Pallas examples by Sharad Vikram (Pallas author)
https://www.youtube.com/watch?v=NFKubflDb1A
- code was written in 2023 (may be slightly outdated, but the core concept still valid)
- presented by Sharad Vikram (Pallas author)
1. TPU architecture recap
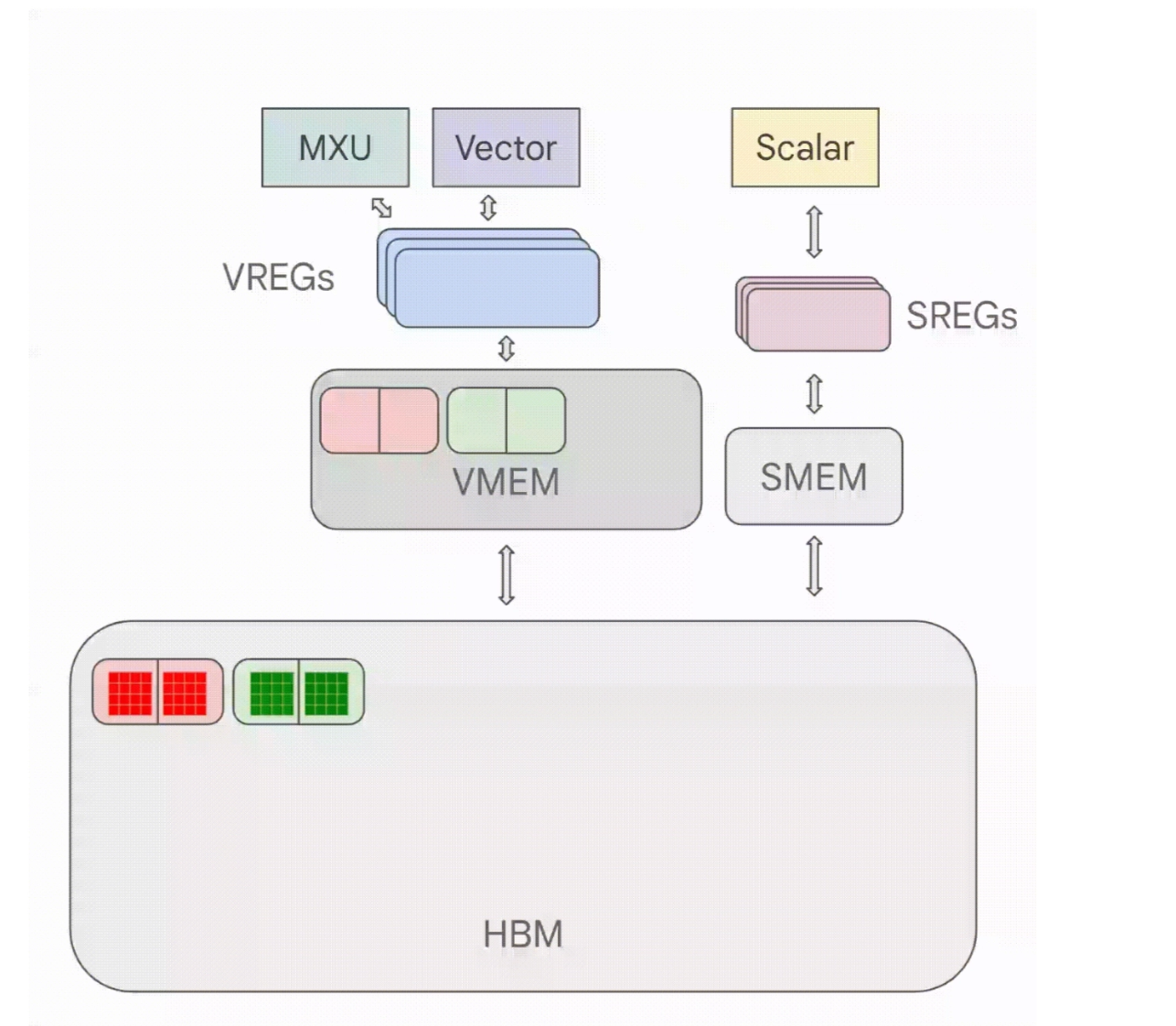
- VMEM: like L1 cache for TPU
- VREGs: vector registers
- HBM → VMEM → vector registers (VREGs in 8x128 unit)
- scalar unit & SMEM: like the regular CPU
- this tutorial focuses on VMEM examples, not SMEM
2. add_vectors example
2.1 code
1 | |
- by default, the refs are VMEM refs. you can think them roughly as pointers to VMEM slots
- intput Refs (
x_ref[...]andy_ref[...]) vector-load data from VMEM to VREGs - output Ref
o_ref[...]vector-store data back to the VMEM slots
1 | |
- the code above does the orchestration
- it moves data from HBM to VMEM, excute the kernel, and copy output buffer back to HBM
jax.jit: trace your function and compiles it with XLA- tracing: replace array arguments with abstract “tracers” (no concrete values, only shape and dtype)
- purpose of tracing: compile once and reuse for different inputs
2.2 lambda and module blocks
let’s check the debug output (skip this section if not interested in details)
1 | |
High-Level Pallas IR (lambda block)
1 | |
lambda ; a:Ref{int32[8]} ...: function args.Reftype indicates these are pointers to VMEMd:i32[8] <- a[:]: load op. moves 8 integers froma(VMEM) intod(VREG).f:i32[8] = add d e: vector addition ofdande, storing the result in registerfc[:] <- f: writes data from registerfback into VMEM slot pointed to byc
Lower-Level MLIR (Mosaic ML module block)
the lambda block above is lowered to Mosaic ML module
1 | |
memref<8xi32, #tpu.memory_space<vme>>- arg type: VMEM memory reference
vector.load- load a chunk of data into its registers in a single cycle
%c0(constant 0) indicates it is loading from the beginning of the buffer
arith.addi- “Arithmetic Add Integer” instruction performed on the vector registers
- happens in MXU or VPU
vector.store: This moves the calculated vector result back from the registers into the output buffer in VMEM
2.3 HLO
a serialized version of the Mosaic ML module above
1 | |
HLO block
1 | |
- Entry Point (
@main): what the XLA compiler sees when it schedules the task
tensor<8xi32>: unlike thememrefin the lower-level MLIR (which points to a specific physical memory location), these are high-level XLA tensorsmhlo.sharding = "{replicated}": data is replicated across all TPU cores in the partition, rather than being sharded btw them
- Wrapper Chain (
@add_vectors→@wrapped→@apply_kernel)
- JAX often generates several private functions during the lowering process. act as administrative wrappers that handle:
- Shape checking: ensure the input tensors match the kernel’s expected dimensions
- Transformation state: maintain consistency if the kernel was transformed by other JAX primitives like
vmaporgrad
- Custom Call (
@tpu_custom_call)
- the most important part
stablehlo.custom_call- since “Pallas kernels” are not standard XLA ops (like a normal
addordot), XLA treats them as a “custom call.” - it basically says: “I don’t know how to execute this myself, so I’m going to hand it off to a specialized backend.”
- since “Pallas kernels” are not standard XLA ops (like a normal
@tpu_custom_call: targets the TPU’s custom execution pipelinebackend_config = "...":- in a real output, this string is very long. It contains the serialized Mosaic MLIR module (the one with
vector.loadandarith.addi) - when the TPU compiler receives this HLO, it unpacks this config string to find the exact instructions for MXU
