speculative decoding 02
Speaker: Lily Liu
- Working at OpenAI
- Graduated from UC Berkeley in early 2025
- vLLM speculative decoding TL
1. Why is LLM generation slow?
- GPU memory hierarchy. A100 example:
- SRAM is super fast (19 TB/s) but super small (20 MB)
- HBM: large (40 or 80 GB) but slower (1.5 TB/s)
- Main memory: very large but super slow

- a llama3-70B model with BF16 data type occupies 140 GB for its model weights
- the size is even too big to fit into HBM
- Suppose we can store the whole model in HBM. You still need to load model weights from HBM to SRAM
Auto-regressive token generation: one token is generated each time → it’s memory-bound (need to load model weights and KV cache without enough compute)
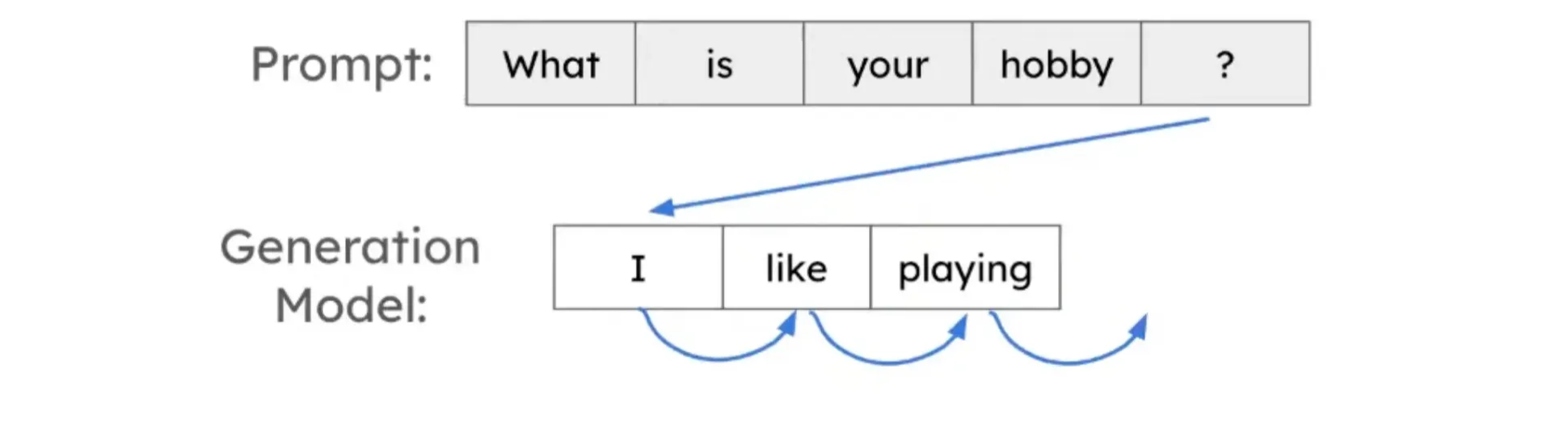
2. What is speculative decoding (SD)?
- Goal: reduce generation latency by amortizing bandwidth.
- The latency is critical to user experience
- The two main techniques to reduce inference latency: speculative decoding and sharding
- Sharding: partition LLM to multiple GPUs, which can do inference together
- Speculative decoding: kind of an algorithm-wise optimization, which does not need more hardware
- Intuition: Some tokens are easier to generate than others.
- Example:
- Prompt: What is your name?
- Response: My name is Lily
- There are some tokens that are easier to guess, for example, “is” in the response
- For easier tokens, maybe we don’t need a powerful LLM to generate
- Example:
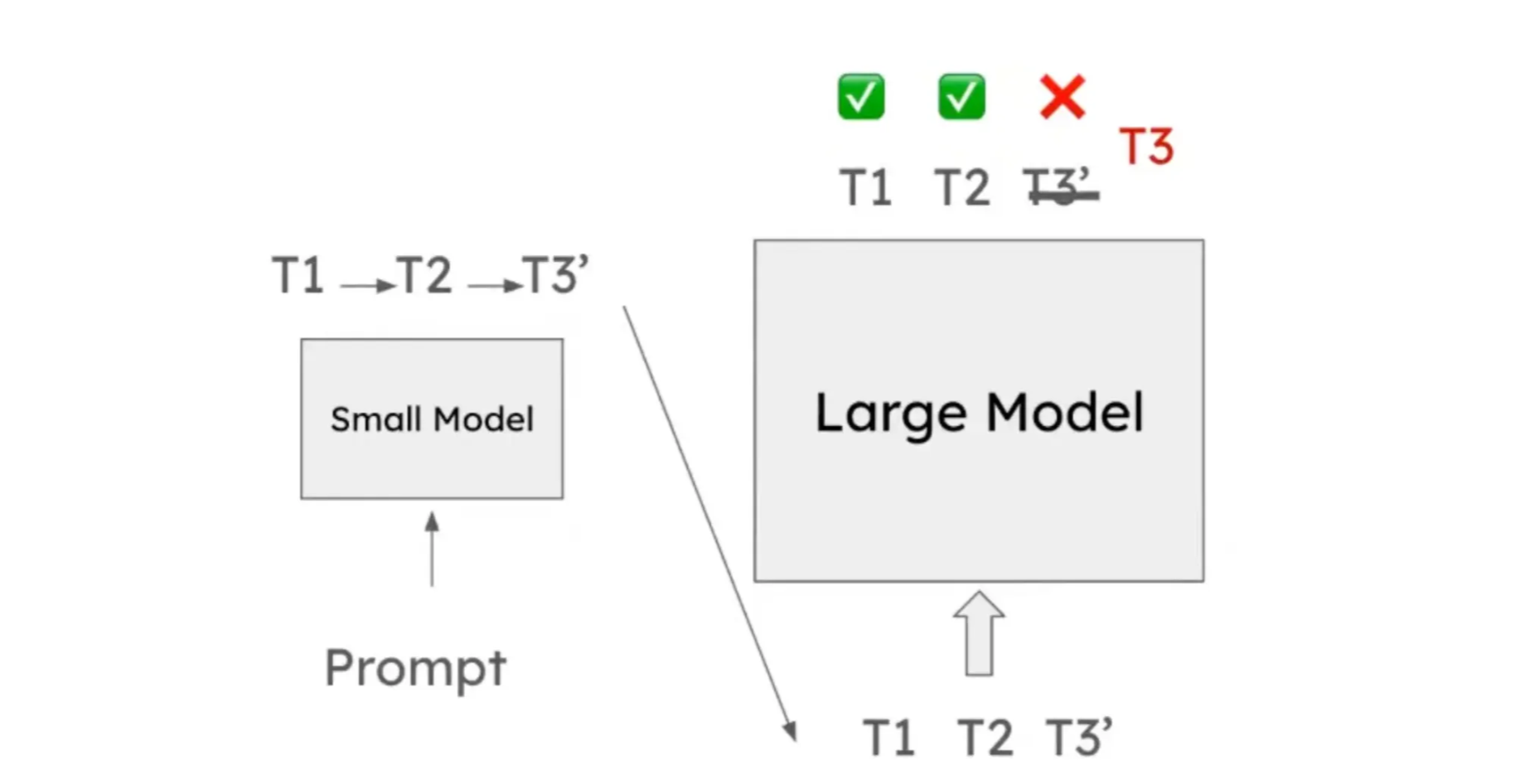
- Idea: Use a small Language Model (LM) to propose tokens, and LLMs to verify multiple tokens in a single forward pass.
- The verification is done in a single forward pass.
- You pull the model weight once from HBM to SRAM, run the LLM forward pass once, then you know if T1, T2, T3 are correct or not.
- It reduces memory accesses by amortizing model weights loading cost.
- The verification is done in a single forward pass.
