Pytorch Conference & Ray Summit 2025 summary
1. Overall
Many inference talks, but more RL talks.
RL
- RL101
- 3 RL challenges: training collapses, training slow, hardware errors
- New frameworks / API: Tinker, SkyRL, Slime, SGLang’s Slime-based framework
- and the old framework VeRL: MPMD vs SPMD; RL pipeline
- Cursor RL, Kimi K2 thinking RL
- Specialized models
- One base model + multiple fine-tuned models (e.g., tool use models)
- GPT5 smart router
- vLLM semantic router
Inference
- Elastic EP
- AIbrix: Prefix-aware routing, load-aware routing; router vs engine KV indexing
- Spotify with vLLM on TPU
- MoE: dp, tp, pp, sq, token-parallel, cp
- Checkpoint hot-swap
Pytorch update
- edge device, RL, distributed engine, kernel DSL, communication, simple FSDP
2. RL
2.1 RL 101
Agentic RL: Policy LLM → rollout → reward → advantage → policy update
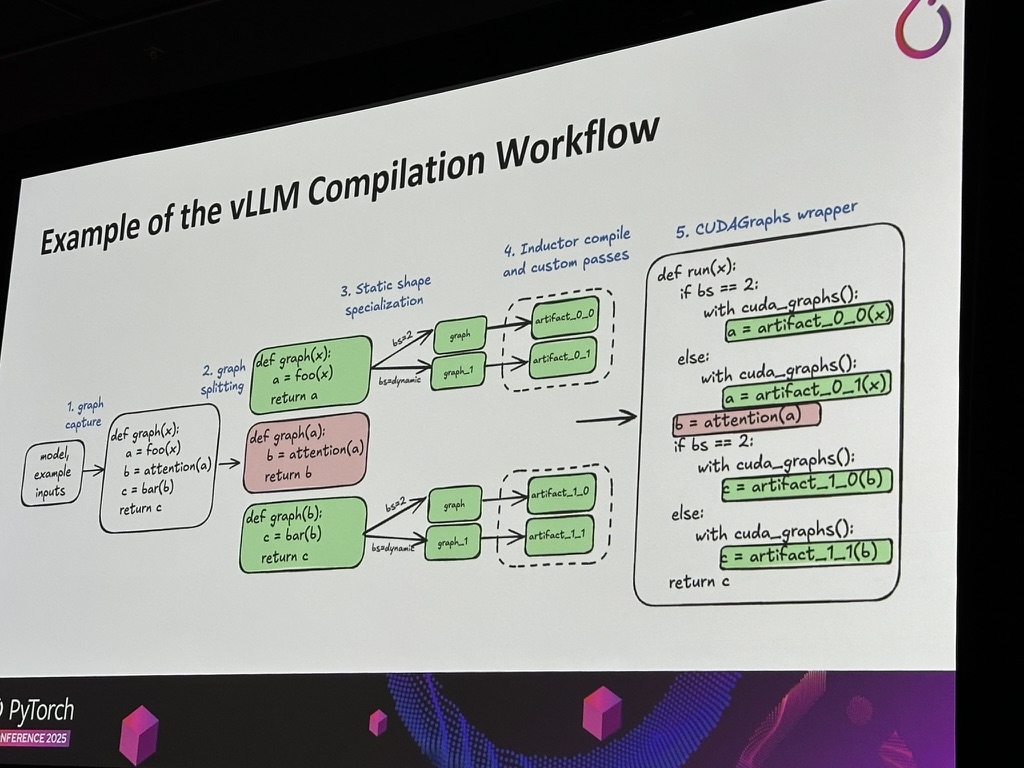
2.2 RL challenges
- Training collapses
- training-rollout mismatch
- solution: importance sampling, swithcing from BF16 to FP16
- reward unavailable
- hardware errors
- training-rollout mismatch
- Training slow
- sync between trainer and sampler is hard and inefficient. for example
- when trainer and sampler are decoupled in different chips, there is huge compute waste since samplers are idle when trainer is working, and vice versa
- when they are colocated, weight hot-swap is slow
- rollout slow
- long tail latency issue (due to long trajactory)
- frequent timeouts, rate limits, and job hanging during distributed env
- cost explosion: long-context, multi-agent simulation
- sync between trainer and sampler is hard and inefficient. for example
- Hardware errors / tiny bugs
- With large scale, there constant GPU failures, which take tons of engineering efforts to fix
- xAI post training scale has been same as pretrain and SFT
- Each NVIIDIA GPU generation has quite different sets of hardware errors
- Tiny bugs in rollout, logprob, or reward shaping. silent GPU error.
- With large scale, there constant GPU failures, which take tons of engineering efforts to fix
2.3 Frameworks / APIs
2.3.1 Tinker
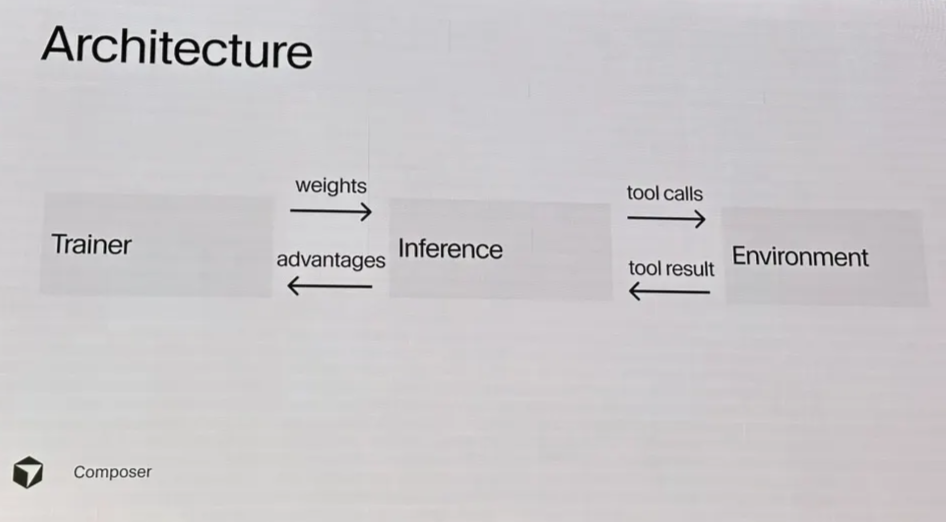
Tinker is in the middle

What does black box API refer to?

