vLLM 05 - vLLM multi-modal support
Speaker: Roger Wang
1. Overview large multi-modal models (LMMs)
- most SOTA Large Multimodal Models leverage a language model backbone with an encoder for a non-text modality. E.g., LLaVA, Qwen VL, Qwen2 VL, Qwen 2.5 VL, Kimi VL
- Visual encoders: img → visual embeddings
- Goal of vLLM: add these encoder supports
- input: visual embeddings concatenate with text embeddings
- output: text only. No plans for multi-modal outputs in vLLM (but can be in vLLM-project ecosystem) yet
- reason: architectures for open-source multi-modal-output models are not mature or unified yet
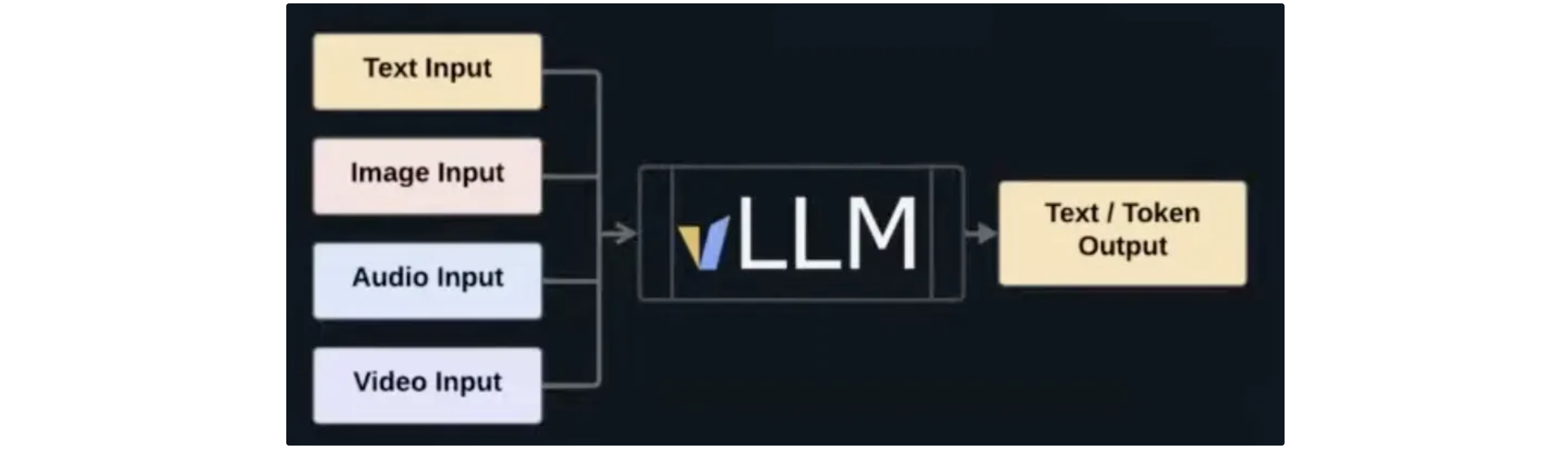
2. Multi-modal LLM inference
- User text prompt: “What’s in this image?
“ & User image: cute_cat.jpeg - -> Tokenized text prompt: [1, 10, 38, 52, 107, 48, 2, 32000]
- 32000 in this example is the image placeholder’s token id, which is fixed for a specific model
- Image data: PIL.Image.Image -> image processor -> image features (torch tensors)
- image features are encoder’s inputs
- -> Expanded text token ids: [1, 10, 38, 52, 107, 48, 2, 32000, 32000, 32000, …, 32000, 32000]
- the image token id is repeated for several times.
- e.g., 32000 will be repeated 576 times in LLaVA 1.5, because LLaVA 1.5’s image embeddings are normalized to a fixed resolution and generate a fixed number (576) of embeddings
- more recent models will do dynamic cutting and padding to convert images to patches, and generate one embedding for each patch. in this case, the repetition count is dynamic
- Q: how do you know the number of repeating times in advance?