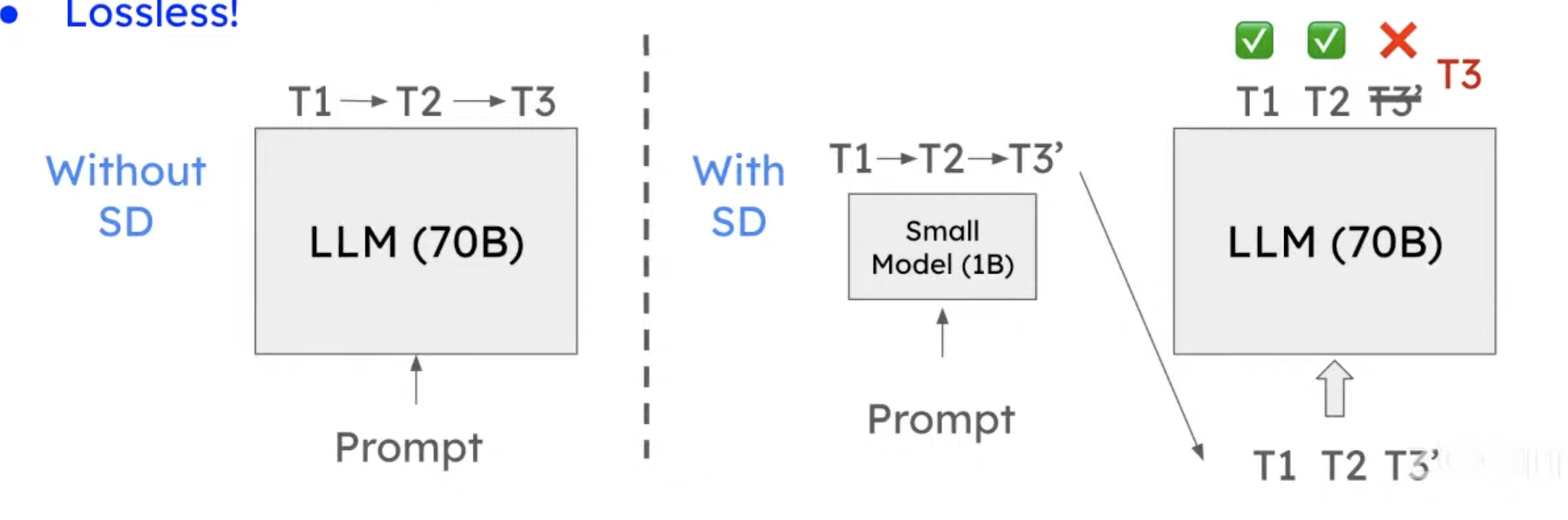
- Lossless!
- It is mathematically proven that SD will not decrease LLM’s accuracy. The output tokens would be exactly the same as if only the LLM generates tokens.
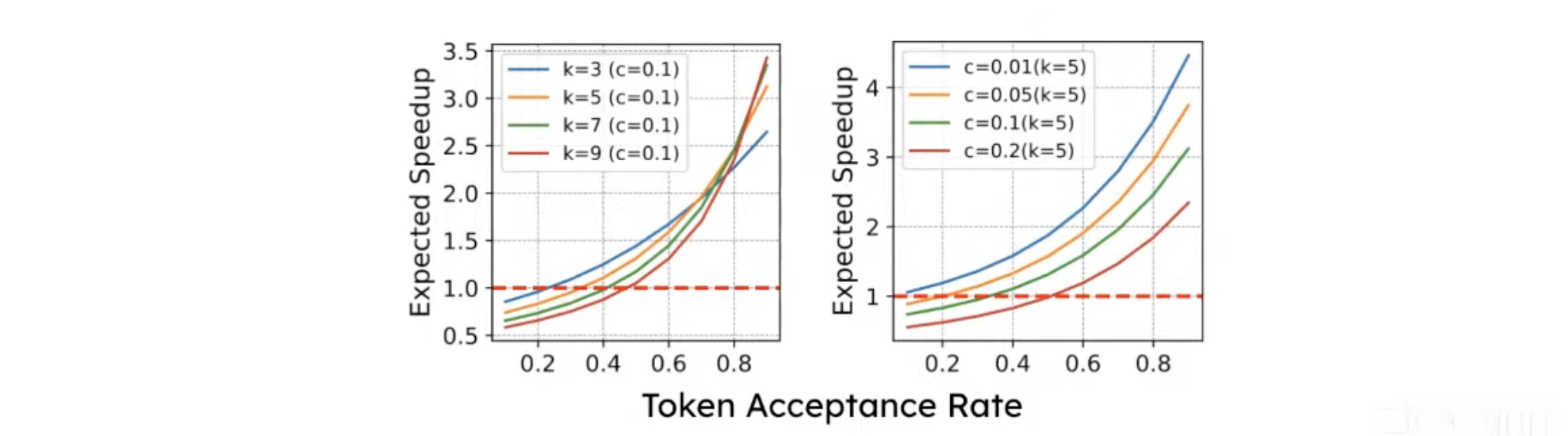
3. Factors that affect SD speedup
- Token acceptance rate
- Assume in the extreme case, you have a very smart small model with only 1M parameters, that can guess all the tokens right, then you don’t need an LLM.
- The point here is that how smart the small model is (i.e., how many tokens it can guess correctly) affects the SD performance.
- Speculation length (k)
- This defines how many tokens the small model generates for the LLM to verify
- Cost of the drafting method (c = ExecTime(draft) / ExecTime(target))
- How expensive it is to run the small model
- In the extreme case, if the small model has the same size as the LLM, then there is no saving at all.
4. Draft-model based SD
- Use a small draft LM to guess, and a large LM to verify.
- The method was proposed in year 2023 when SD was first proposed
Some commonly seen (draft, target) model pairs
- (Llama-68M, Llama-2-7B)
- (Llama-2-7B, Llama-2-70B)
- (Llama-3-8B, Llama-3-70B)
- (?, Llama-3-8B): even today, we haven’t found a good draft model for Llama3-8B → You need to train one, which is expensive
Challenge: How to find the draft model?
The first version of SD in vLLM was draft-model based. Performance:
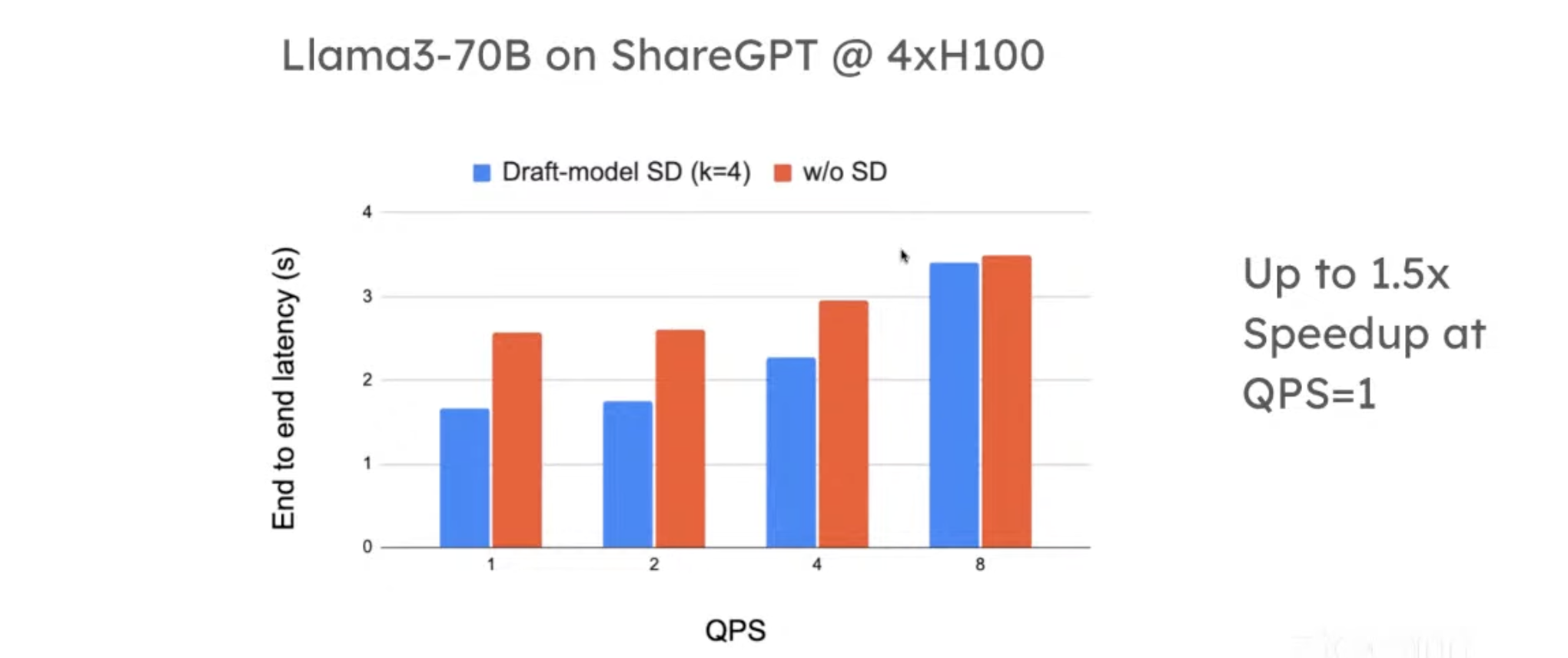
- The x-axis is query per second (QPS). When QPS is low, we can have up to 1.5x speedup.
- SD helps to relieve the memory-bound issue. When QPS is high, the workload is more compute-bound, and thus SD is less helpful.
5. Prompt lookup decoding
- This method is model-free — no need for a draft model.
- This is a pretty powerful method, especially in industry.
- Cursor has a blog post on how they applied this technique.