What is Tinker API?

Billing: charged by tokens (how to deal with different reward types???)
- for most of them, Train price = Sample price; for some of them, Train price is a bit higher

comparasion: Gemini 2.5 serving cost
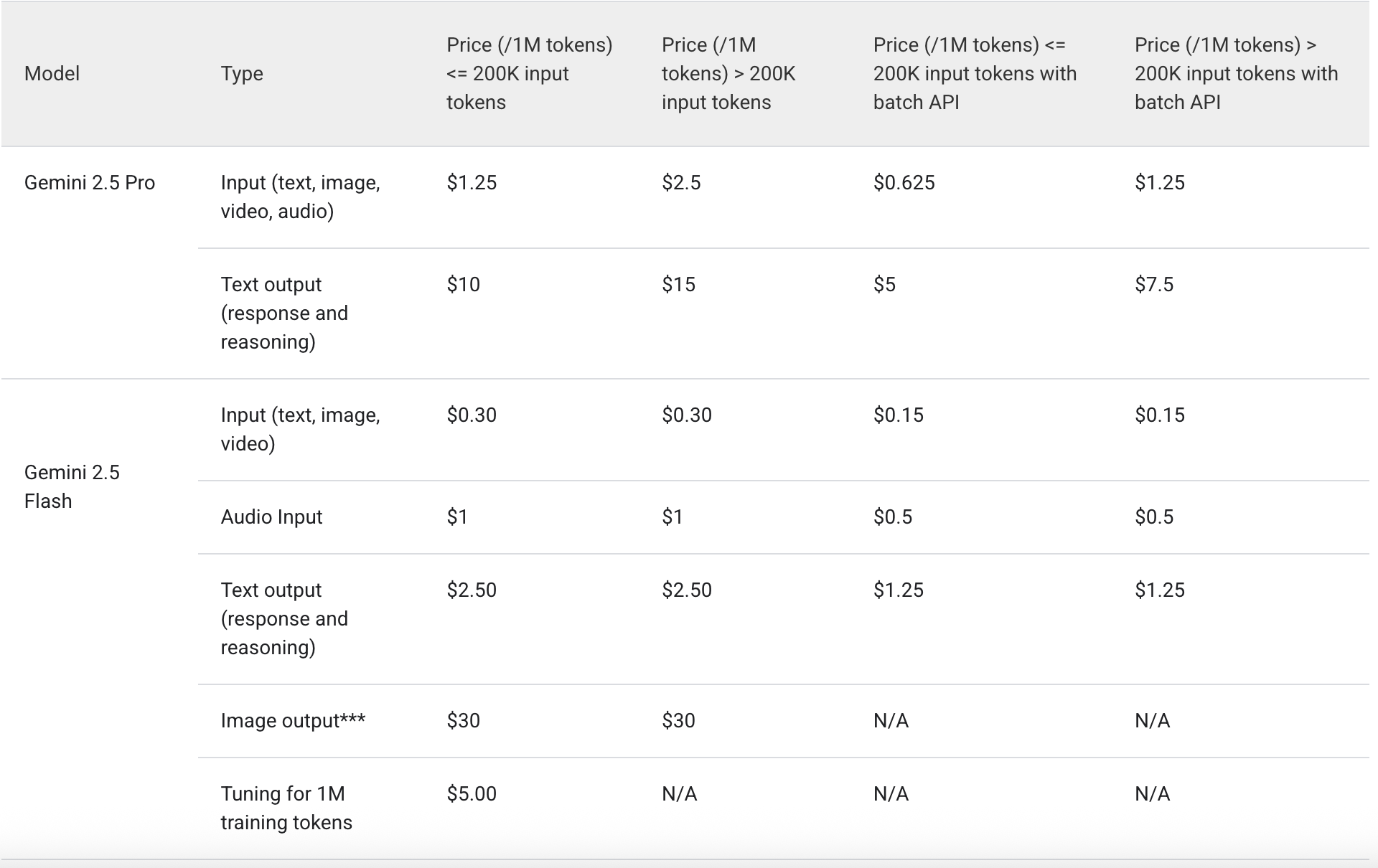
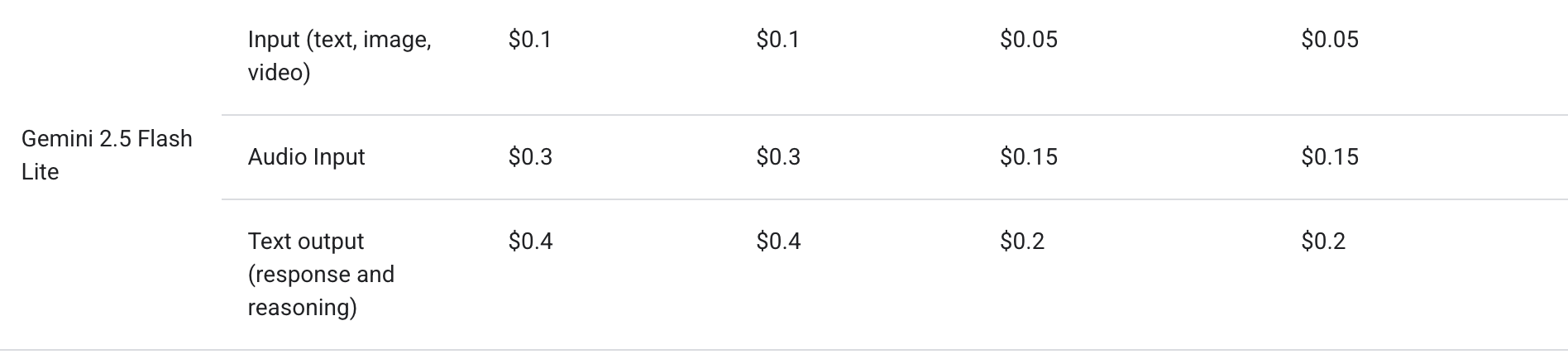
Looks like it’s LoRA at this point.