- in a real output, this string is very long. It contains the serialized Mosaic MLIR module (the one with
3. matmul w/ BlockSpec
we want to show how we stream data chunks (rather than all the data)
kernel definition
1 | |
- each execution is called a program
- program_id: the index of the program
and the wrapper
1 | |
static_argnames- it tells JAX “these args are not traceable. treat their concrete values as compile-time constants.”
- when values changes, JAX recompiles
BlockSpec- w/o BlockSpec: copy all data from HBM to VMEM, do all the computes, then copy all outputs back to HBM
- w/ BlockSpec :we stream the chunks of x, y using Blocks instead
- key fields
block_shapeinBlockSpec: the tile shape that each program sees, like(bm, bk)grid: how many times the kernel runs + indexing schemeindex_mapinBlockSpec: maps index of a grid (program_id) to a specific block (tile)
- this matmul implementation is pretty close to a peak-performance f32 matmul on TPU
- 3d grid vs 2d grid
- this implementation uses a 3d grid
- X and Y tiles shift along the K axis as
kincrements (the sliding window over the contraction dimension) - output tile
(i, j)is fixed for all values ofk
- X and Y tiles shift along the K axis as
- if we change it to 2d grid on TPU
- we need to unroll the accumulation among k inside the kernel
- requires loading the entire row/column into VMEM at once, which leads to more copies into VMEM
- worse performance → we want a better compute-data overlap in the pipeline
- on GPU, in many cases we want 2d grid
- this implementation uses a 3d grid
- tuning block size is a major work (i.e., how much data should be transfered while doing this amount of computation)
- TPU vs GPU: parallel vs sequential
- GPU: kernels are launched in parallel, so the accumultion of
o_refis a sync point (it will be lowered to atomic updates) - TPU: kernels are launched sequentially. no need to worry about contention for
o_ref
- GPU: kernels are launched in parallel, so the accumultion of
4. batched matmul w/ vmap
batched matmul: add a new dimention using vmap
1 | |
- we have a batch dimesion whose size = 4
5. matmul_activation: higher order function
meta-programming: we can inject a higher-order function (activation)
- higher-order funciton: takes function as input arg, and/or return function as output
- activation can be ReLU or something
- we can parametrize
matmulwith anactivationfunction
kernel definition
1 | |
pl.program_id(2) == nk - 1: activation only runs after the final reduction step in tiled matmul
and the wrapper
1 | |
6. softmax
- softmax is tricky to get right → involve several reductions
- a naive implementaion here: load the entire feature
x_ref[...]to VMEM, and do all the redcutions in VMEM - when cannot fit feature into VMEM, or wannt fuse softmax with other matmul → use flash attention
define kernel
1 | |
wrapper
1 | |
7. flash attention
- here is a minimal flash attention implementation
- only do f32 for a single sequence
1 | |
m_ref: previous maxl_ref: previous sum of exponentialsjax.lax.broadcast_in_dim(operand, shape, broadcast_dimensions)- reshapes/broadcasts a tensor to a target shape
- while specifying which dimensions of the source map to which dimensions of the output
l_curr = jax.lax.broadcast_in_dim(s_curr.sum(axis=-1), l_prev.shape, (0,))s_currhas shape[Bq, Bk]- after
.sum(axis=-1), you get sum of exponentials per query row. shape[Bq] l_prevlikely has shape[Bq, 1]- this call takes the 1D
[Bq]result and broadcasts it into shape[Bq, 1] - with
(0,)saying “axis 0 of the source maps to axis 0 of the target.
