT
| AR | DiT | |
|---|---|---|
| Use cases | Text generation | Multi-modelity generation |
| Generation process | Token-by-token KV Cache based | Diffusion step |
| Bottleneck | Prefill: compute bound | |
| Decode: memory bound | Compute bound | |
| Seq length | varied | Fixed |
| Attention Mask | causal mask | Full mask |
| parallelism | TP/DP/EP/PP/CP/SP | TP/EP/USP/CFG (explained later) |
3.3 vLLM-Omni arch
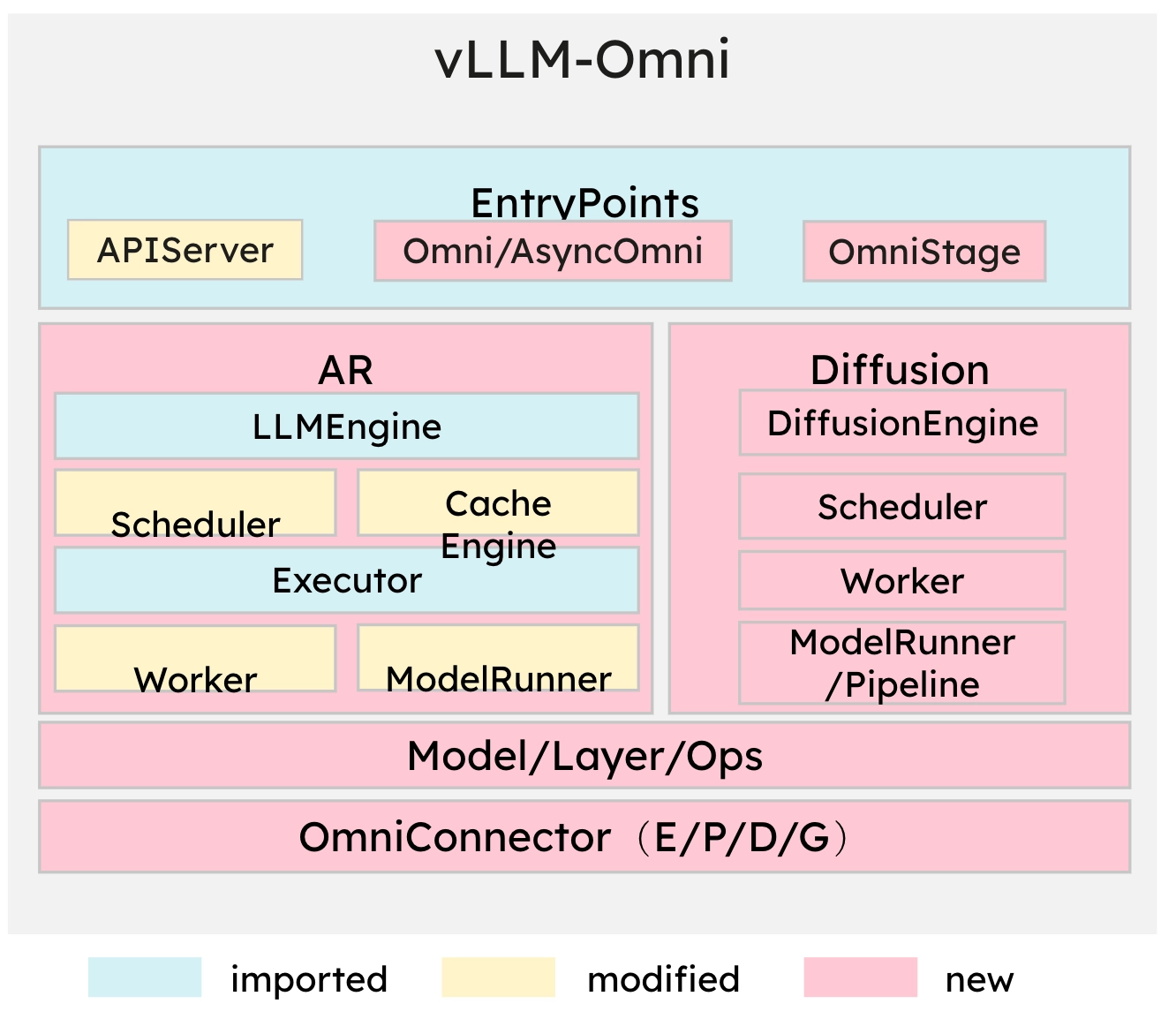
- Entrypoints: offline/online serving, OmniStage abstraction for model stages(AR/DiT)
- AR module: inherited from vLLM (cotinous batching/paged attention/prefix caching…) and adapted to the Omni-modality model
- modified some part, e.g., to expose hidden states
- Diffusion module: implemented natively and optimized by acceleration components
- Model/Layer/ops: parallelism, quantization, attention…
- OmniConnector: natively supports E/P/D/G ((Encoding/Processing/Decoding/Generation) ) disaggregation
3.4 Hardware plugin system
- Multi-Hardware Coverage: CUDA/ROCm/NPU/XPU
- Composable Inheritance: Reuses vLLM’s native platform capabilities (for AR) via multiple inheritance while adding Omni-specific interfaces.
- Unified Abstract Interface: current_omni_platform
- Op Dispatch: Attention backends and custom ops are dispatched per-platform with hardware-optimized implementations.