- Idea: using the following 2-gram lookup table as an example.
- It tries to match the words in the “2-gram” column, and return the “3 speculative tokens”
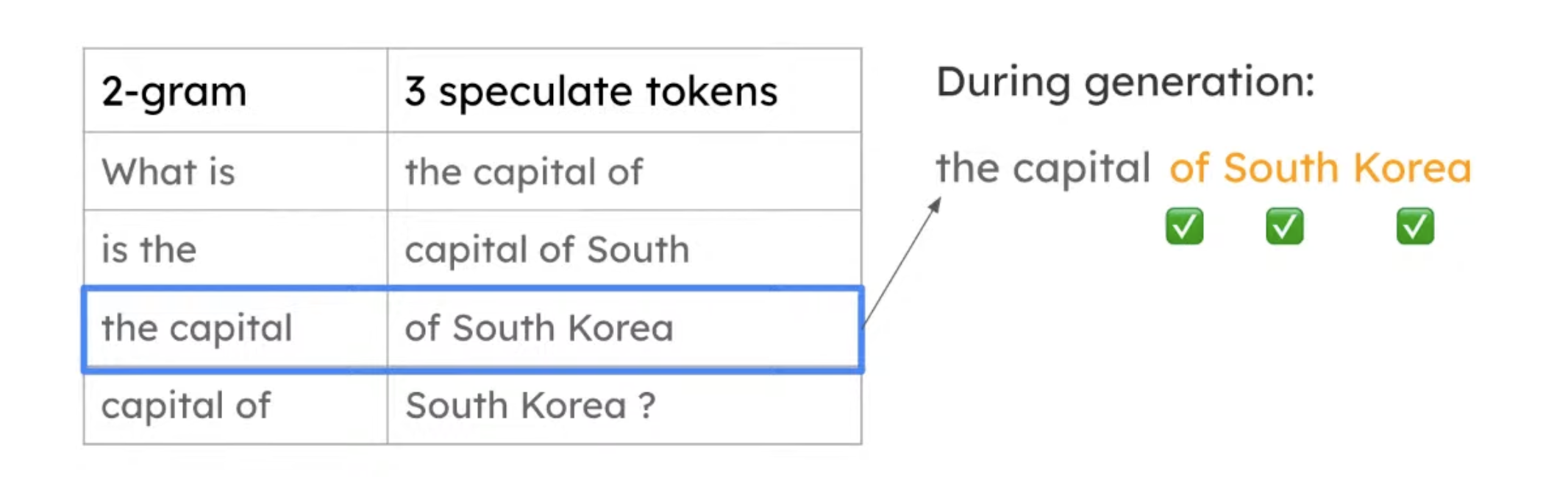
Here is the result
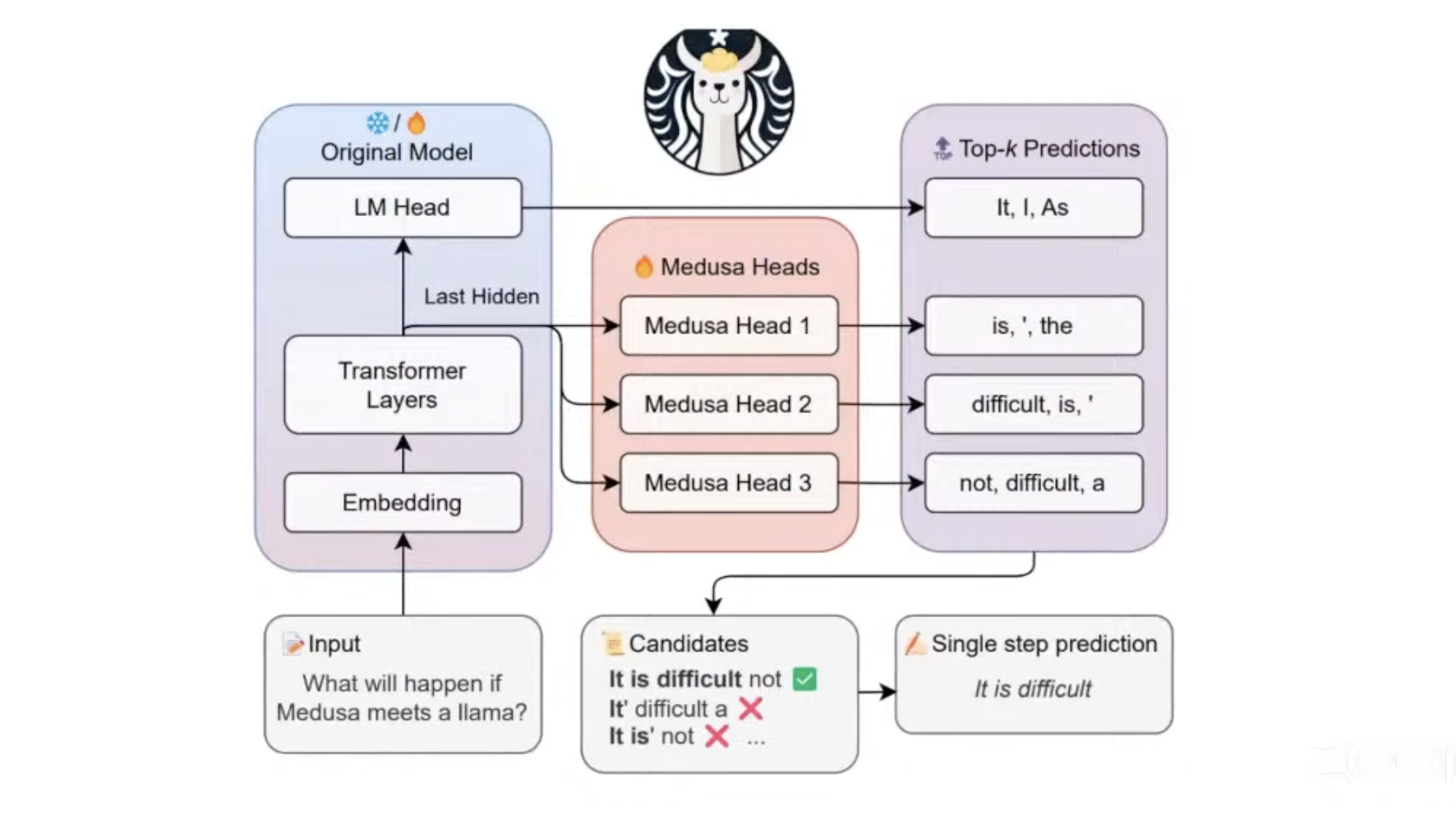
6. Medusa/Eagle/MLPSpeculator/MTP
- We don’t have to train a new model, and we don’t want a simple lookup table
- Instead, we will have some additional layers on top of the original LM.
- Looking at the figure, originally you will send the last hidden states to LM Head to generate the next token.
- Now we are sending the last hidden states to some additional heads to propose tokens.
- This way, we can utilize some info from the main model. In addition, we don’t need to train an independent model.
MTP (Multi-token prediction)
- MTP was first proposed by Deepseek V3, and it is used more and more by open-source models.
- Looking at the figure below, the leftmost part is still the main model.
- There are some additional heads, which have a single layer of Transformer.
- You use these additional layers to propose tokens, and use the main model for verification.