schedule it using a 2d grid
1 | |
- Q tiles index by
i: for a given query block, Q stays fixed while we sweep over K/V - K and V tiles index by
j: they advance together through the sequence.
call it
1 | |
8. batched MHA / MQA: nested vmap
8. 1MHA
we can just vmap the single-sequence one above to get mha
1 | |
8.2 batched MHA
vmap again to get batched mha
1 | |
8.3 MQA
vmap for q , not k and v
1 | |
in_axes:None: Don’t map over k and v (k and v are shared across different q)0: Map over the 0-th axis of q (the batch dimension).`
8.4 batched MQA
vmap again for the new batch_size dimension
1 | |
9. multiple TPUs: use shard_map
1 | |
10. DMA: compute-data overlap
below is a memory copy kernel: tensor trip is HBM → VMEM → HBM
1 | |
pltpu.TPUMemorySpace.ANY- runtime decides where to place the top-level buffers
- we don’t really care about it, because kernel itself manages the VMEM staging manually
- we have to conservtively assume it’s in HBM, and manually schedule transfers into VMEM
pltpu.run_scopedallocates scoped resources and passes them intobody:x_ref,y_ref: (8, 128) f32 scratch buffers in VMEMsem: a DMA semaphore for synchronizing async copies. do things concurrently while we are waiting for memory transfersrun_scopedallocates semaphores with automatic lifetime management- creates semaphores → passes them to
body→ clean up afterward
- creates semaphores → passes them to
.wait()calls make this synchronous. in a real pipeline you’d overlap compute with async DMAs by deferring the waitsasync_copy()also works witgh SMEM- the values you get from SMEM can be used to schedule another DMA
- so it offers another degree of dynamism and sparsity
11. collectives w/ Pallas
in JAX, you may have seen some collectives
lax.psum(): sums a value across all devices in a named axis- similarly we have
lax.pmax()/lax.pmin()/lax.pmean()
- similarly we have
lax.all_gather(): each device starts with a small array and ends up with a large array containing concatenated datalax.all_to_all(): each device splits its input into chunks and sends one chunk to every other device (e.g., to change from DP sharding to TP sharding)lax.ppermute(): moves data along a fixed communication ring. You specify a list of(source_index, destination_index)pairs
here is a very simple ppermute() implemented with Pallas
1 | |
- assume you have a ring device topology, you may want to send your data to your left (or right) neighbor device
steps
- query the current axis index:
my_id = lax.axis_index('x') - then compute your neighbor index:
lax.rem(my_id + 1, num_devices) - sync btw you and your neighbor
pltpu.semaphore_signal(ready_sem)- tells the neighbor “I’m ready”
ready_semis aREGULAR(non-DMA) semaphore, used purely for sync
pltpu.semaphore_wait(): blocks until the neighbor has signaled back
async_remote_copy()- initiates a DMA transfer of
x_refon this device toy_refon the neighbor device - it returns two futures. two DMA semaphores (
send_sem,recv_sem) track completion of the send and receive sides independently
- initiates a DMA transfer of
- wait for completion
send_done.wait()andrecv_done.wait()block until the DMA has finished on both ends- assume we are transfering clockwise
send_done.wait(): you send to your right neighborrecv_done.wait(): your left neighbor sends to you
useful when you need custom compute-communication overlap
- e.g., pipelining KV-cache transfers with attention computation
or when the standard lax.ppermute / lax.all_gather don’t give you the scheduling flexibility you need for latency-sensitive serving