4. AR module design
by Zhipeng Wang
4.1 system arch
- Handles autoregressive generation stages:
- Text generation
- Hidden embeddings: e.g., for audio genration Qwen-Omni
- multimodal latent tokens: e.g., Talker in Qwen3-Omni need some AR genarations
- Extends vLLM’s core to support:
- Multimodal inputs/outputs: processing images, videos, and audio alongside text
- Prompt Embedding: passing pre-computed prompt embeddings between pipeline stages via serialized payloads
- Additional information: Carrying per-request metadata (tensors, lists), e.g., for tone/style instructions, through the pipeline
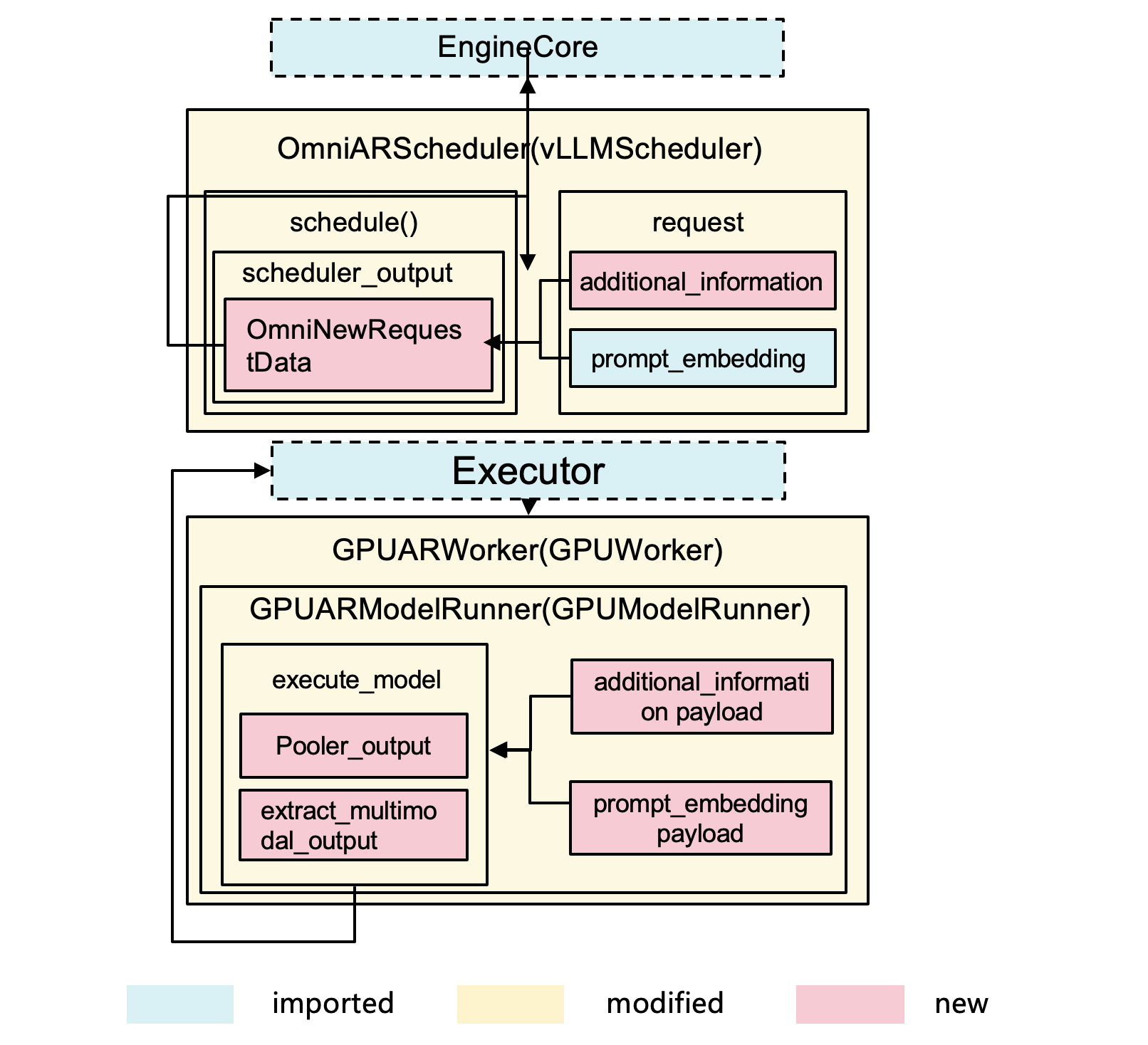
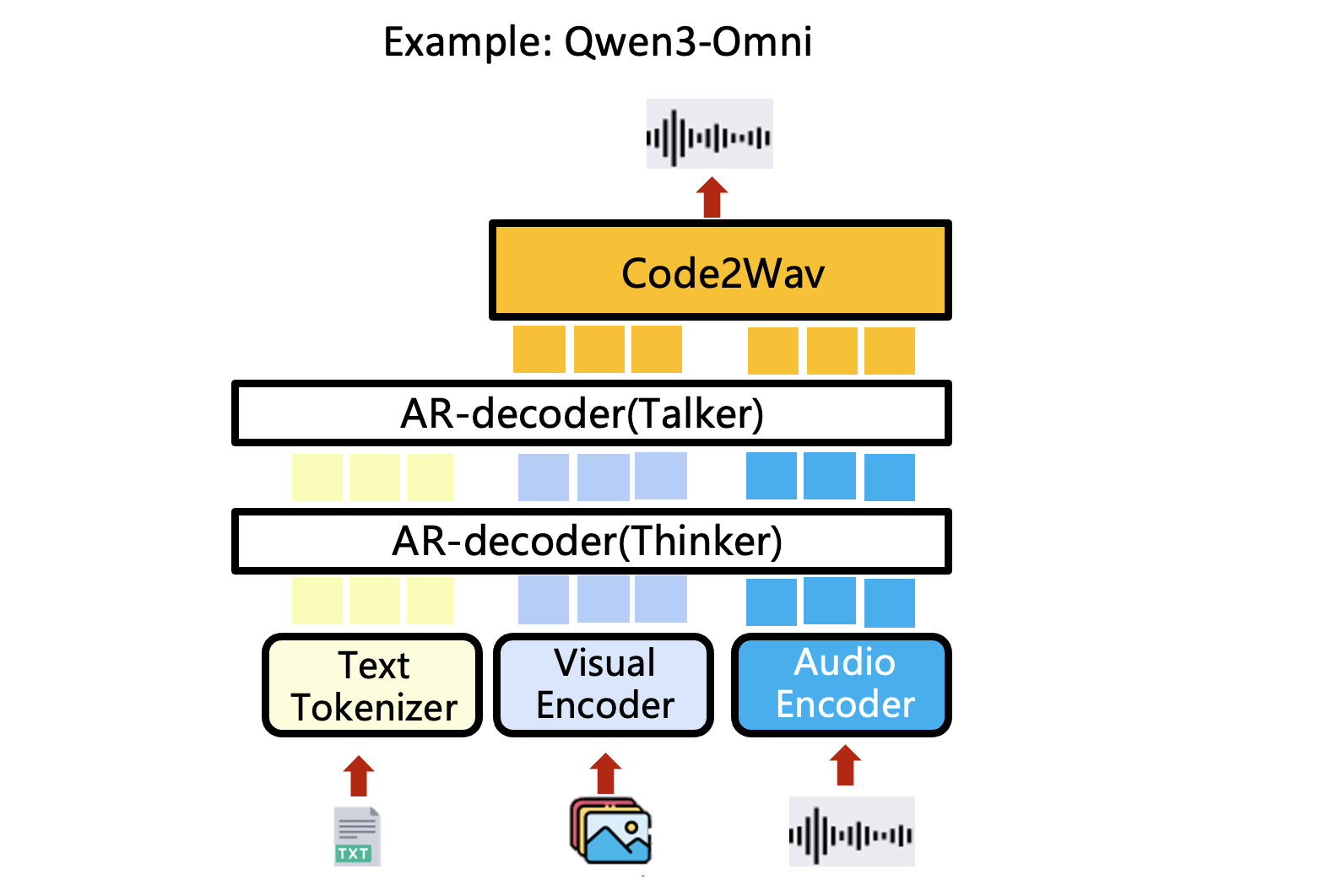
4.2 stage abstraction: Qwen3-Omni example
- config file: https://github.com/vllm-project/vllm-omni/blob/main/vllm_omni/model_executor/stage_configs/qwen3_omni_moe.yaml