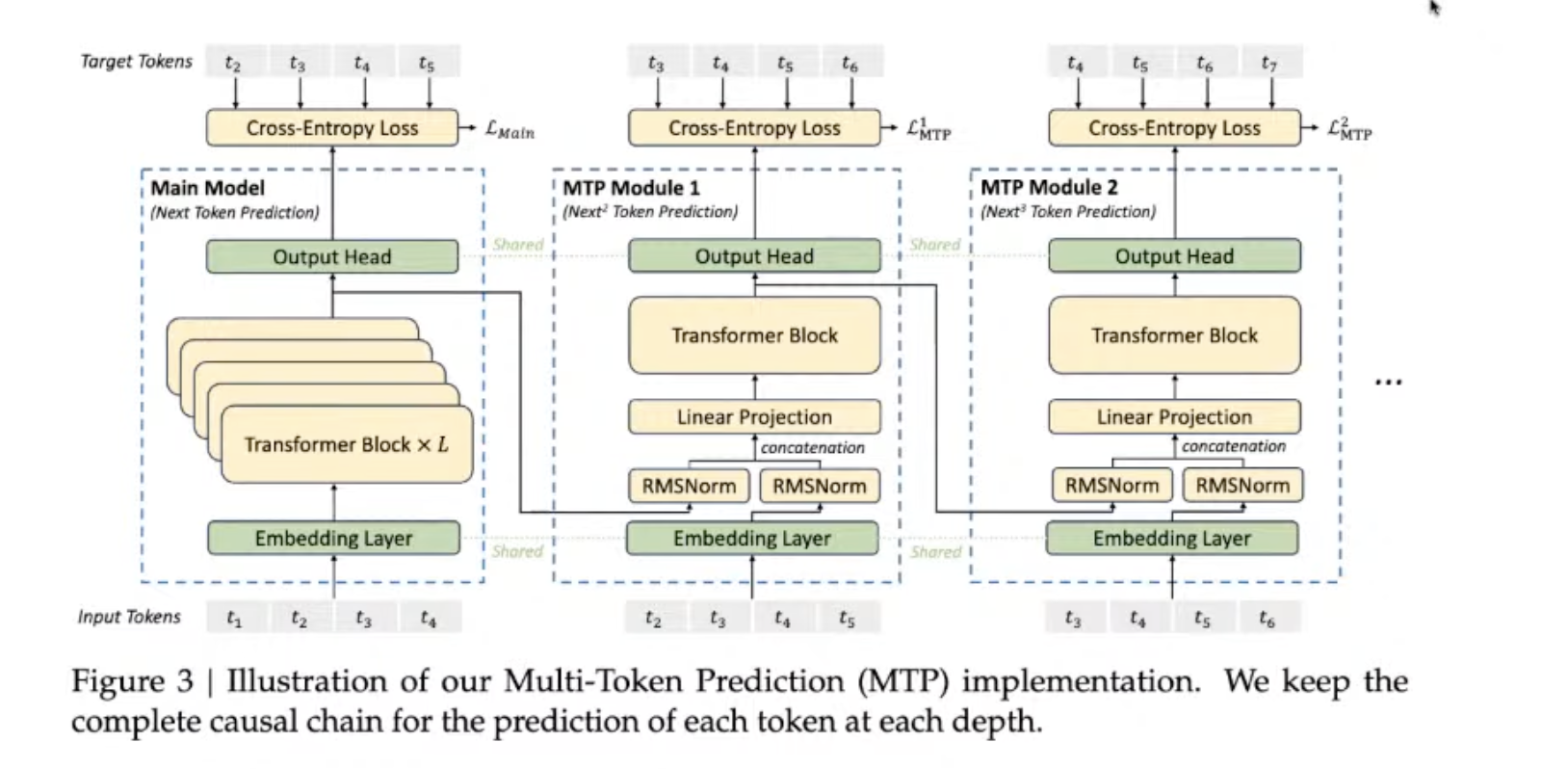
- MTP was originally proposed mainly for training purposes.
- Nowadays models are super large (like 100B) and therefore very powerful.
- Many researchers believe these models have the capability to generate more than one token.
- During training, if we can improve the model’s accuracy to propose more tokens, then it will also improve its capability to propose a single token.
7. Research: Online Speculative Decoding
This is a project Lily did during her PhD
Can we make the drafting method even better?
A typical inference workflow with SD
- Given a prompt, the draft model not only proposes tokens but also gives the probability distribution of the proposed tokens.
- Example: the proposed token t1 has the probability of 60%.
- Then the draft model sends the proposed tokens to the target model.
- Then the target model verifies the proposed tokens. For example, t1 and t2 are correct, while t3 is incorrect.
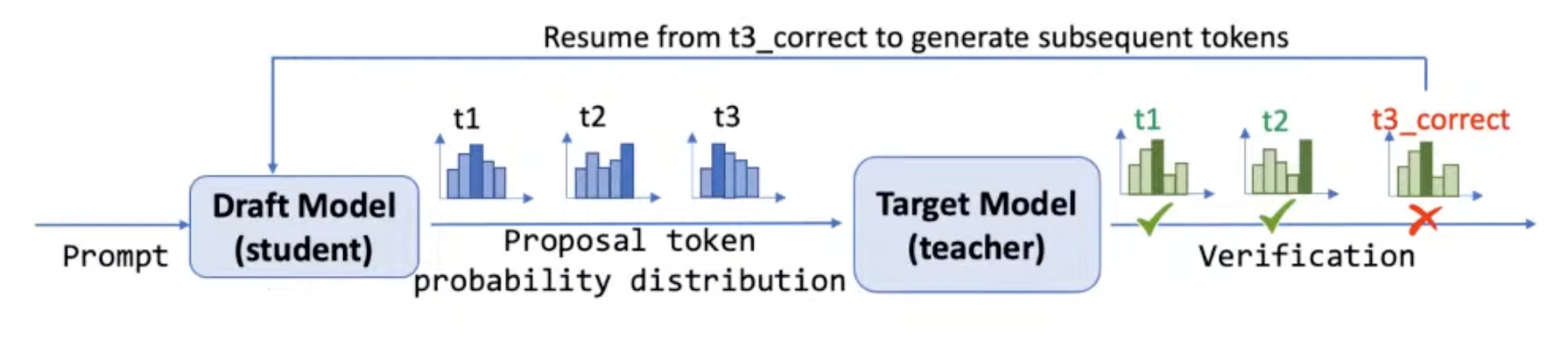
Two observations:
- Static process, draft model is unchanged.
- We have labels (positions and prob distributions) for free.
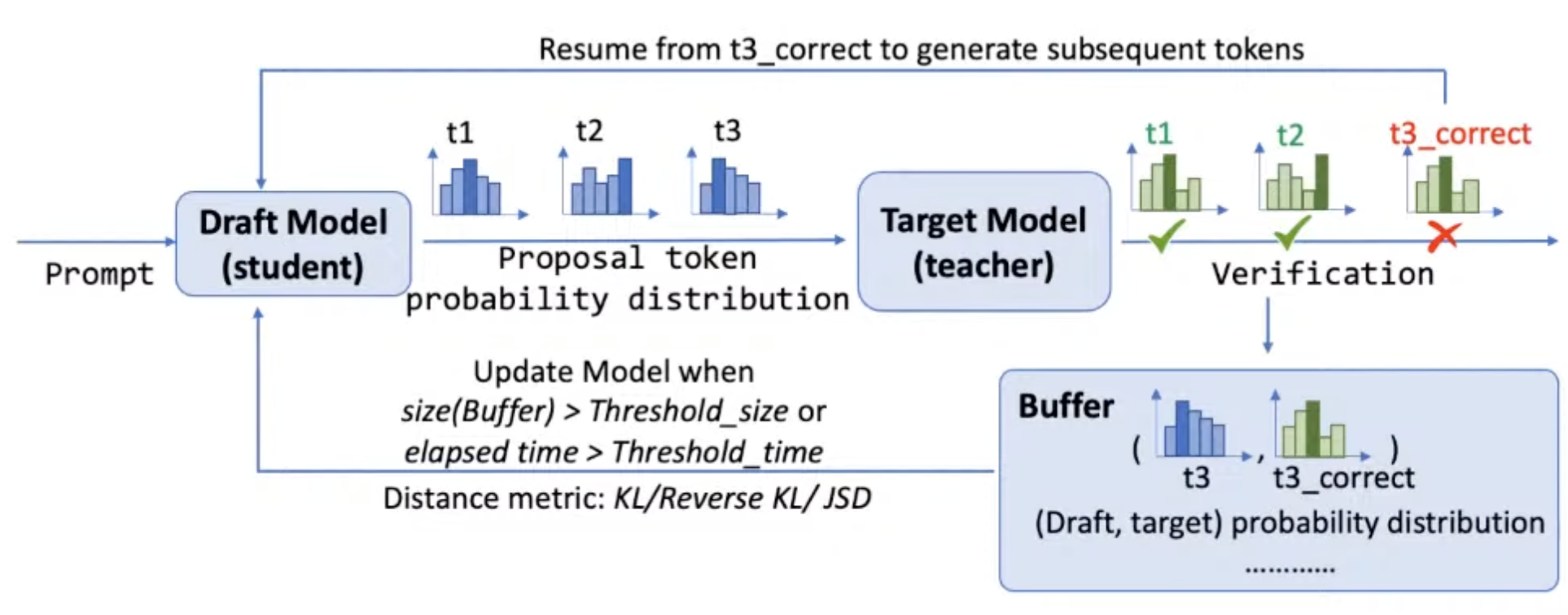
Online SD
Instead of using a static draft model, let’s update it.
- We store the proposed tokens and their prob distributions in a buffer, and use them to improve the draft model.