2.3.2 SkyRL
Different RL need different stacks
- RLHF (single-turn, no tools): short context, short rollouts. training dominates; simple to colocate.
- Reasoning (single-turn w/ long context): inference dominates
- Agents (multi-turn, tools, env interactions): long contexts, multiple env interactions, system requirements different across components; need new stack
SkyRL architecture
- Controller: Manages training control flow, algorithm definitions, component placement & scaling, and resource spin-up/tear-down.
- Trainer:
- Megatron / FSDP support
- LoRA, MoE, multi-node parallelism.
- Can be colocated with or decoupled from inference workers
- Generator:
- vLLM, SGLang
- the most customized part
- SkyRL-Gym env
- SkyRL-Agent:
- Manages trajectory generation for agentic tasks
- Supports running generation across different training backends and execution environments (e.g., async VM pools).
2.3.3 Slime & SGLang’s Slime-based RL framework
Slime: created by Tsinghua University and Alibaba Ant
https://github.com/THUDM/slime
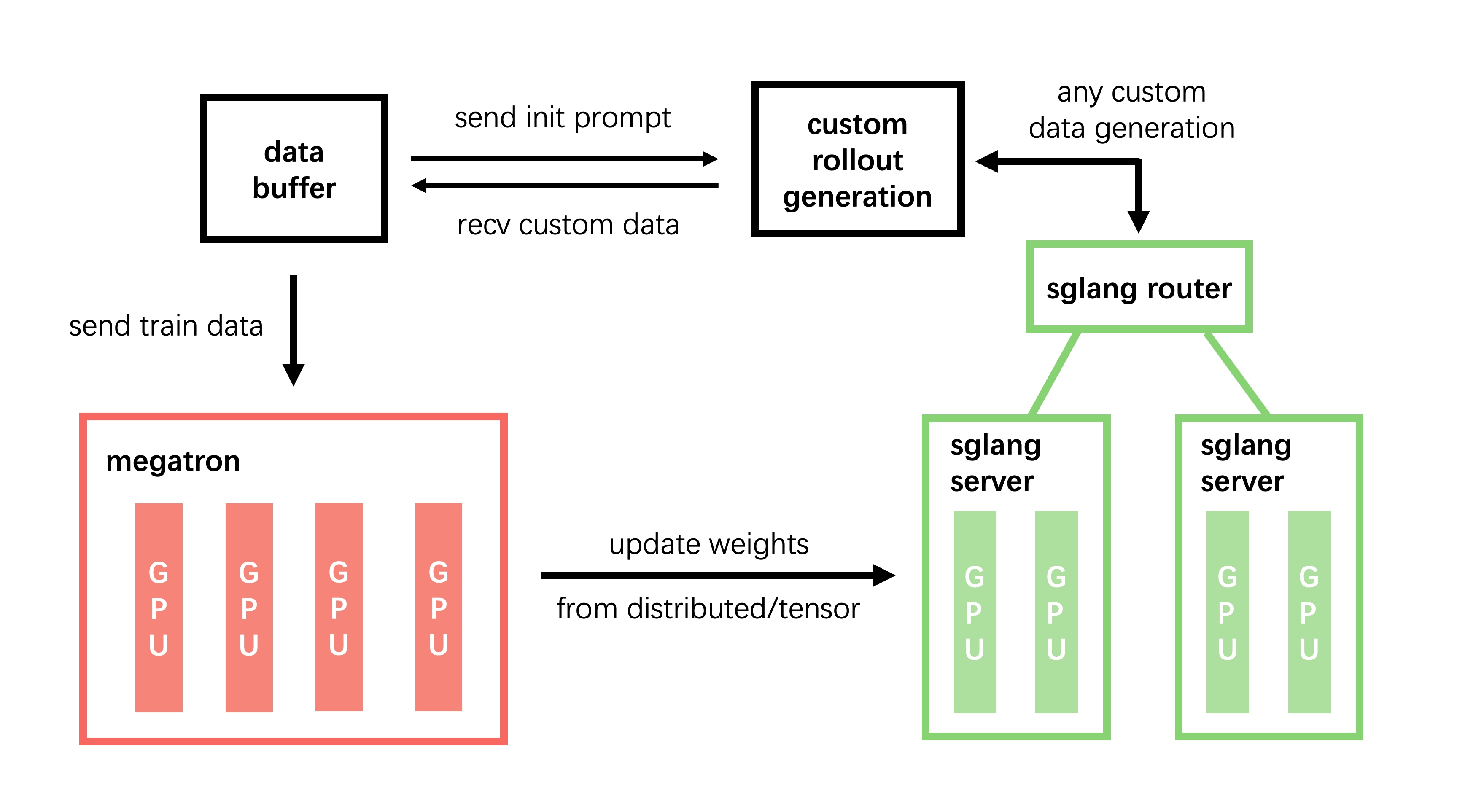
SGLang’s new product: add features like fault tolerance based on Slime

Multi-turn RL specifics & complexities
- Agent loop complexity: generation → decide tool call → call tool → process tool output → continue
- long-tail effect
- profiling is hard:multi-component pipeline (inference, tool, env, verifier, storage) is hard to monitor and analyze
Training–inference mismatch
- Inference logprobs ≠ training logprobs
- non-associative FP arithmetic
- kernel nondeterminism with different batch sizes
- MoE-specific activation differences: expert routing biases
Solutions
- batch-invariant kernels
- re-shard MoE for co-located placement; recude routing differences
- truncated importance sampling
2.4 Scaling RL @ Cursor
https://cursor.com/blog/tab-rl
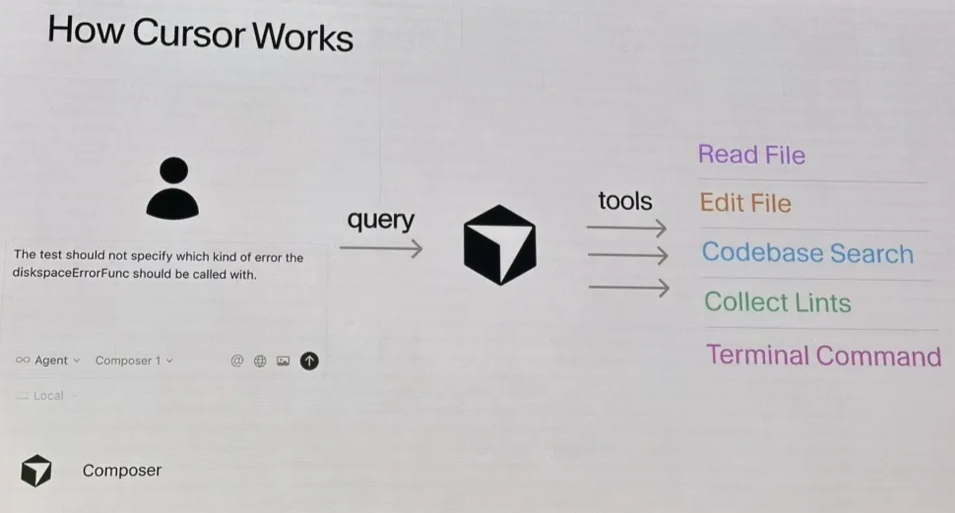