- 3 stages: thinker, talker, and Code2wav
- thinker: Omni understanding
- talker and Code2wave: TTS
- these stages can be put on different devices
- we can config their ultilizaiton, output type, etc.
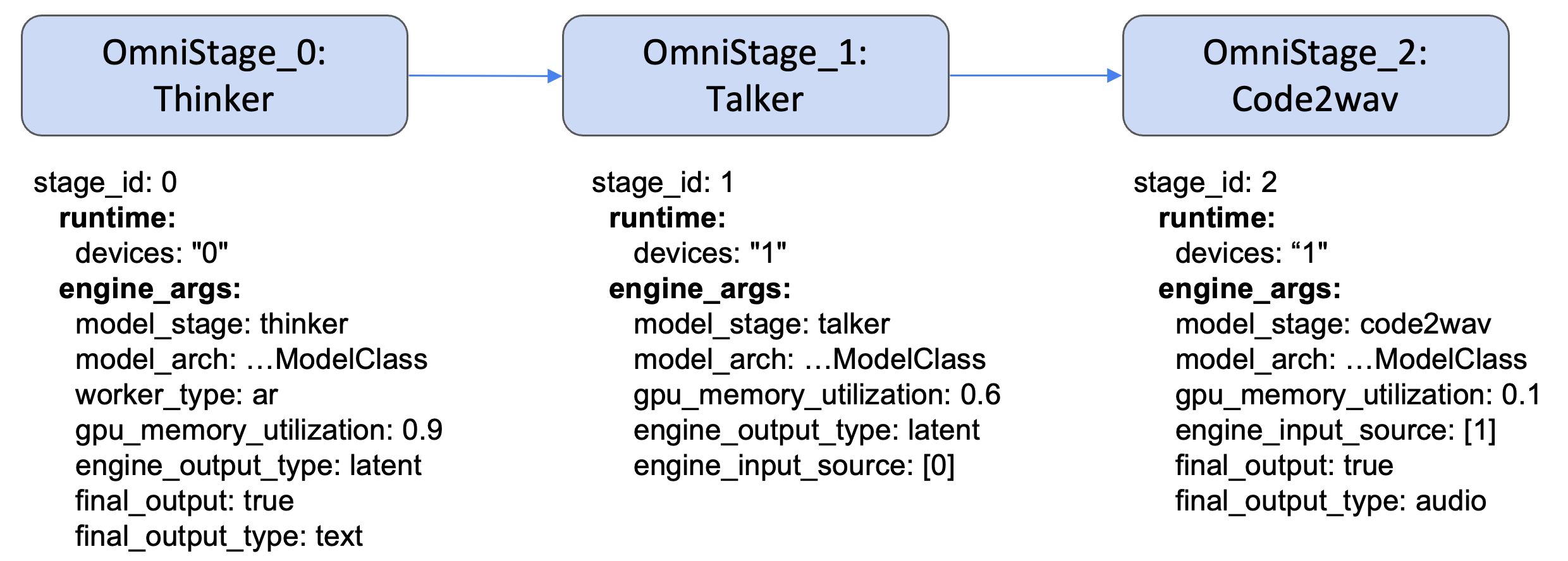
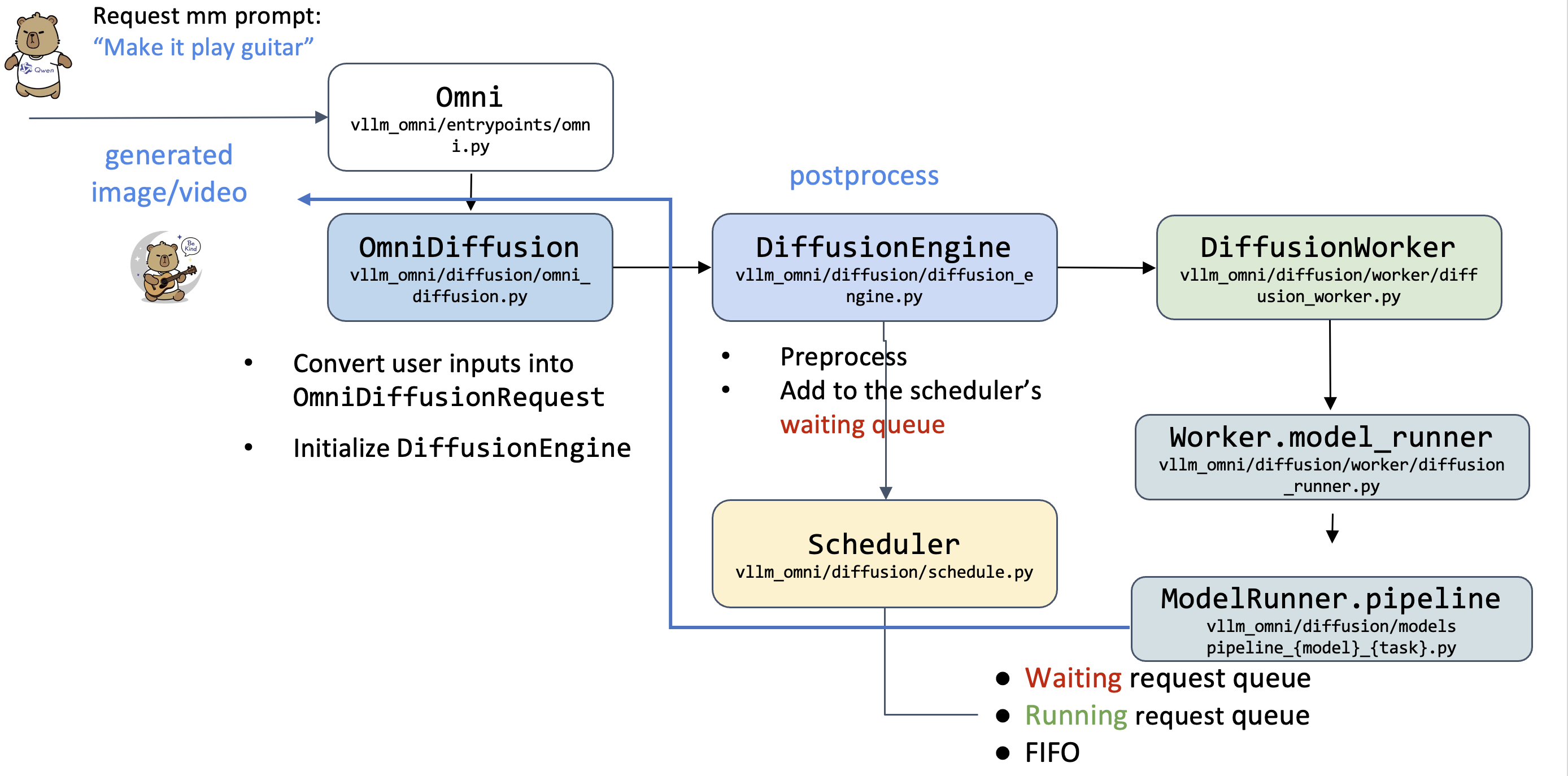
4.3 disagg serving
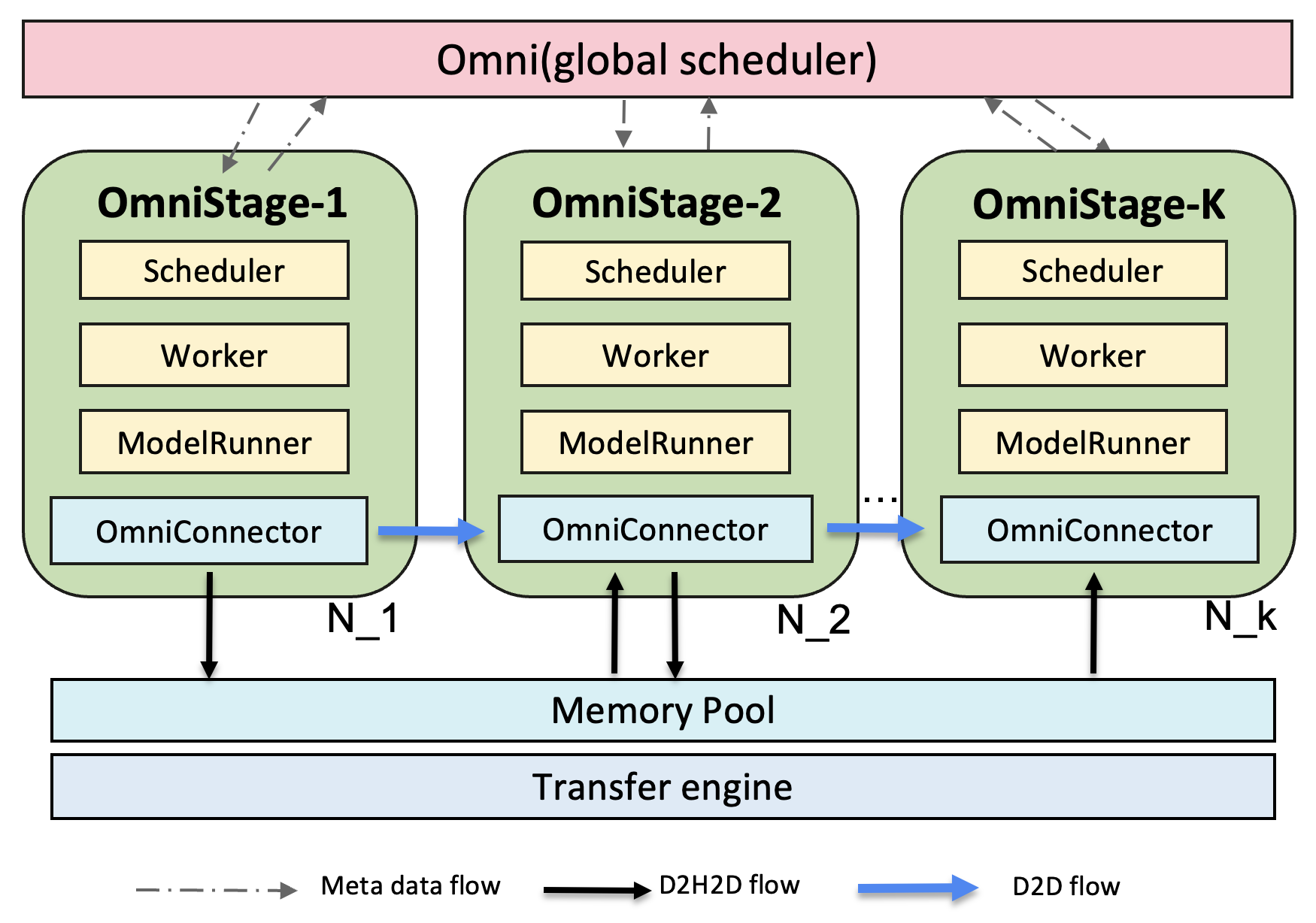
- Standardized Unified Abstraction: A generalized interface that handles heterogeneous data (Text, Image, Audio).