- for a specific model, it’s typically based on the image resolution, and you can pre-compute it.
- this process is input preprocessing on CPU, so the dynamic length doesn’t matter. when it’s on GPU later, the length is already determined
- Processed image features: torch.Tensor -> vision encoder (usually ViT) -> image embeddings
- the image token id is repeated for several times.
- -> Text embeddings of shape 583 x 4096 (hidden size of the language model)
- Image embeddings 576 x 1024 (hidden size of vision encoder) -> Projector/MLP -> 576x4096
- Projector: align hidden size between text and image embeddings
- Image embeddings 576 x 1024 (hidden size of vision encoder) -> Projector/MLP -> 576x4096
- -> Merge the two embeddings by replacing where 32000 is with image embeddings
- -> Language model (identical as text-only inference)
- later inference is exactly the same as text-only inference
3. v0 vs v1 for multi-modal
In vLLM V0, multimodality support was designed without…
- Chunked prefill: we assumed requests will always be fully prefilled
- Prefix caching: V0 prefix caching was designed exclusively based on token IDs
- Efficient input processing: we assumed multimodal input processing has little CPU overhead
3.1 Chunked prefill
- Chunked prefill: Prompts can be partially prefilled in a step to balance between prefill & decode workloads
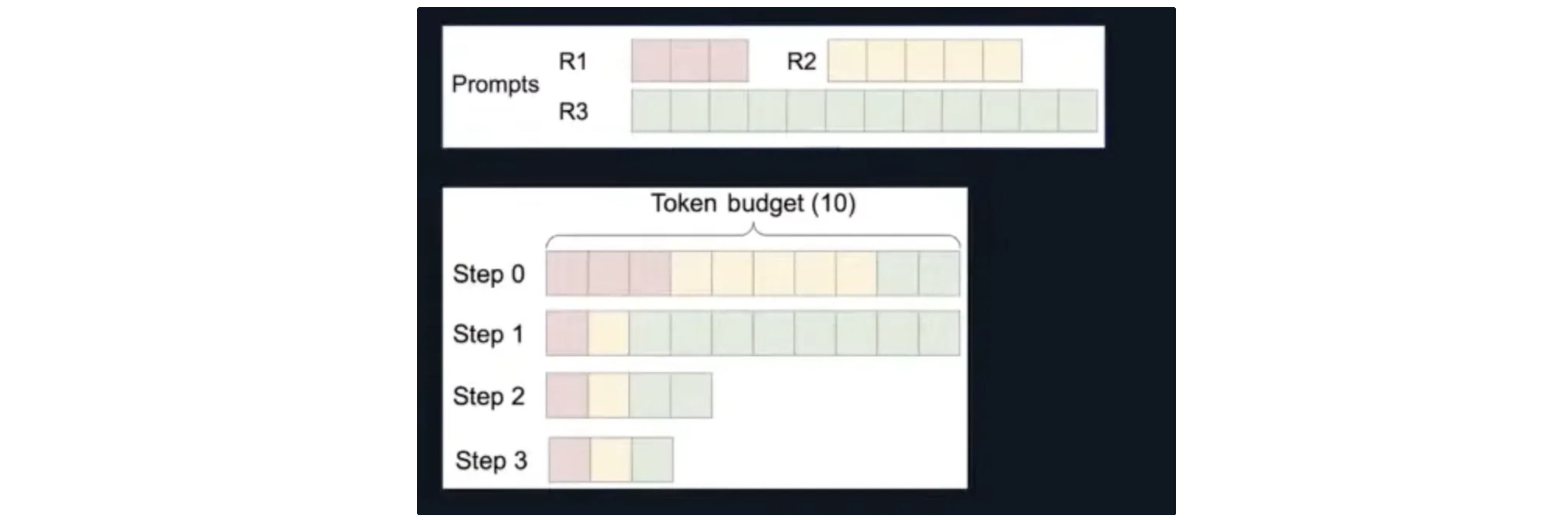
Problem
- Text-only prefill assumes a discrete, causal nature of embeddings (1 token -> 1 embedding)
- causal: previous tokens do not depend on later tokens. as a result, we can do prefill one-by-one
- Multimodal embeddings are typically continuous features and generation cannot be broken up because of encoder full-attention
- LMM in V0 assumes full prefilling, thus multimodal embeddings need to be fully merged with text embeddings once generated
How to do chunked prefill with LMMs?