Env consistency is important


Controller

What do we learn?

2.5 verl
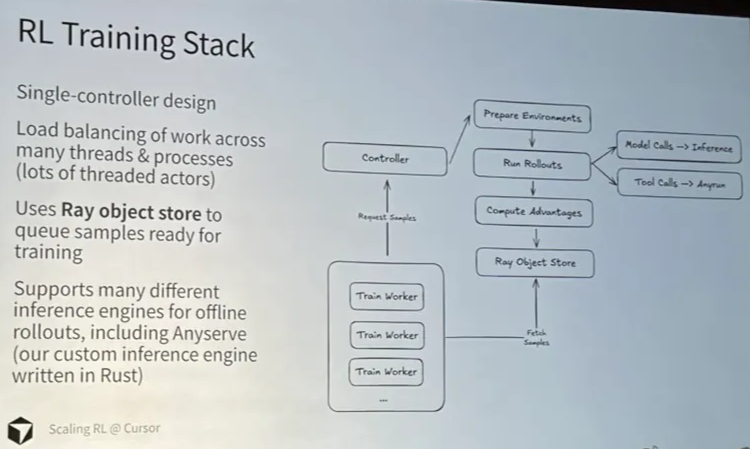
RL is a multi-model, multi-workload pipeline
RL: complex distributed dataflow graph
- multi-model: policy model, reward model, reference model (constrains the policy’s KL divergence), value model (long-term return)
- mumulti-workload: generation, inference, training, and weight sync
- single-controller
- each worker running different programs
- simple; ideal for rapid experiments
- multi-controller
- each worker has its own controller
- fits naturally with distributed backends like FSDP / Megatron
- better performance
- hybrid-controller