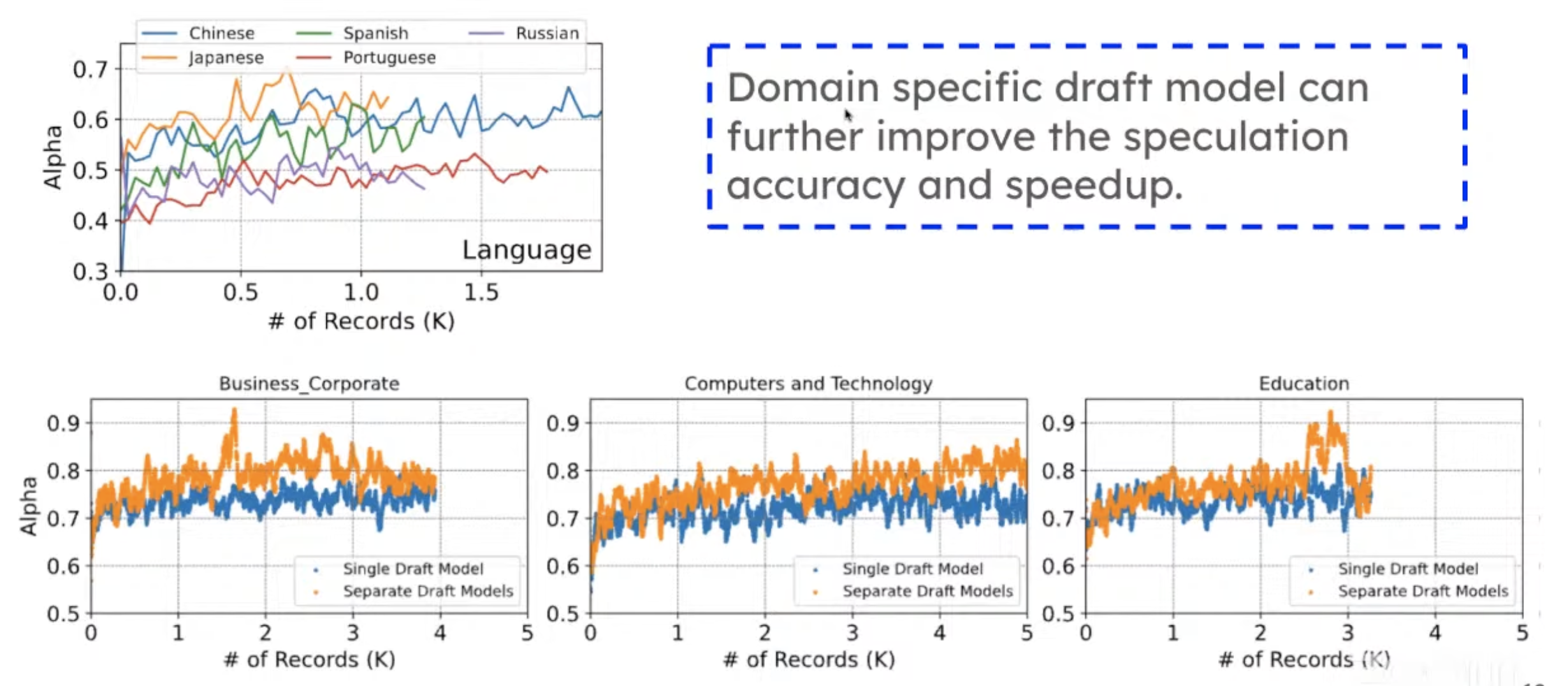
Result: the x-axis is how many records you have seen so far, and the y-axis is the token acceptance rate (higher is better).
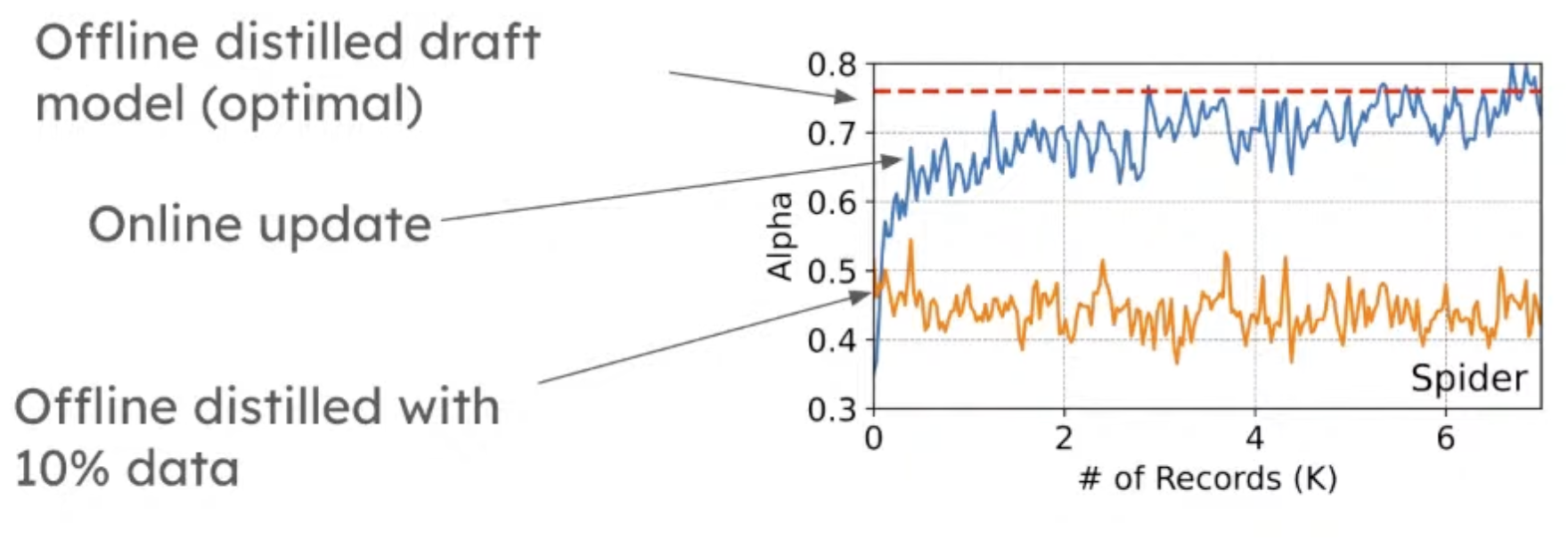
Online updates can improve token acceptance rate very quickly, achieving close to offline distillation.
Customized draft model
Use multiple draft models depending on tasks
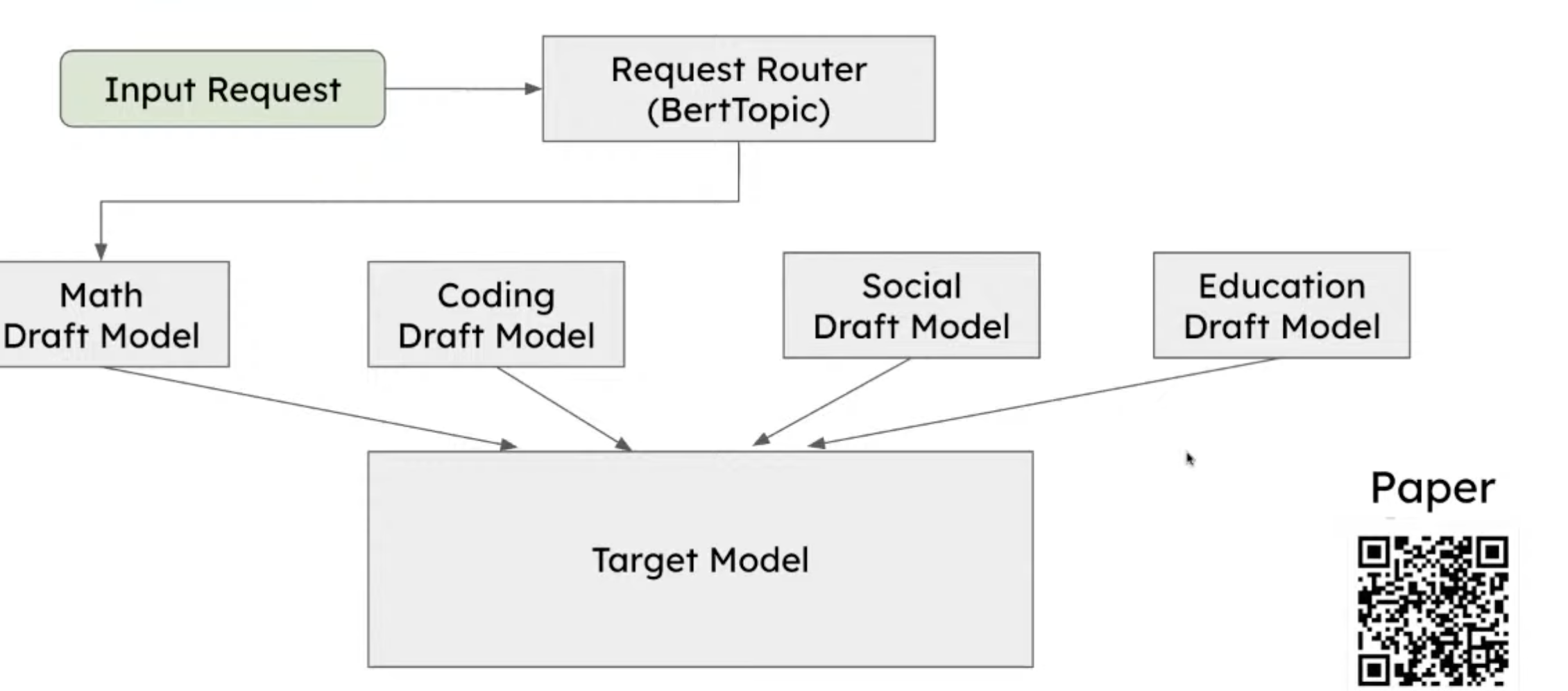
8. Research: Dynamic propose length
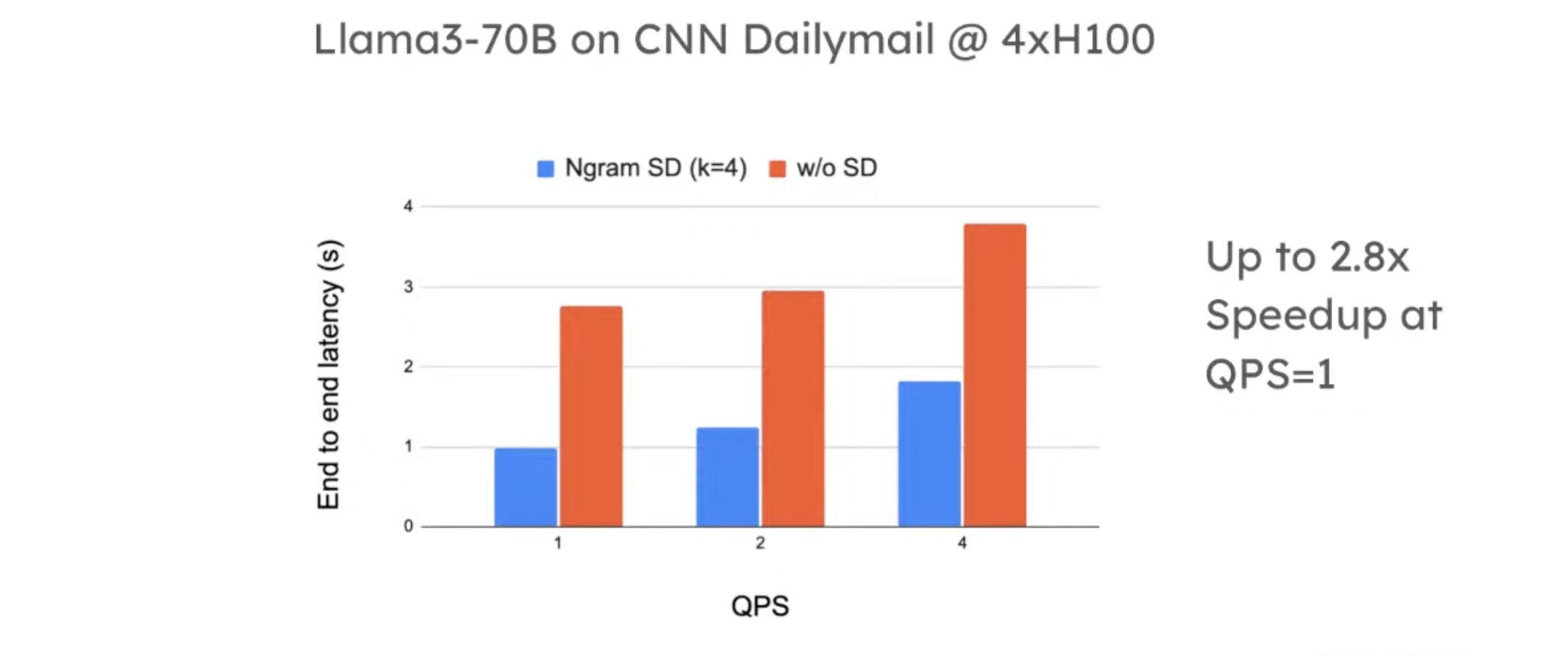
vLLM + SD results
The results were from the first version of SD implementation in vLLM.