- e.g., Owen3-Omni thinker outputs hidden states rather than token IDs
- OmniConnector handles data transfer, no matther it’s tensor, float, or something else
- Control & Data Plane Decoupling: Metadata travels via lightweight control signals, while heavy payloads are offloaded to high-performance data planes.
- Hybrid Backend Support: Native support for Shared Memory (SHM) and Mooncake for distributed transfers.
- Disaggregated Multi-Modal Execution: Enables seamless communication between decoupled stages.
- Multi-Instance Scaling: Supports multiple instances for each omni stage, enabling elastic deployment and efficient load distribution across distributed clusters.
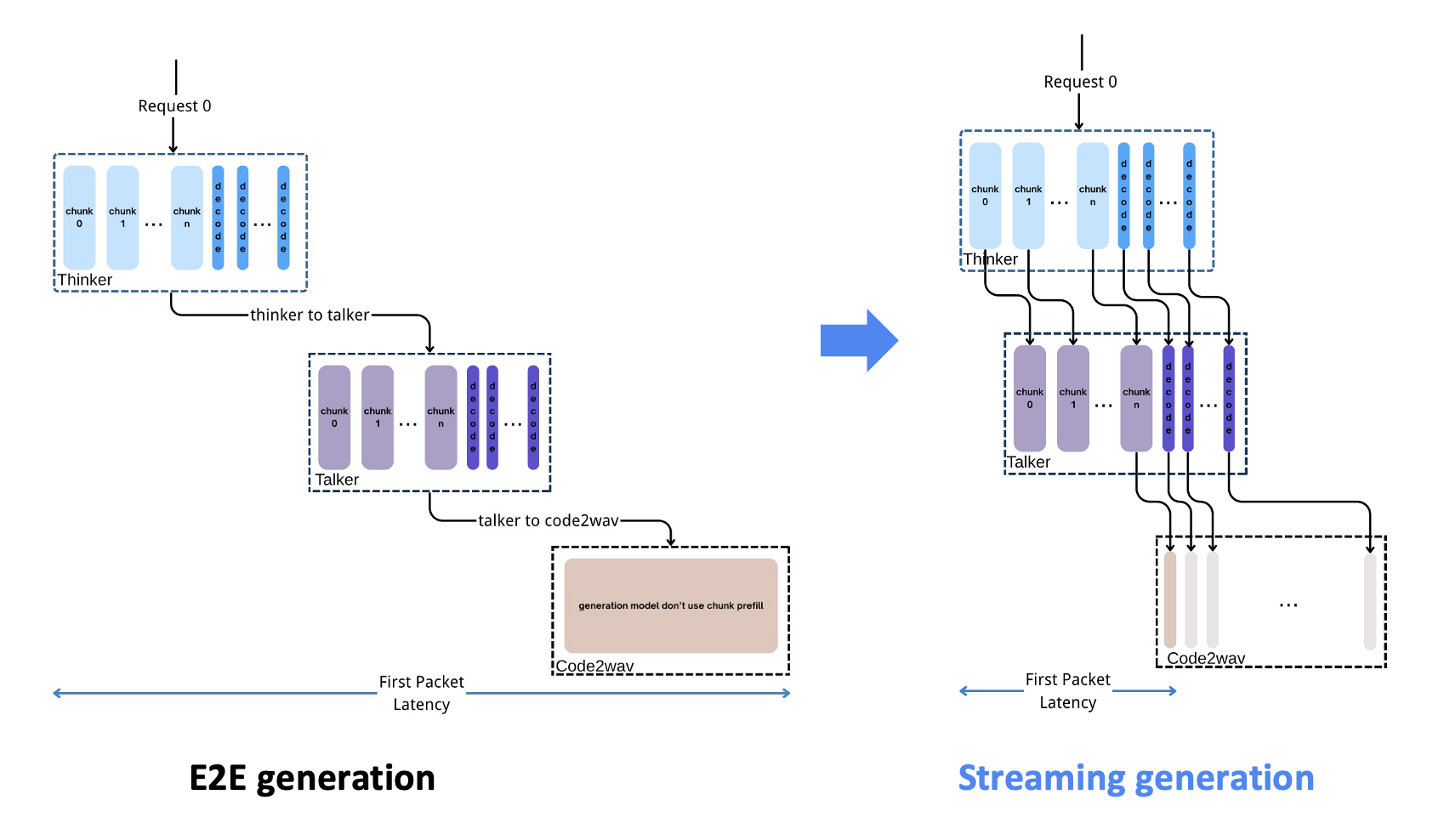
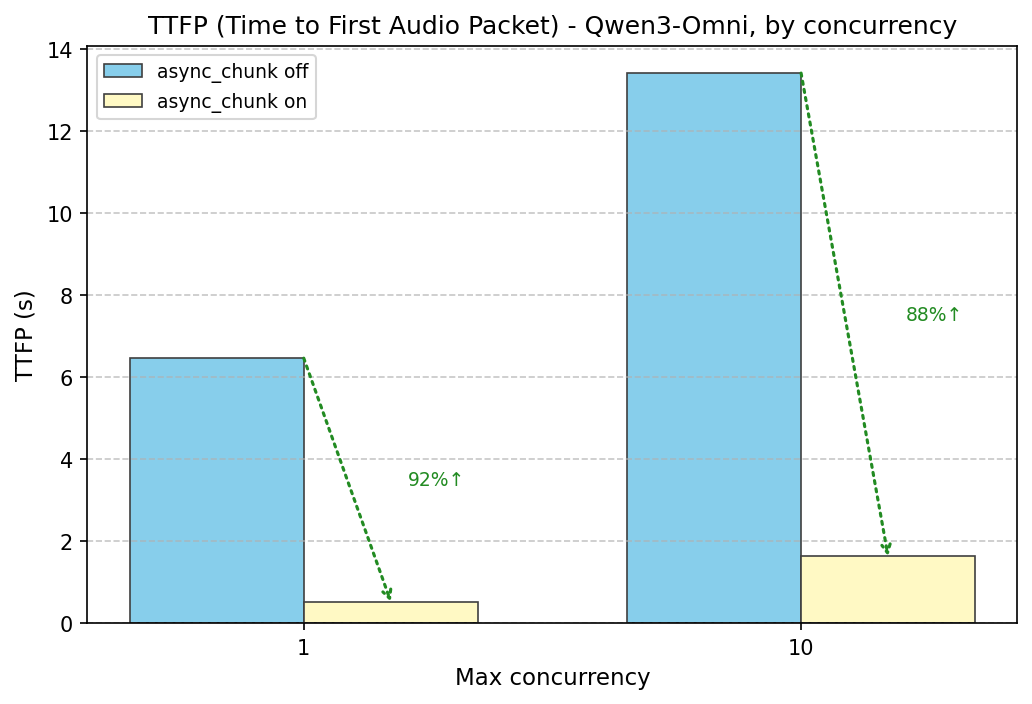
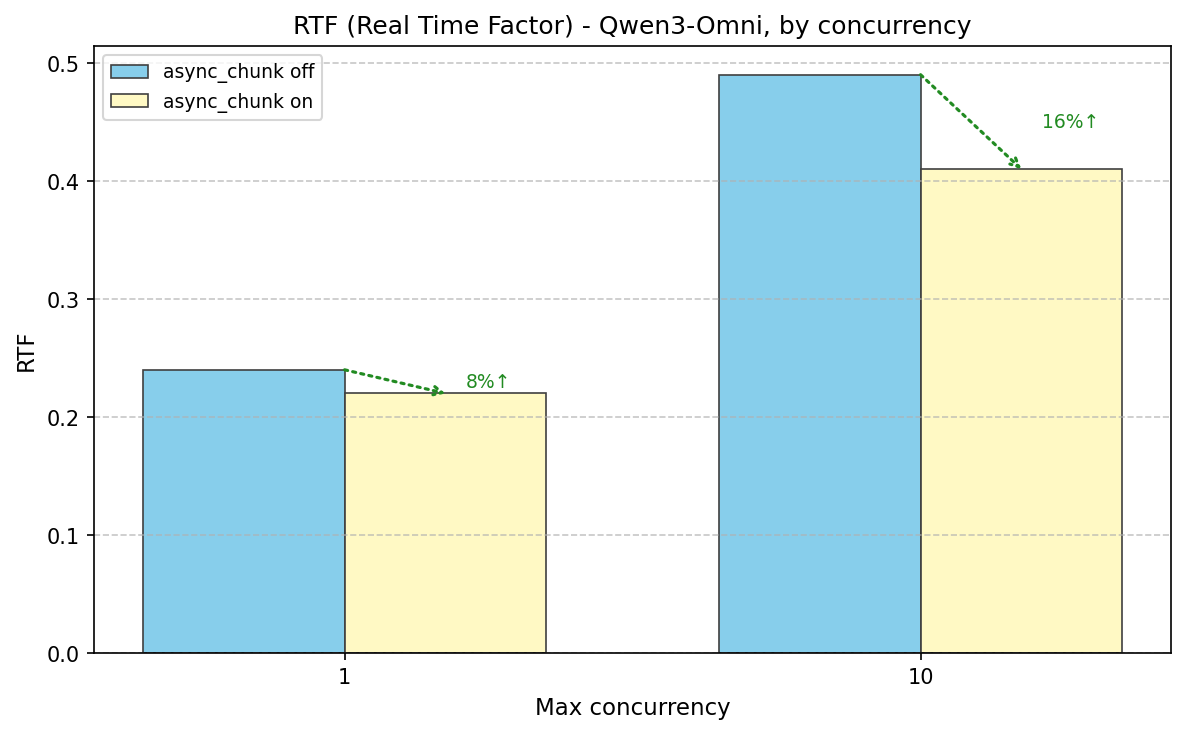
4.4. async chunk transfer & streaming ouput
use Qwen3-Omni as an example
navie solution: e2e sync genration
- encode text/image/video/audio
- pass embedding to Thinker, and do AR to decode all tokens
- pass all tokens to Talker, which then generate tokens as the input of Code2wav
vLLM-Omni: async chunk transfer & streaming ouput
- Pipeline Between Stages: Asynchronous chunked computation and communication across stages
- Audio Streaming Output: The waveform is output immediately after Talker generates each token.
Implementation details
- OmniConnector: Transmit data between stages.
- OmniChunkTransferAdapter: Chunk-specific implementation that owns the full chunk lifecycle when async_chunk is enabled.
- Stage Input Processors: Custom functions that process stage outputs into chunks for different models.
- Schedulers: Modified to handle chunk-based scheduling with async IO-compute overlap.
- Model Runners: Handle chunk processing.