- a central controller for high-level RL logic
- multiple controllers for distributed execution
2.6 Other RL topics
Kimi K2 thinking
similar to DeepSeek ****R1, differences:
- recuded number of attention heads: R1 = 128,K2 = 64
- increased number of experts: 256 → 384
- R1 first 3 layers are FFN. K2 only the 1st layer is FFN. more aggressive MoEs
Specialized models
- One base model + multiple fine-tuned models (e.g., tool use models)
- GPT5 smart router
- vLLM semantic router https://github.com/vllm-project/semantic-router:
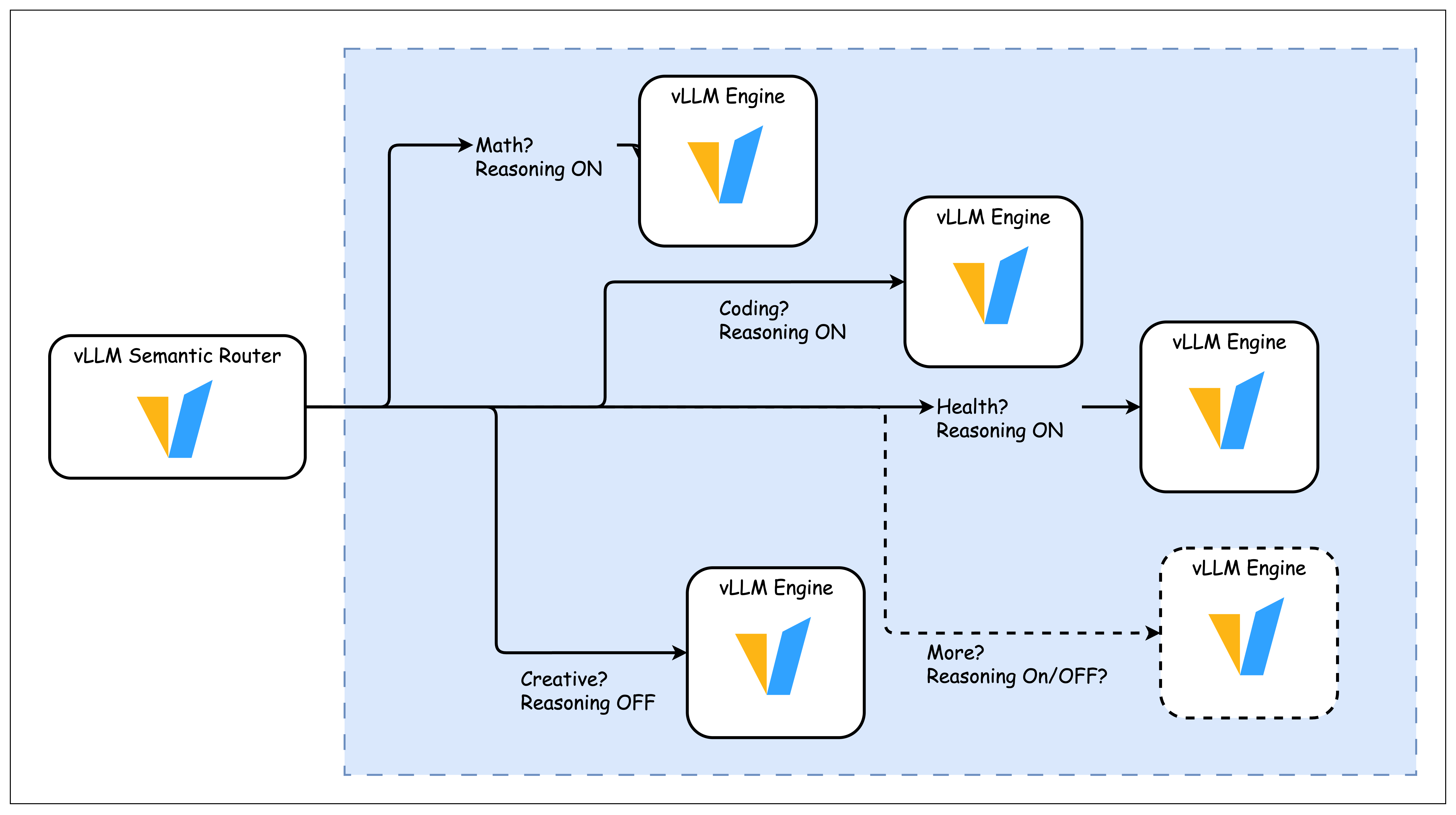
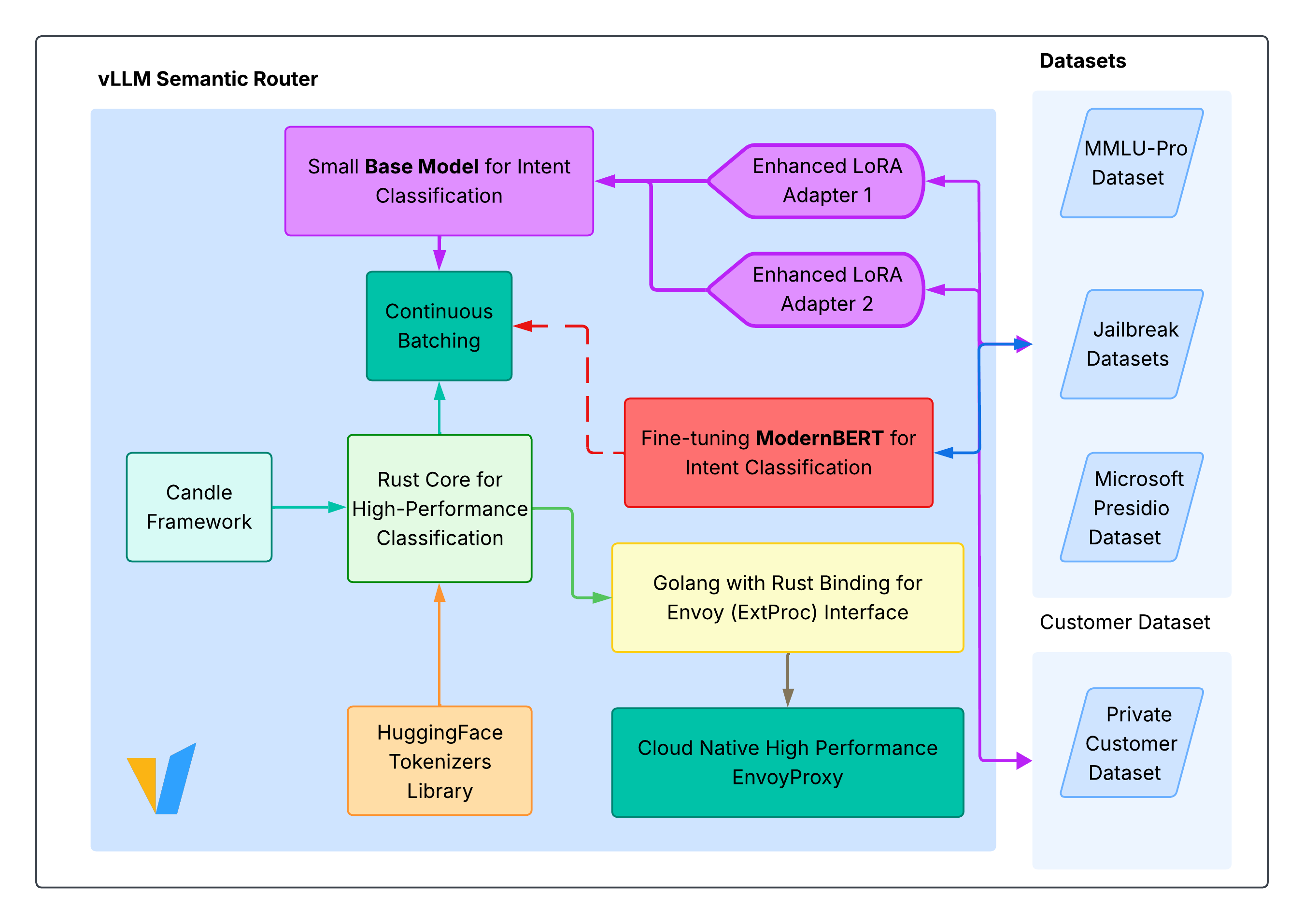
3. Inference
3.1 Elastic EP
Elastic Expert Parallelism (EEP) — Fine-Grained Scaling