- SD has better speedup in low QPS.
- When QPS = 10, SD has slowdowns.
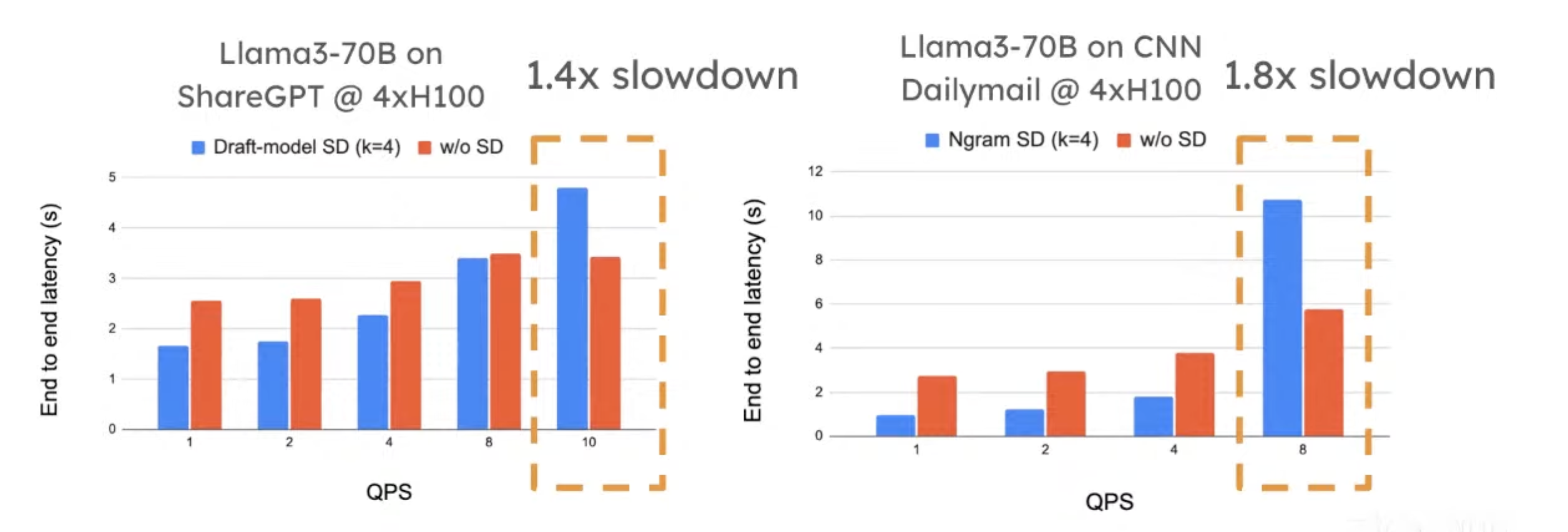
- Intuition: 1) SD solves the problem if generation is memory-bound. It wastes extra computations for better memory access efficiency. When QPS is high, it’s more compute-bound. 2) What’s worse, the tokens proposed by the draft model may not be accepted. Those extra “wasted” computes have a larger impact when your workload is more compute-bound.
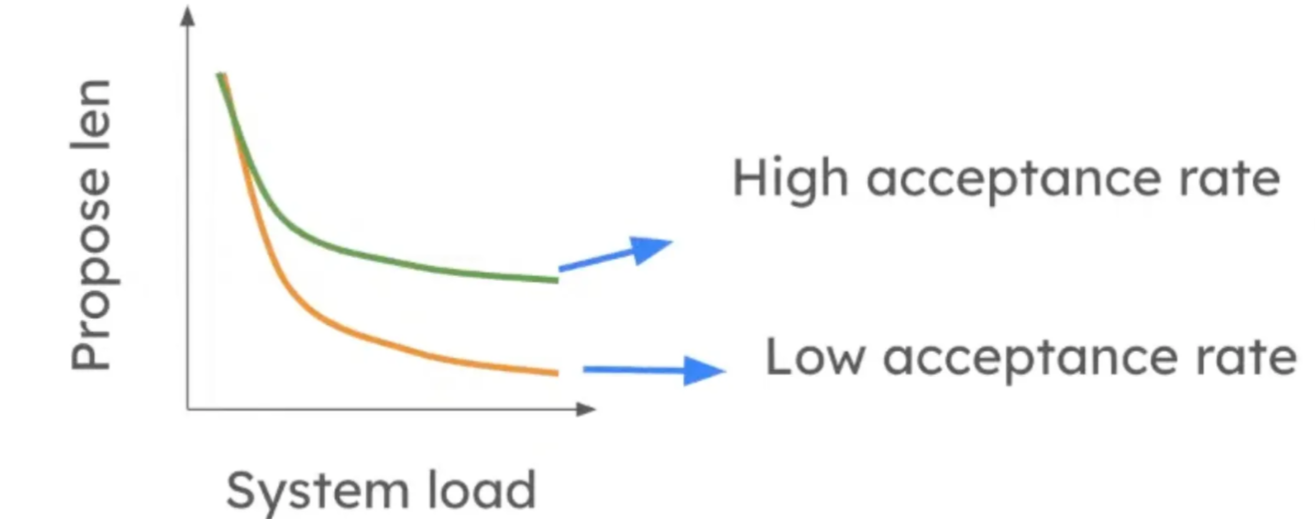
Dynamic propose length
- Dynamically adjust the propose length based on system load and speculation accuracy.