One possible solution (what we could have done in V0):
- Track multimodal embedding positions in the input sequence
- Re-generate multimodal embeddings whenever needed
- Merge the required portion into input sequence chunk
- Problem: Repetitive multimodal encoder execution. Example
- a 64-frame video of 448×448 resolution -> 16384 embeddings
- if token budget = 2048 -> 9 times of encoder execution for prefilling!
V1: Encoder cache & encoder-aware scheduler
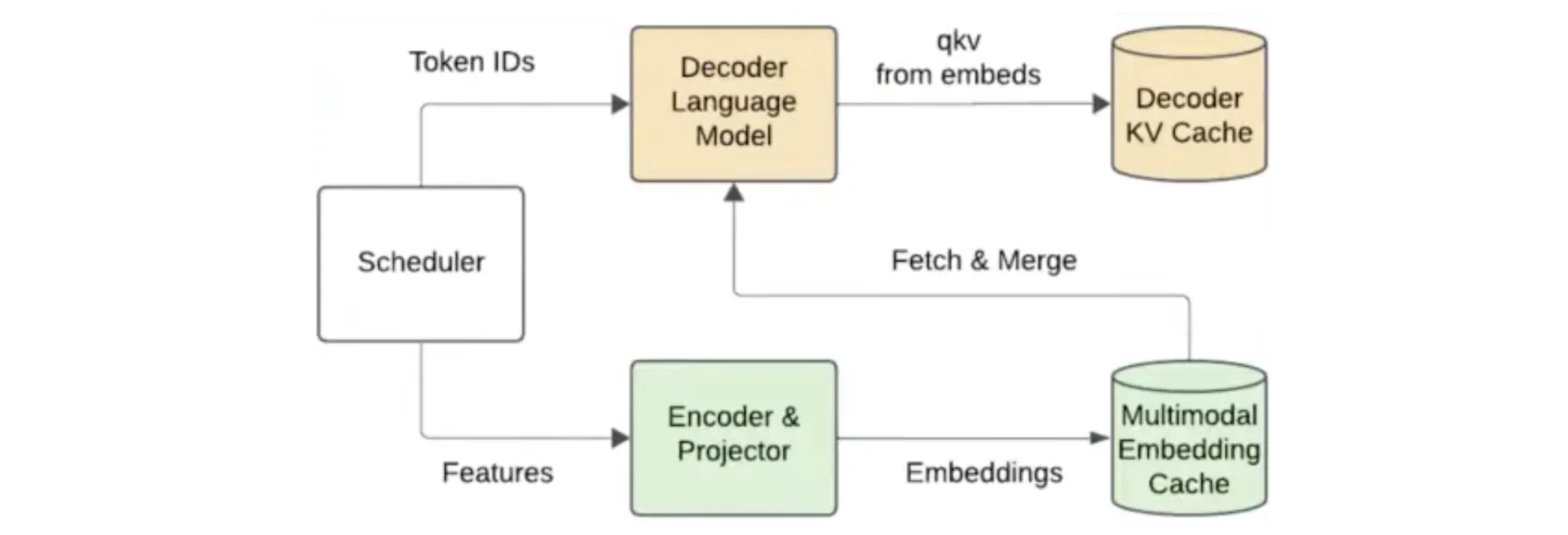
- track multimodal embedding positions
- schedule requests based on both encoder & decoder budget
- you don’t want encoder to block the decoder as well
- multimodal embeddings are generated from encoder execution and added to encoder cache (on GPU!)