Elastic EP introduces expert-group-level elasticity, allowing the system to:
- Scale up/down adaptively with online traffic.
- Recover gracefully from GPU faults.
- Optimize cost efficiency through partial rescaling.
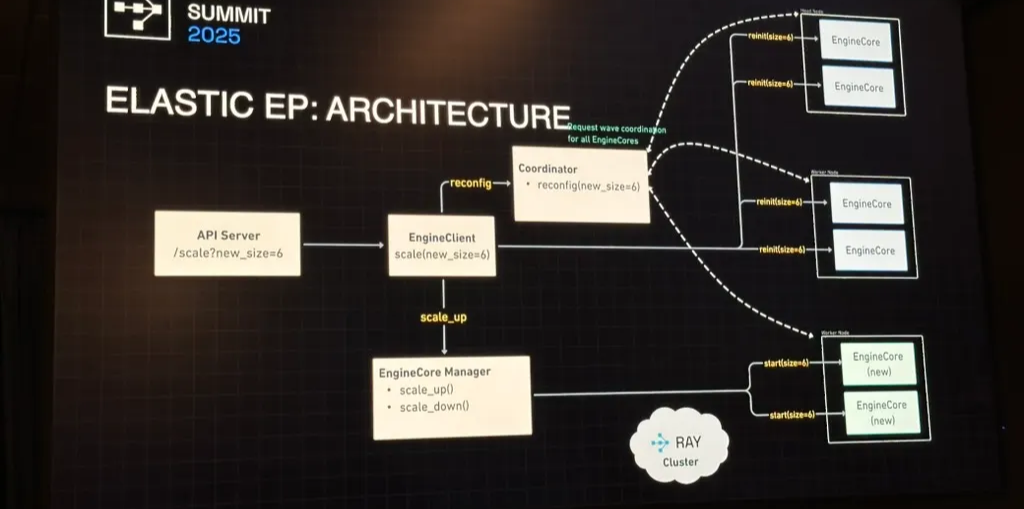
Ray-based orchestration is key:
- Each EngineCore represents a parallelized expert block.
- The Coordinator manages data-parallel communicators and distributed GPU workers.
- Scaling commands (scale up/down) trigger reinitialization of EP communicators, weight resharding, and CUDA graph recapturing.

EPLB
- Transfers weights peer-to-peer instead of from disk, reducing recovery latency.
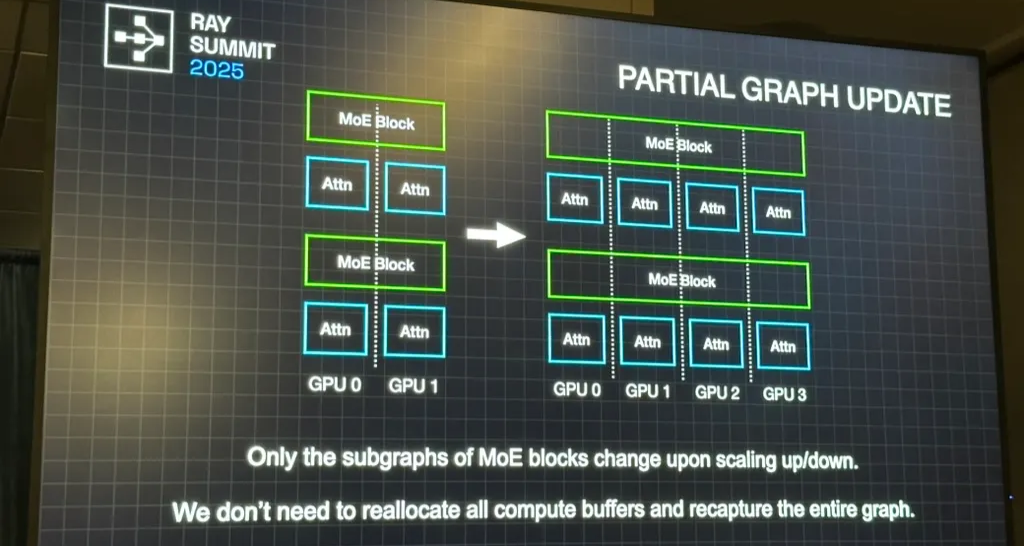
- CUDA graphs are recaptured incrementally, only for the modified subgraphs of MoE blocks.

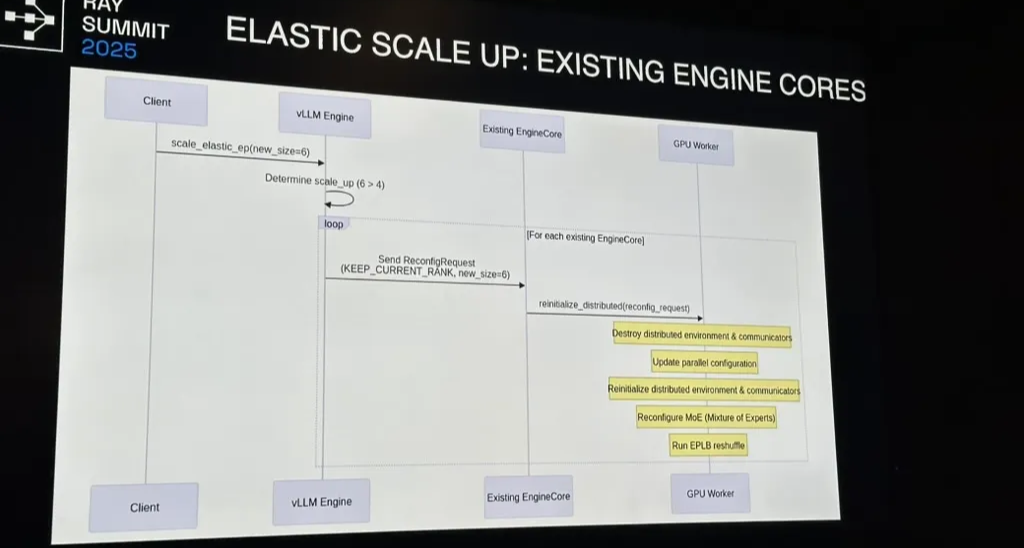
We don’t need to reallocate all compute buffers or recapture the entire CUDA graph — only the modified subgraphs.




3.2 AIBrix
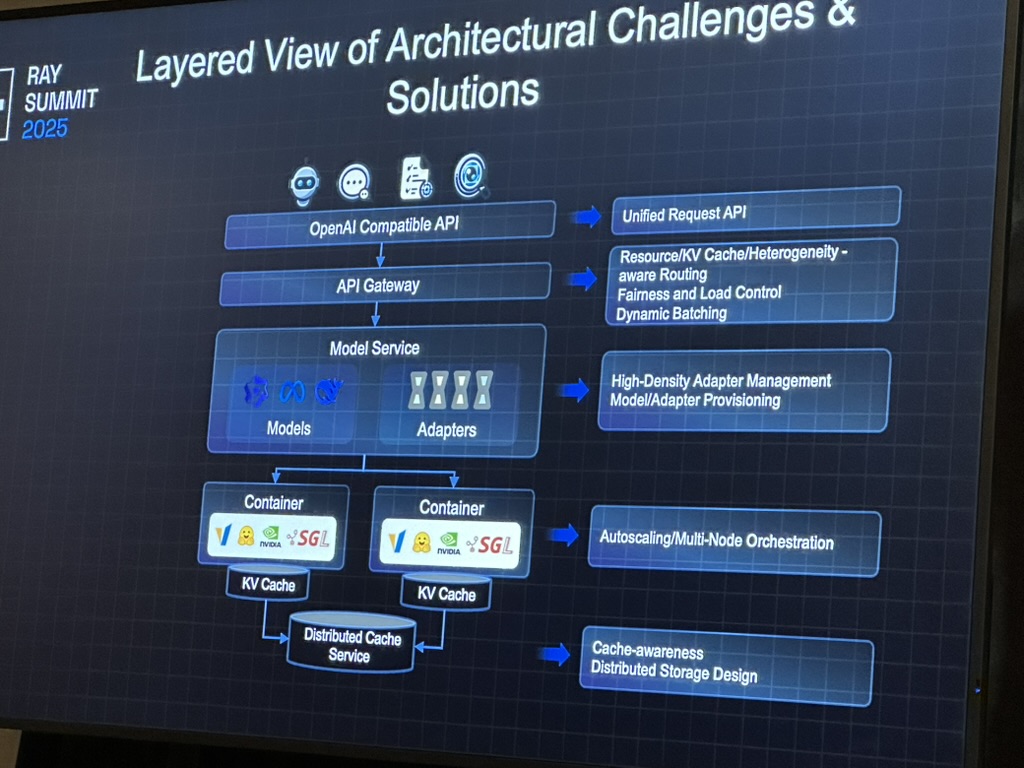

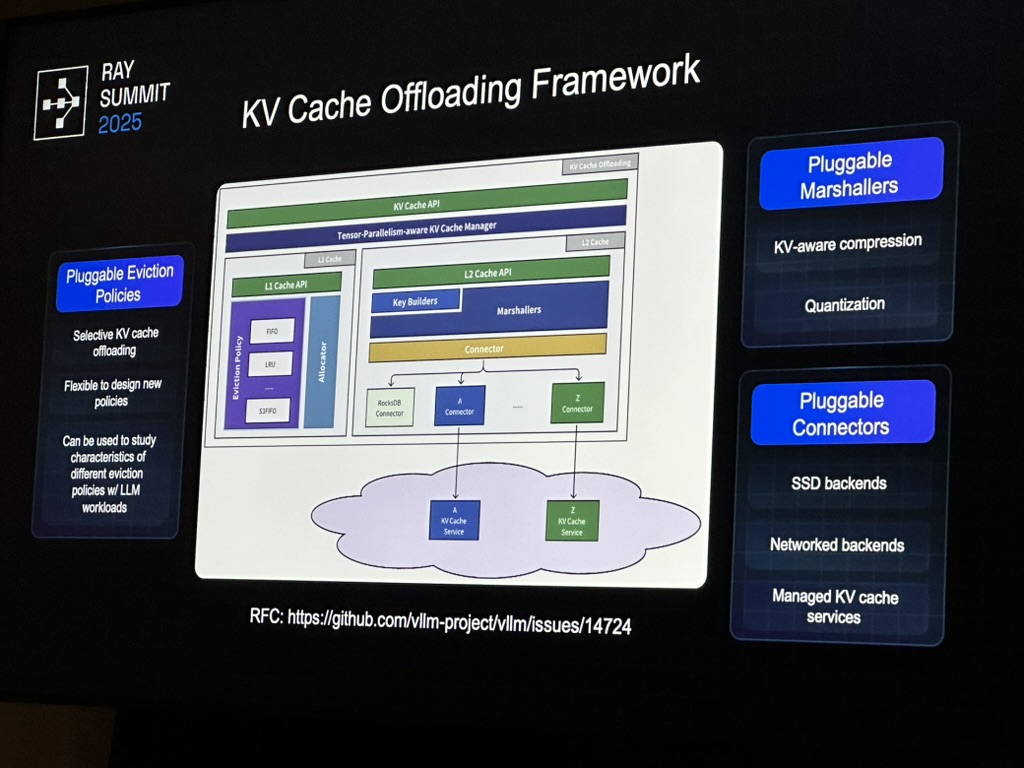
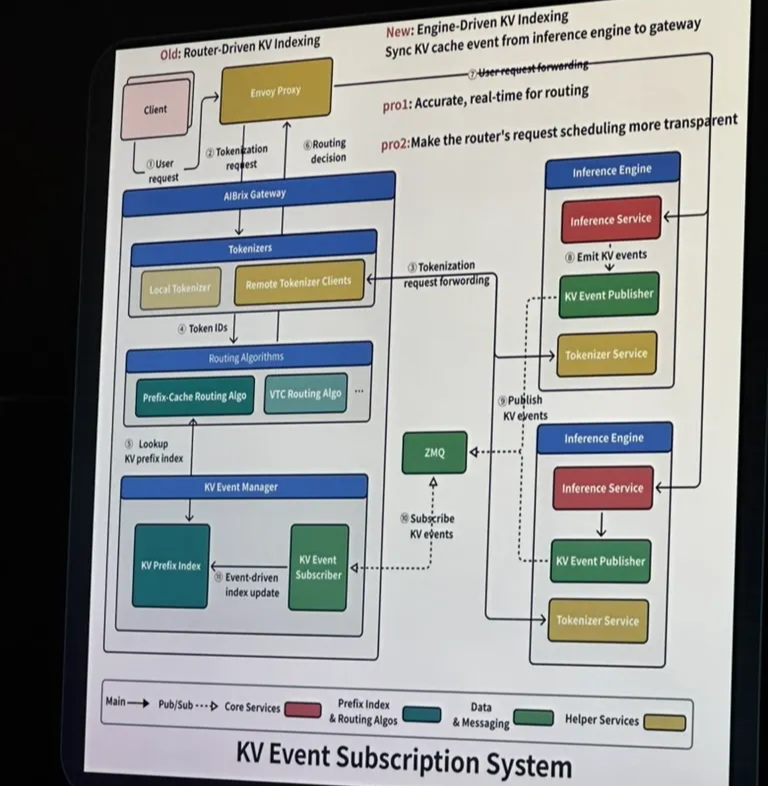
Router-driven vs engine-driven KV indexing
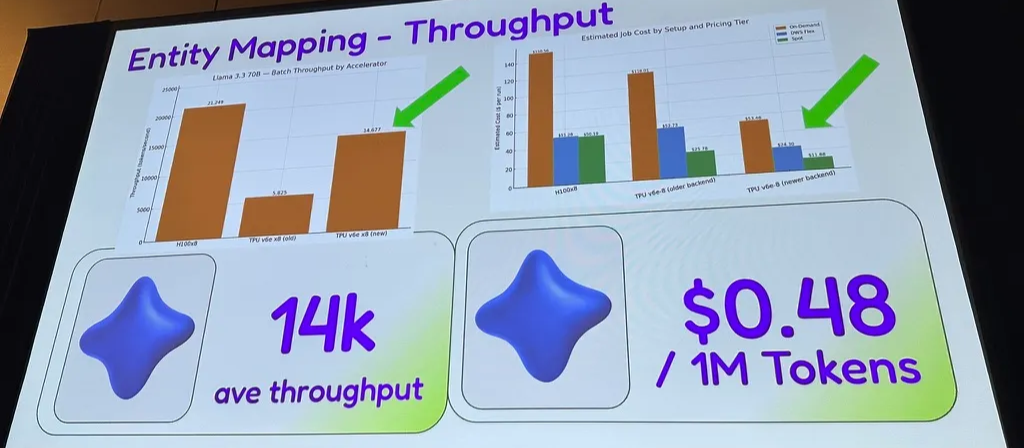
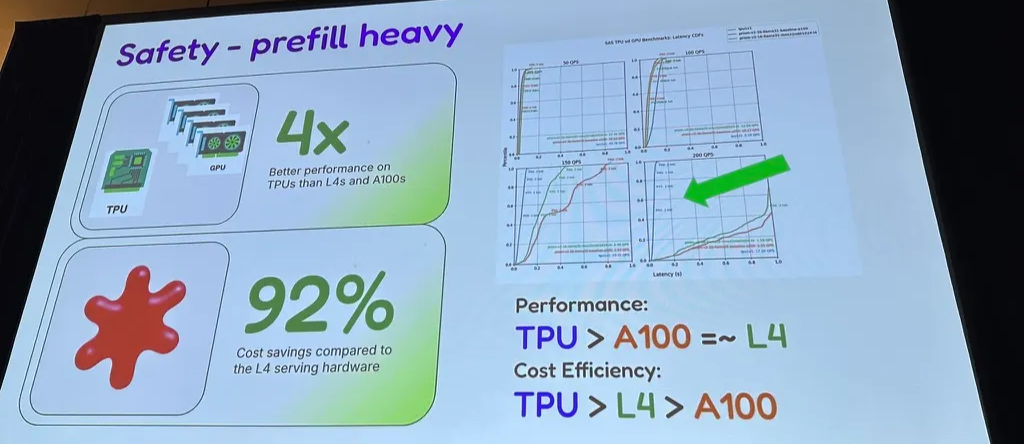