- Paper: https://arxiv.org/pdf/2406.14066
- TurboSpec: Closed-loop Speculation Control System for Optimizing LLM Serving Goodput
9. vLLM + SD
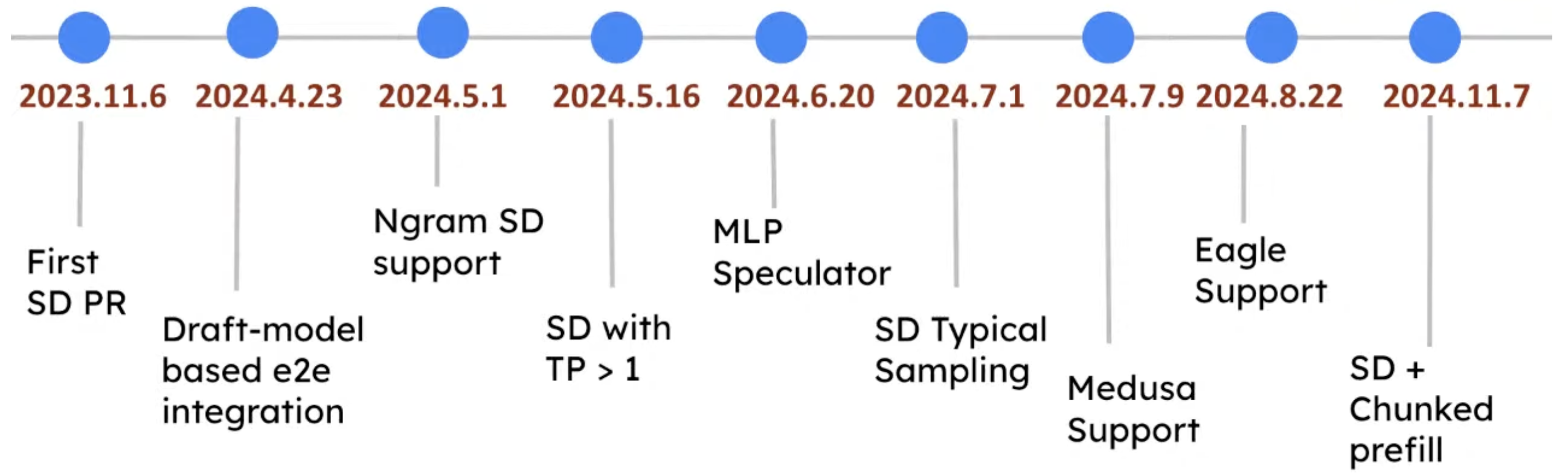
Timeline
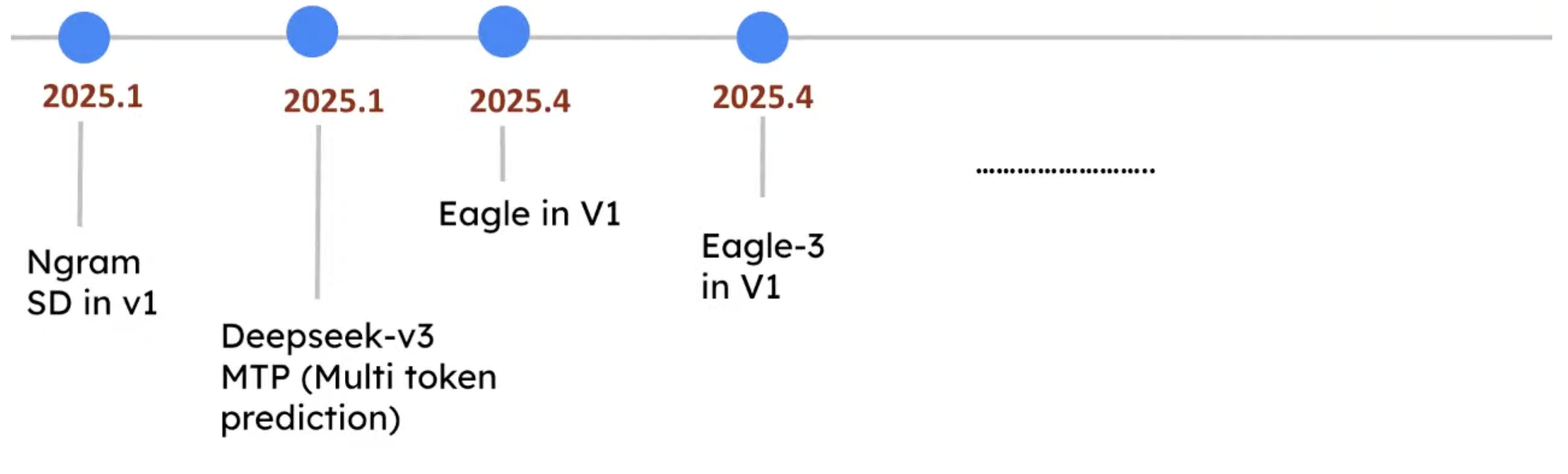
Now not only Deepseek, Qwen model also uses MTP.
Results in vLLM v0.8.5
about 1.5x to 2x speedup
We want to make sure the implementation in vLLM is efficient.
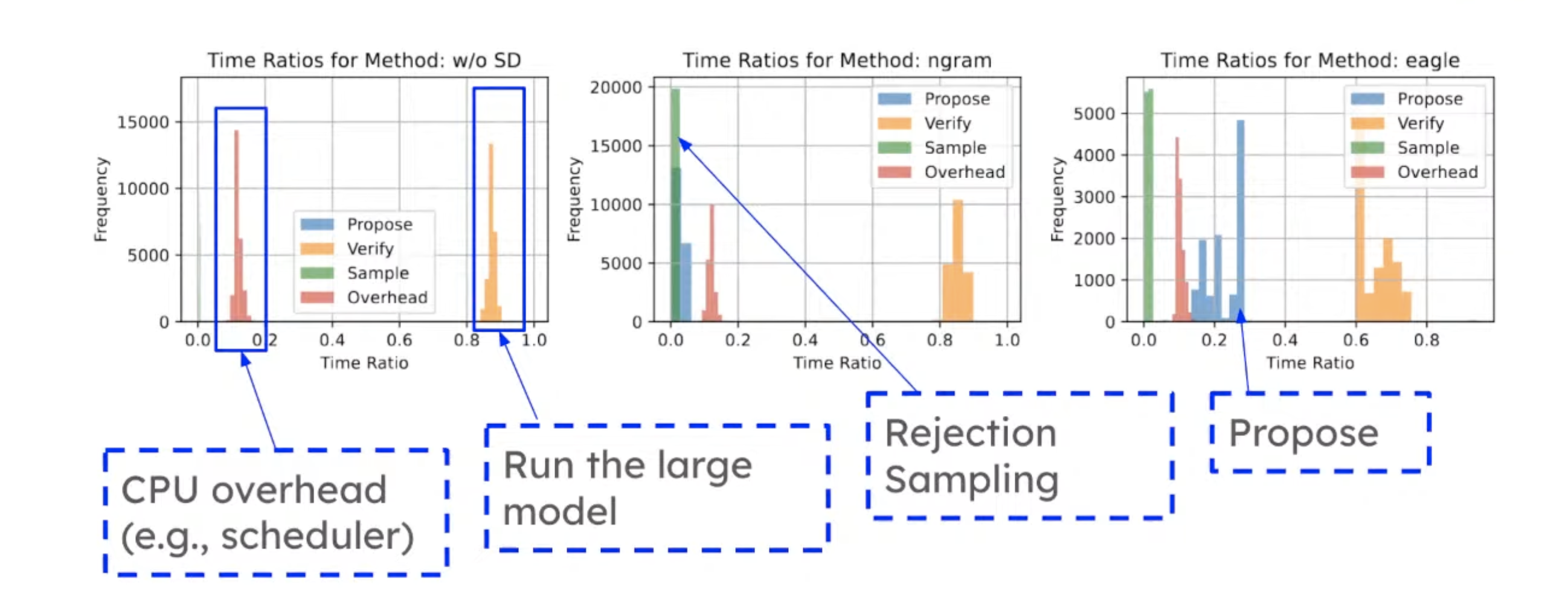
Let’s look at the execution time breakdown.