- retrieve from cache to merge with text embeddings to be sent to decoder LM
- keep the embedding if still needed for later chunks
- evict otherwise
- e.g., all embeddings for a specific image are fully prefilled
Encoder cache can be extended to support embedding caching across requests! (not implemented yet)
- for example, 5 requests sharing the same image
QA
- Q: does vLLM support KV cache for image embeddings?
- A: after the preprocessing above, image embeddings can be considered to be normal tokens and you can keep their KV cache
- the encoder cache we mentioned before is embedding cache, not the KV cache in the later stage
- Q: how can you do chunked prefill for full attention?
- A: we cannot do chunking in the encoder (due to the full attention). We run encoder once for the full image, and cache it. Then the decoder part (LLM) can fetch chunks from the encoder
- Q: so do images use causal attention in the decoder (LLM)?
- yes for most SOTA models
- some models do full attention for the image part. e.g., gemma3
- you cannot do chunked prefill for such models
- Q: what’s the relationship between images’ resolution and the sequence length?
- A: in general, higher resolution leads to longer sequence length
- but the concrete relationship is determined by models
- e.g., the earliest LLaVA resizes all images to the same resolution, while QWEN2 VL partitions images to patches
- Q: what if the step token budget is too small to prefill a full image?
- A: that’s why we need to support chunked prefill
- Q: any work to use causal attention in the encoder?
- Qwen omni paper: they tried to do sth similar to causal attention for audio (or maybe video) processing
- these data needs to be streamed-in, because you don’t want to start processing after the full audio data is available
- it’s not the mainstream now
- Qwen omni paper: they tried to do sth similar to causal attention for audio (or maybe video) processing
3.2 Prefix caching
some engineering optimization
In V0, prefix caching is exclusively based on hashing tuples of token IDs
Problem:
- multimodal placeholder token and token ID (e.g., “”: 32000) for multimodal embeddings are always the same across requests!
- correctness issue if two requests have identical prompts but different images! (e.g., “ Describe the image.”)
- prefix caching is always turned off for multimodal models in V0
V1: prefix caching with metadata
In V1, prefix caching is redesigned to allow additional metadata about the current block of tokens, so we can now add identifier (image hash, uuid, etc) of multimodal data too!

https://docs.vllm.ai/en/stable/design/v1/prefix_caching.html
There can be much research on caching optimization. For example, image frames of the video have similarities. Right now the multi-modal support is not mature yet.
3.3 Efficient input processing
