Intro to PPO in RL
1. From Rewards to Optimization
- In RL, an agent interacts with an environment by observing a state
, taking an action , and receiving a reward . - In the context of LLM, state is the previous tokens, while action is the next token to generate.
- The agent’s goal is to learn a policy (
), which is a probability distribution over actions, that maximizes its long-term expected return. - In the context of LLM, policy is determined by model weights.
Formally, the objective function is:
where
are the model weights, is a discount factor weighting future rewards.
In other words,
This objective was first formalized in REINFORCE (Williams, 1992) and forms the basis of all policy-gradient methods.
2. The Policy Gradient Theorem
To maximize
Here,
: expected return after taking action in state . : expected return following the policy from state .
Using
3. The Instability Problem
Naive policy-gradient methods (like REINFORCE) update parameters directly using samples from the current policy.
But each update can drastically change the policy distribution
To address this, Trust Region Policy Optimization (TRPO) introduced a constraint to keep the new policy close to the old one by bounding their KL divergence.
However, TRPO is computationally expensive. It requires second-order optimization.
4. PPO: Proximal Policy Optimization
PPO (Schulman et al., 2017, OpenAI) simplifies TRPO by directly penalizing or clipping updates that move too far from the previous policy.
Let
be the probability ratio between the new and old policies.
PPO defines a clipped surrogate objective:
where
- If
, we want : increase the probability of good actions. - If
, we want : decrease the probability of bad actions. - The clipping prevents overly aggressive updates.
This makes PPO simple to implement, stable to train, and robust across diverse tasks.
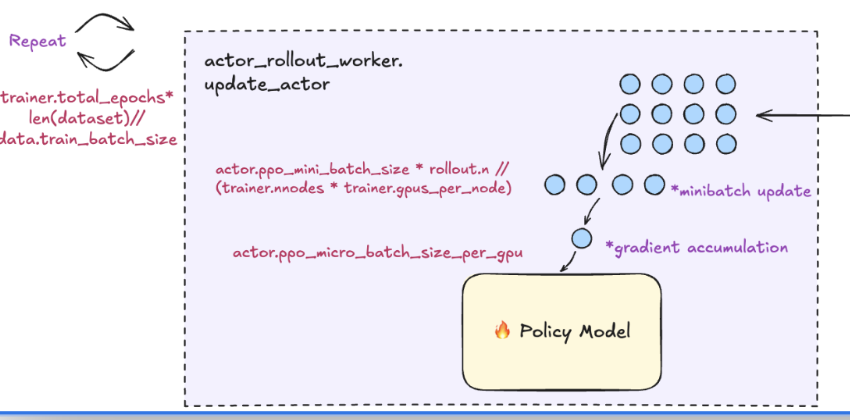
5. PPO workflow
Image source: TIS & FlashRL - 1022@H2Lab
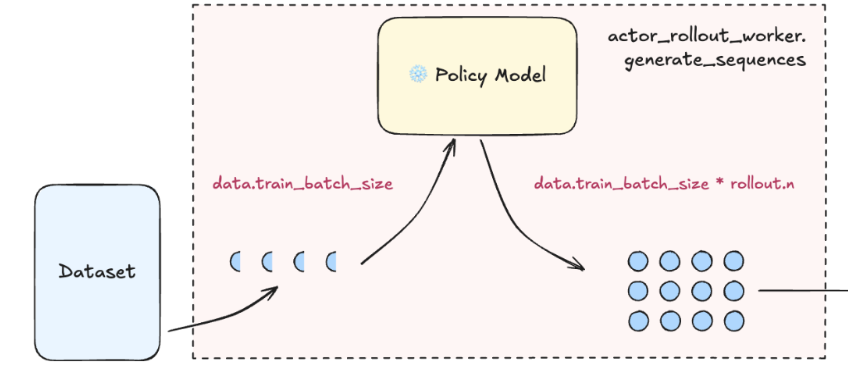
- Generate sequences (trajectories) with the policy model (current LLM weights) for each prompt in the batch.
- Trajectory:
. That is, starting from an initial state, LLM takes actions (i.e., generates tokens) step by step, receives rewards , and transitions through different states (resulting responses), forming one complete episode of experience.
- Trajectory:
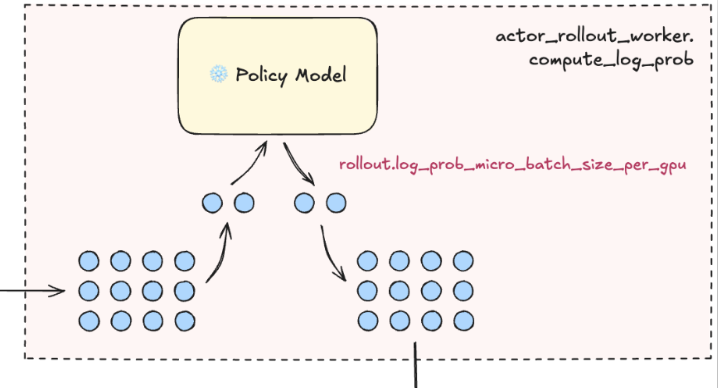
- Compute log probs
from the policy model for all tokens in the generated responses.
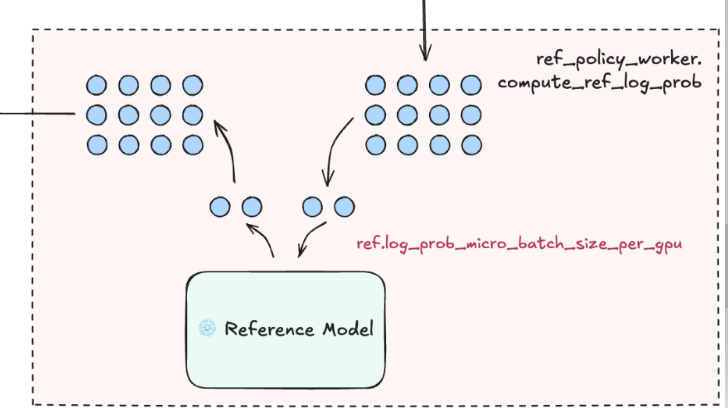
- Compute log probs from the reference model
- Reference model: a frozen copy of the initial SFT, which is the baseline that doesn’t change during PPO training.
- It’s used to stabilize training and prevent the policy model from drifting too far away from the original behavior.
- Specifically, PPO uses the KL-divergence between the policy and the reference. This acts as a regularization term.
- Reference model: a frozen copy of the initial SFT, which is the baseline that doesn’t change during PPO training.
- Compute the gradient and update weights of the policy model