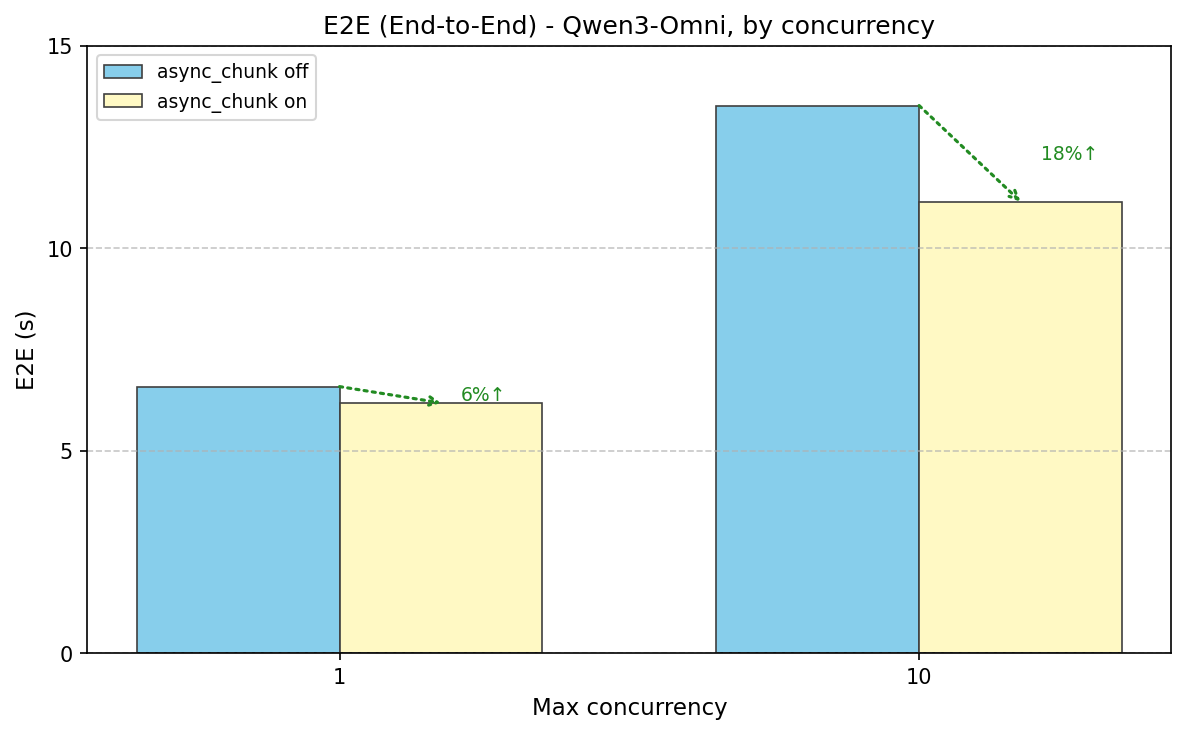
speedup
6. Diffusion module design
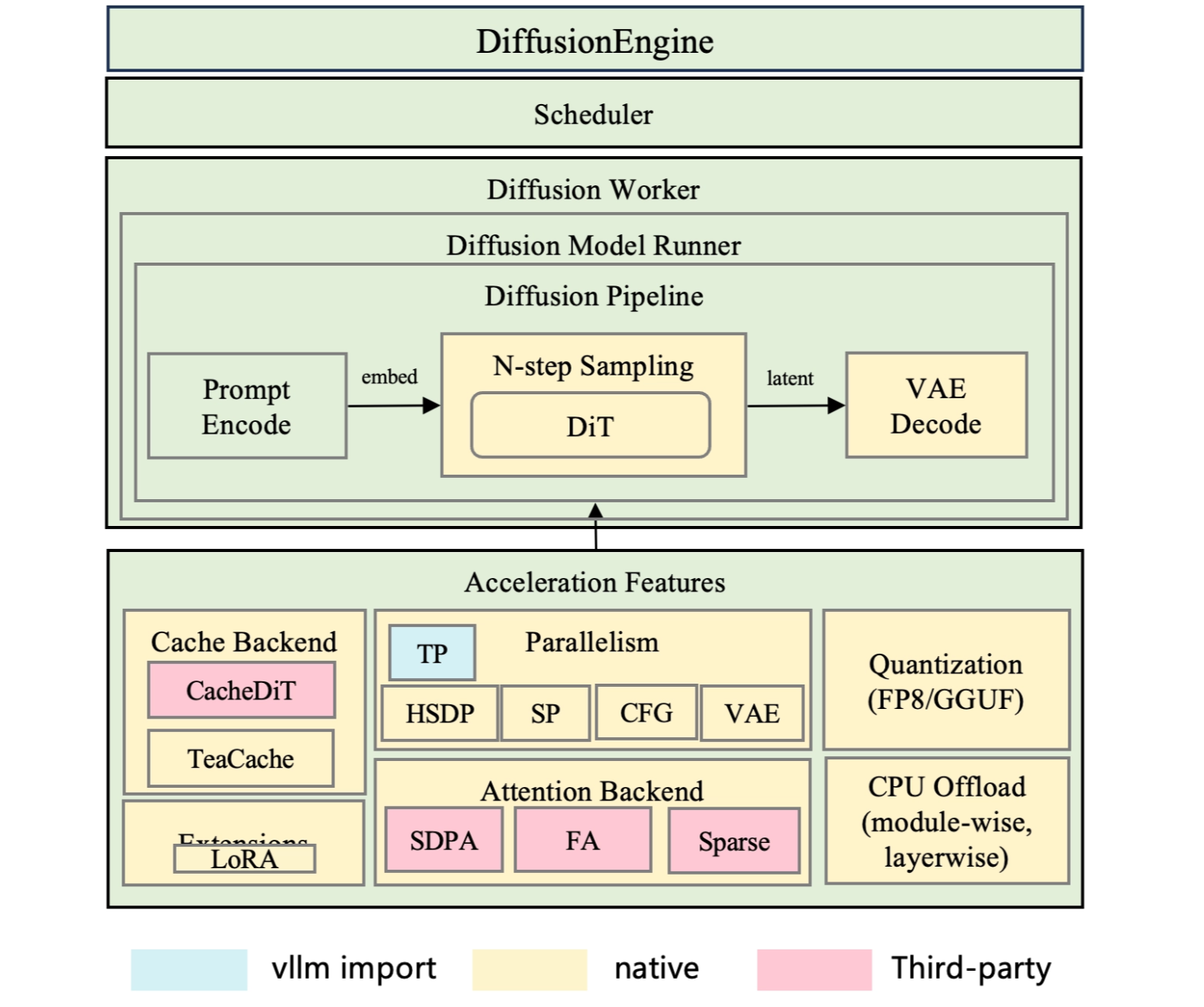
6.1 Diffusion Core
- Support step-wise scheduler with continuous batch for higher SLA
- 2026 Q2 roadmap: support continous batching
- Encoders are disaggregated to run on vllm engine
- Connect with AR module to speed up AR+DIT model inference with OmniConnector
6.2 Acceleration Features
- Parallelism: HSDP/SP/VAE/CFG/TP (explained in the next section)
- Quantization: FP8/GGUF…
- case-by-case modification to model code; need intensive abaltion studies
- CPU Offload:
- many diffsuion models are deployed on PC, so this feature is important
- module-wise: modules are loaded and evicted on the fly
- layer-wise: prefecth serveral layers’ weights
- Attention: interface abstraction for third-party integration(FA/SAGE/MindIE-SD…)
- Cache backend: Cache-DiT, TeaCache (explained blow)
- Extensions: LoRA
7. Cache
- Main techniques: TeaCache & Cache-DiT
- both tackle the sequential bottleneck of DiTs by reusing intermediate computations across timesteps
- TeaCache is a simpler, coarser in-house solution: skip all transformer blocks if the step looks similar enough
- Cache-DiT is a more powerful external library with fine-grained per-block control and multiple caching strategies, but it requires less boilerplate for standard models
TeaCache
- assumption: diff between consecutive timestep embeddings is a highly accurate proxy for diff in the model’s actual outputs
- cache entire transformer blocks computations when consecutive timesteps produce similar inputs
- core mechanism
- measures L1 distance between consecutive modulated inputs (after norm + timestep conditioning)
- if below threshold, reuses the previous step’s cached residual instead of running expensive forward pass
- Implemented via a hook that intercepts the transformer’s forward pass — zero changes to model code required
Cache-DiT
- an external library (
cache-dit) integrated into vllm-omni that caches intermediate block-level features across denoising steps - caches intermediate computation results across denoising steps.
- core insight: adjacent denoising steps often produce similar intermediate features, so we can skip redundant computations by reusing cached results
supports three strategies
- DBCache: dynamic block-level caching that selectively computes or caches transformer blocks based on residual differences between steps
- TaylorSeer: calibration-based prediction using Taylor expansion to estimate block outputs
- SCM (Step Computation Masking): dynamic step skipping based on configurable policies
| Aspect | TeaCache | Cache-DiT |
|---|---|---|
| Decision unit | Whole transformer block stack (skip all or run all) | Individual transformer blocks (selective per-block) |
| Cache signal | L1 distance on modulated input of first block | Residual difference between block outputs |