3.3 Spotify with vLLM on TPU
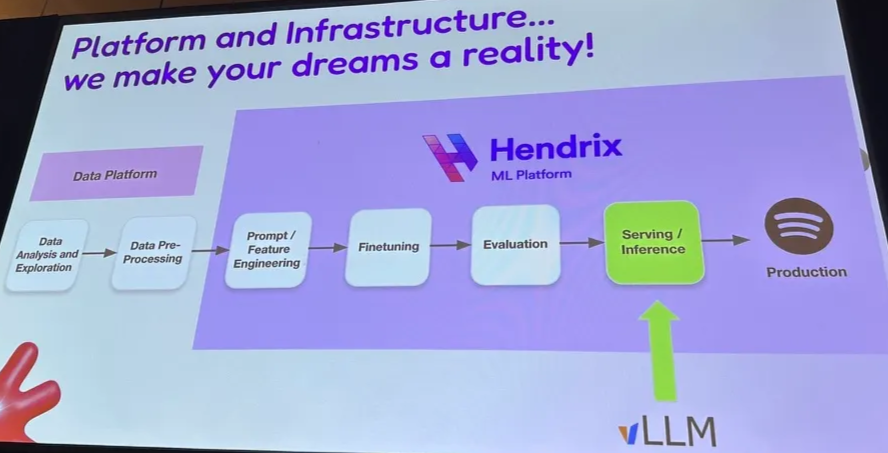
Workloads
- entity mapping accross medium
- AI playlist
- AI DJ interaction
- Spotify safety



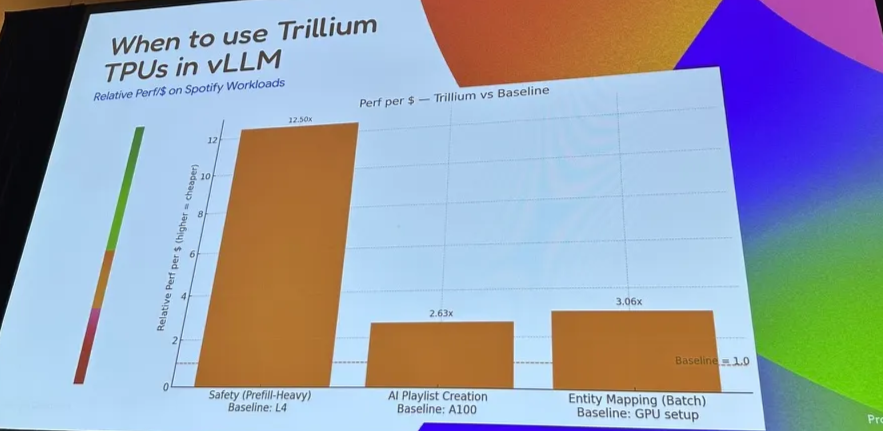
4. PyTorch updates



Monarch: Ray’s competitor


Inference