- The leftmost figure is without SD. CPU overhead is ~15%, while LLM inference takes ~85%.
- The middle figure is n-gram. The CPU overhead is still ~15%. The lookup time is less than 5%. N-gram is very efficient.
- For draft-model based methods as shown in the rightmost figure, the propose overhead is ~20%. But you can still see speedups. Because the additional heads is only 5% parameters of all model parameters.
10. QA
Q1: which workloads are good for SD?
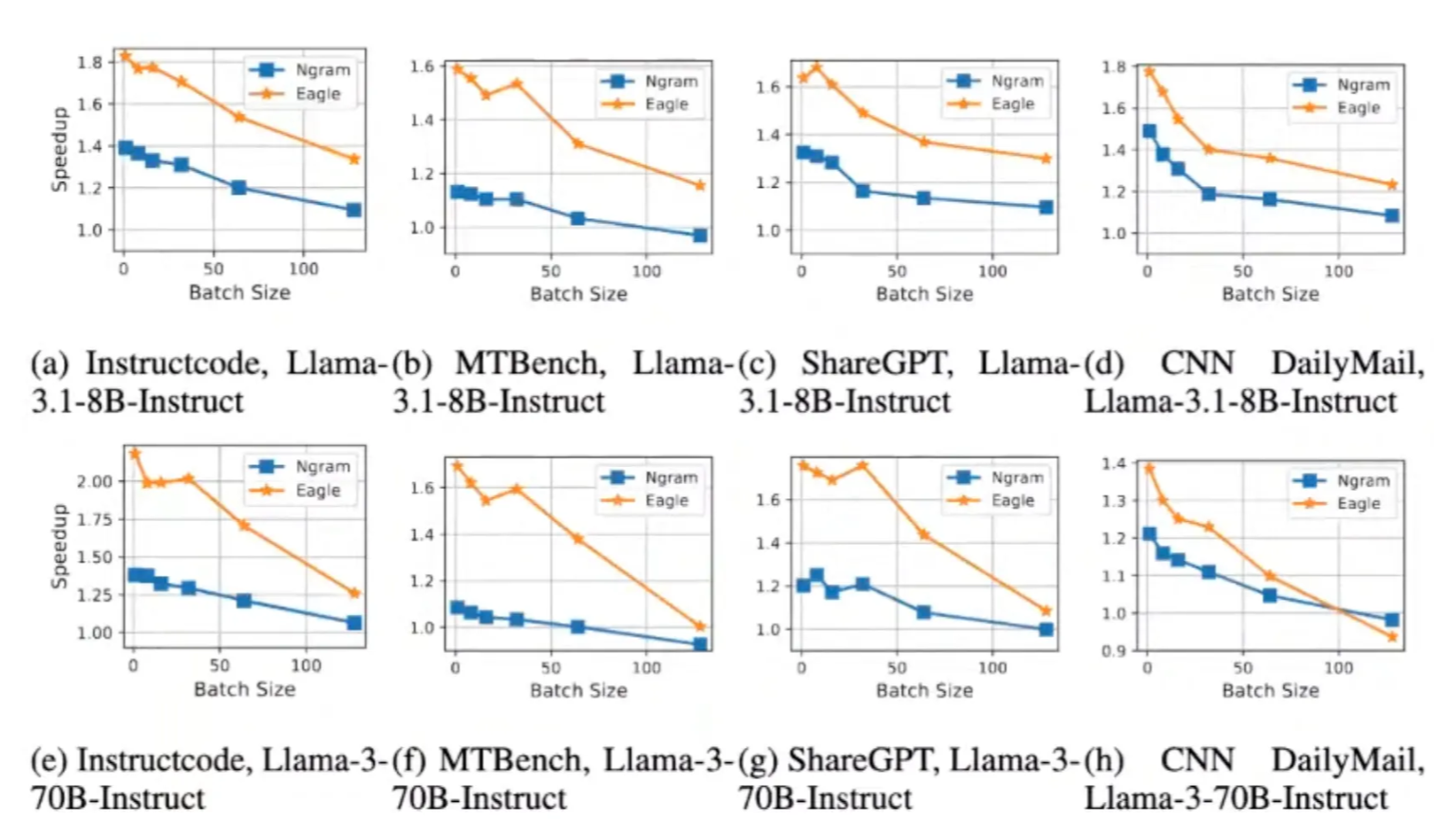
- For companies without many resources, we highly recommend n-gram.
- Suitable for code editing and summarization, where the output and the input have large overlaps. You can think about whether the task adds new info or just compresses the original info
- We can see 2x to even 10x speedups on some coding tasks.
- Cursor relies on n-gram very heavily.
- For chatting apps or open-ended QA, try Eagle
Q2: how do we reinforce the draft model?
Background
Knowledge distillation is a general framework to align the predictive distribution of a small model (i.e., student model) with that of a larger one (i.e., teacher model).
Knowledge distillation is highly effective for speculative decoding. The draft model acts as the student and the target model serves as the teacher.
Try different KL divergence metrics for the student and the teacher.
Use traditional distillation methods with different loss functions.

Q3: the small LM may co-locate with the main LM. What is their size ratio? Also in the project that has multiple draft models, are they placed in the same machine or not?
- It’s a deep research question. No conclusions yet.
- In production, draft models are less used due to their complexity.
- Size ratio: say if you use a bigger draft model, will the acceptance rate be linearly increased?
- No. The benefit diminishes quickly.
- Let’s say for (llama-3B draft, llama-70b target) can already have an 80% acceptance rate. But if you use llama3-8B, the acceptance rate is only ~85%.
- Actually, for 70B-scale models, the best scale for target models is ~3B.
- Because the draft model is so small, we just put it on a single machine.
- The draft model will occupy at least 20% of the main model’s GPU execution cycles. That’s why MTP, where the draft and the main LM share the same model, is more and more popular.
- MTP also has KV Cache, but they are much smaller than the draft model’s KV Cache. MTP in general is a better approach.
Q3: Currently, n-gram in vLLM is purely running in CPU. Is there a way to use a GPU to speed up the longest prefix matching process?
- We made that design on purpose. We tried the classical KMP algorithm, but it was not easy to implement. So we used numpy to implement this.
- During benchmarking, we found that the overhead is less than 5%, which is acceptable.
- String matching is not very GPU-friendly. But if you have a faster GPU kernel, we are happy to check it out.
- if your input length is 10s of thousands of tokens, the overhead is usually less than 3%.
- Can we use JAX to do this? It can be automatically used on a GPU. → We haven’t, but it’s worth a try.
- the current implementation is already in C, not Python, so the efficiency is good enough.
Q4: is SD useful for reasoning models?
- Draft-model based: it’s hard to be useful. If the model is too small, its reasoning capability may not be good enough.
- MTP: unknown. Haven’t tested it yet. It might work because MTP’s acceptance rate is very high (80%-90%). MTP is trained with the main model. So we guess it will have some reasoning capabilities.
- N-gram. Definitely take a try. Why? Reasoning tasks have long outputs. For long context, n-gram is still very efficient (i.e., the proposing overhead is very small). In addition, you can see many repeated patterns like “oh wait”, “no, the answer is incorrect” for reasoning models.
- there are customers that are currently using SD for reasoning models.
Q5: Have you ever tried using the tokens that were not the most probable (like the 2nd most likely tokens)? - Haven’t tried that, but we are aware of this line of work. There is one sampling work called typical sampling: instead of using the most likely token, we also do sampling for the draft model. You have different ways to sample, and some have a higher acceptance rate.
- There is a PR that samples the draft model. We found that sampling is better than argmax(), especially when the temperature is high.
- temperature=0 is the worst case for SD, because it does not have error tolerance. If you propose a wrong token, it’s just wrong. But if the temperature is very high, it could be just slightly wrong.
Q6: are there resource limitations for the online learning project with multiple draft models?
- We didn’t have enough engineering efforts on that.
- In addition, you need a backward pass to update the draft model. So you kind of need a training framework to do auto-grad.
- There are system implementation challenges. For example, are they two systems or one system?
Q7: for SD, what accuracy is practically useful to speedup? Is that 80%, 85%, or something else?
- Depends on how expensive it is to run the draft model.
- If the draft model is super fast, maybe 40% or 50% acceptance rate can already work.
- Actually, originally we even used a 56M draft model to speculate a 70B model with acceptance rate ~50%. But it still had 1.5x speedup.
Q8: what is the optimal acceptance rate? - Depends on the acceptance rate.
- For MTP, 3 to 5 is doable. In vLLM, the most common setting is 3.
Q9: can we have a hierarchy of draft models? Draft1 speculates draft2, draft2 speculates draft3, …
- Stanford has research on that. It’s not production-ready because serving multiple draft models is still challenging, especially when you need to manage their KV Cache. In addition, how to place these models among machines is also an issue.
Source