| Mechanism | Hook intercepts forward pass; reuses cached residual | Library patches transformer modules in-place |
8. Parallelism
8.1 Tensor Parallel (TP)
- similar to LLM sharding model weights across GPUs
- dach GPU computes a fraction of every attention head and MLP output, then results are reduced via all-reduce
- cannot be combined with HSDP
8.2 Sequence Parallel (SP)
- splits the input sequence (image patches or video frames) across GPUs so each GPU processes only a portion of the tokens.
- Attention across the full sequence is handled via Ulysses (all-to-all) or Ring (peer-to-peer) communication
- Ulysses attention
- before each attention layer, GPUs do an all-to-all exchange so that each GPU temporarily holds all tokens for a subset of attention heads
- each GPU computes full-sequence attention for its head slice, then another all-to-all restores the original sequence split
- fast but requires the number of attention heads to be divisible by
ulysses_degree
- Ring attention
- GPUs are arranged in a logical ring
- each GPU holds its local sequence chunk and its own Q vectors
- KV chunks are passed around the ring one step at a time
- each GPU accumulates attention scores incrementally as KV chunks arrive
- no divisibility constraint on heads, but adds latency proportional to ring size
8.3 HSDP (Hybrid Sharded Data Parallel)
- shards model weights across GPUs using PyTorch FSDP2, gathering them on-demand during the forward pass.
- Cannot be combined with TP
8.4 VAE Parallel
- VAE is the final stage that converts the denoised latent tensor into pixel-space images or video frames.
- splits the VAE decoding step across GPUs
- the latent tensor is tiled into spatial patches; each GPU decodes its assigned tiles in parallel
- tiles overlap slightly and are blended at the boundaries to avoid seams
- reduces peak memory and decoding latency, especially for high-resolution or video outputs
8.5 CFG Parallel
Distributes the two forward passes required by Classifier-Free Guidance (CFG) across GPUs so they run simultaneously.
- CFG is a standard technique for steering image generation
- the model runs once with your text prompt (conditional)
- and once without (unconditional)
- the outputs are blended to improve quality
- w/o CFG Parallel, these two passes are sequential; CFG Parallel assigns each pass to a different GPU rank, halving the per-step latency
- Results are gathered via all-gather; all ranks then compute the CFG combination locally
8.6 how to select parallelisms?
- Model too large to fit in a single GPU?
- TP / HSDP
- Sequence too long causing OOM?
- Ulysses-SP / Ring Attention
- CFG inference too slow?
- CFG-Parallel: this is the most stable method
- VAE decoding memory explosion?
- VAE Patch Parallelism
9. 2026 Q2 roadmap
- Support world model & VLA model
- Support streaming input (audio, text, video): required by World models
- Support RL for multi-stage model