some engineering optimization
Input processing can be very expensive (sometimes longer than encoder execution)
Optimized engine loop
Image pre-processing (PIL.Image.Image → torch tensors) actually leads to large CPU overhead
V0 assumed the overhead was small, but it turned out not
V1: pre-processing and the inference engine core are in different processes
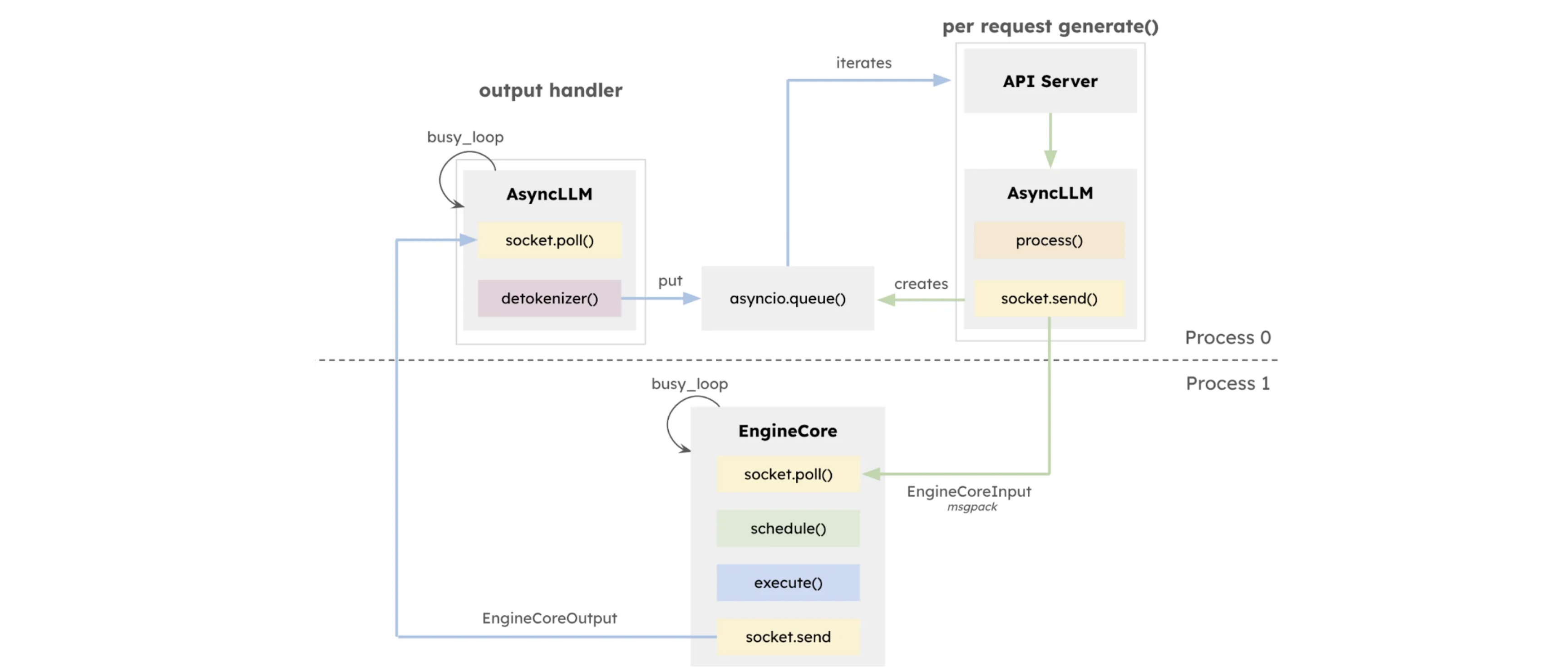
Multi-modal feature caching
- typically we have plenty of CPU memory available, so it can be utilized to cache the generated features from raw data format
- reuse same identifier for prefix caching
- mirrored caches in two processes (AsyncLLM and LLMEngineCore0) for less data transfer
- next step: use shared memory that both processes can access

- for multi-turn conversations or few-shot learning, we don’t have to re-generate features
4. Benchmark
Online serving
Results on previous alpha v1 releases
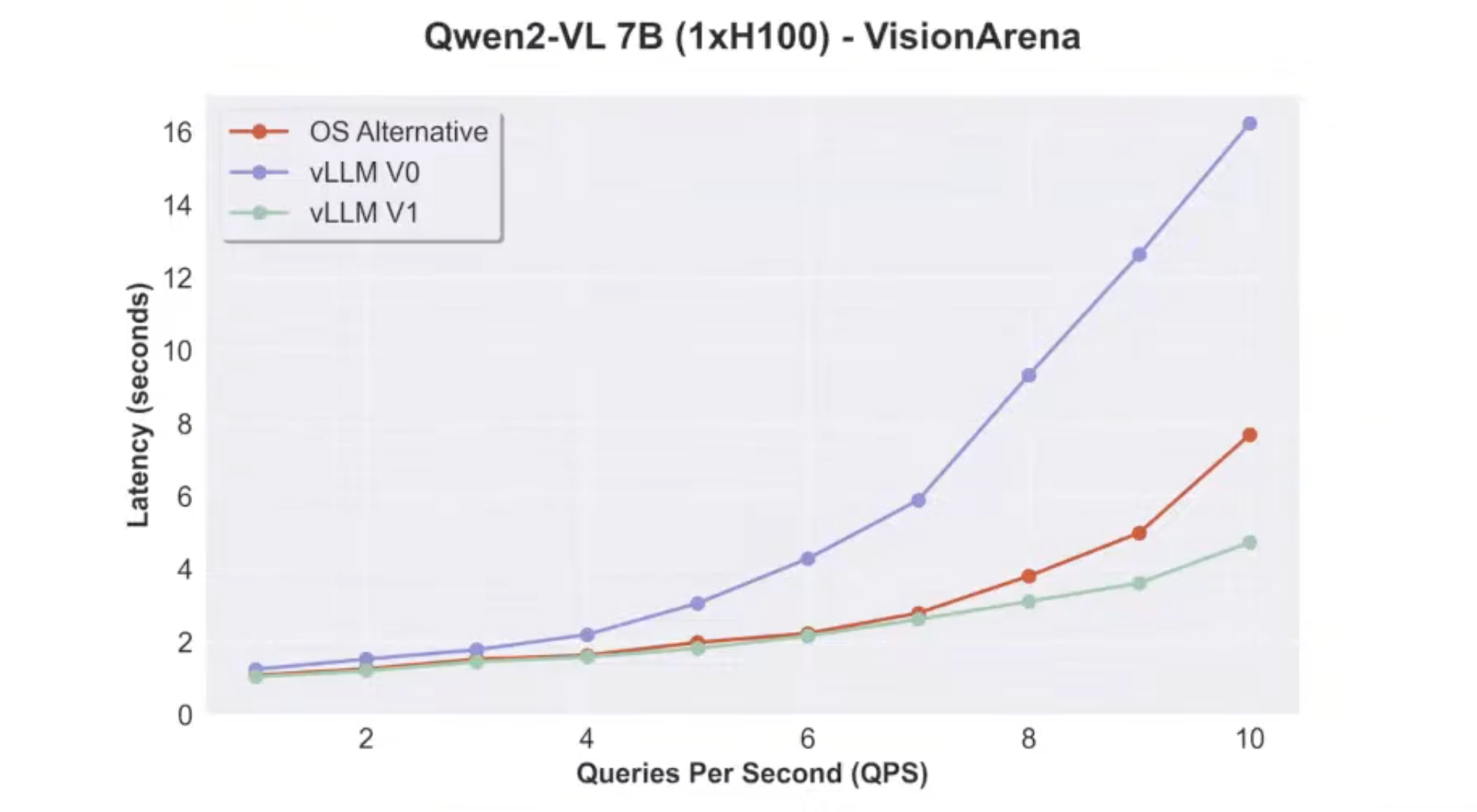
- workload: single image + single text question
- when qps is low, not much room for optimization
Offline inference
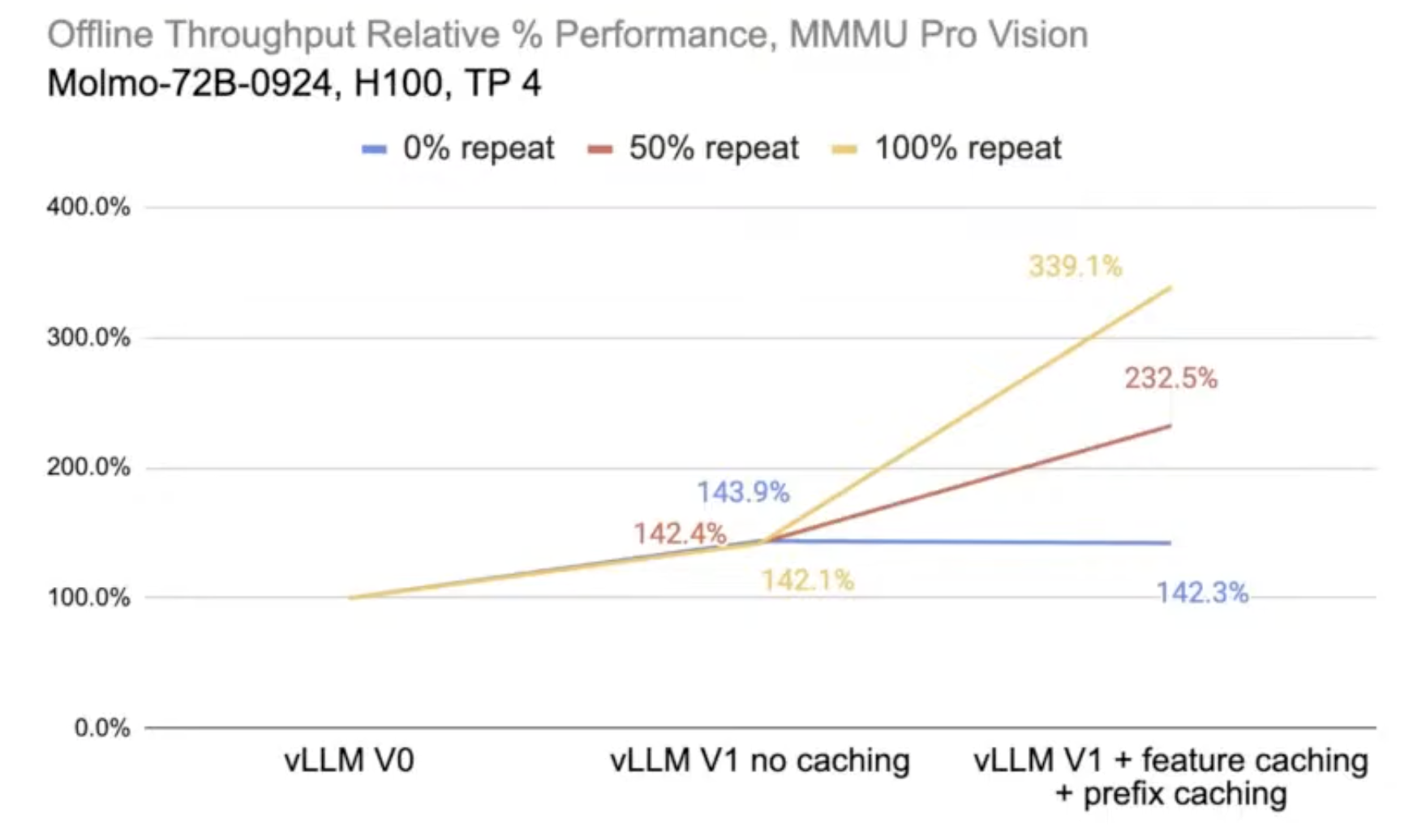
- v1 no caching: benefits from splitting processes
- 0% repeat: all images and text are unique
- v1 + feature caching + prefix caching: worse than no caching due to the extra caching overhead but they were not reused
- 50% repeat: 50% of all data are repeated
5. Future work
- right now one AsyncLLM works for one EngineCore. Change to many-to-many mapping
- we can use more processes for image pre-processing
- Non-huggingface/third-party processor plugin
- currently using huggingface to process
- the reason vLLM decided to use huggingface because they didn’t want developers to implement new model supports twice (on huggingface and on vLLM)
- but it turned out huggingface was too slow, and developers want to add their own processors
- streaming inputs support
- e.g., process image frames on the fly for a video
- why not supported at this point
- currently the scheduler is not stateful. it cannot receive a signal like “more frames will be streamed for the current video”
- not very popular in the community: although Qwen 2.5 VL supports video understanding, most ppl use it for image understanding. needs a good video understanding model
- Blended mixed modalities
- previously, data in different modalities are concatenated
- “audio in video” in Qwen2.5-Omni: audio and video embeddings are mixed together
- e.g., if we have 12 audio embeddings and 15 video embeddings. we can place them as 4 audio embeddings + 5 video embeddings + 4 audio embeddings + …
- Multi-modal output: not likely in vllm-project/vllm
Any contribution/discussion is welcomed!
- Slack channel #sig-multi-modality
- vllm-project -> Projects -> Multi-modality Core
- Current core contributors:
- Roger Wang @ywang96
- Cyrus Leung @DarkLight1337
Source: