jax.jit, torch.compile & CUDA graph
1. jax.jit
jax.jittraces Python into computational graph (a jaxpr) → XLA compiles the graph into an optimized HLO program for the target device- After compilation, Python is completely out of the loop. There’s no interpreter overhead, no per-op dispatch.
- XLA also does heavy optimization: operator fusion, memory layout planning, scheduling.
- On TPU this is especially impactful because XLA is the only way to talk to the hardware. There’s no eager fallback that’s performant.
2.torch.compile
torch.compile(withtorch.dynamo+torch.inductor) is conceptually similar.- It traces a PyTorch function into a graph and compiles it, but the implementation is very different.
- Dynamo captures at the Python bytecode level, handles graph breaks (falling back to eager when it can’t trace something), and the backend (Inductor for GPU) generates Triton kernels rather than going through XLA.
- It’s more flexible but messier. It has to deal with PyTorch’s mutable tensor semantics, in-place ops, and dynamic control flow in ways JAX simply avoids by design.
3. CUDA graphs
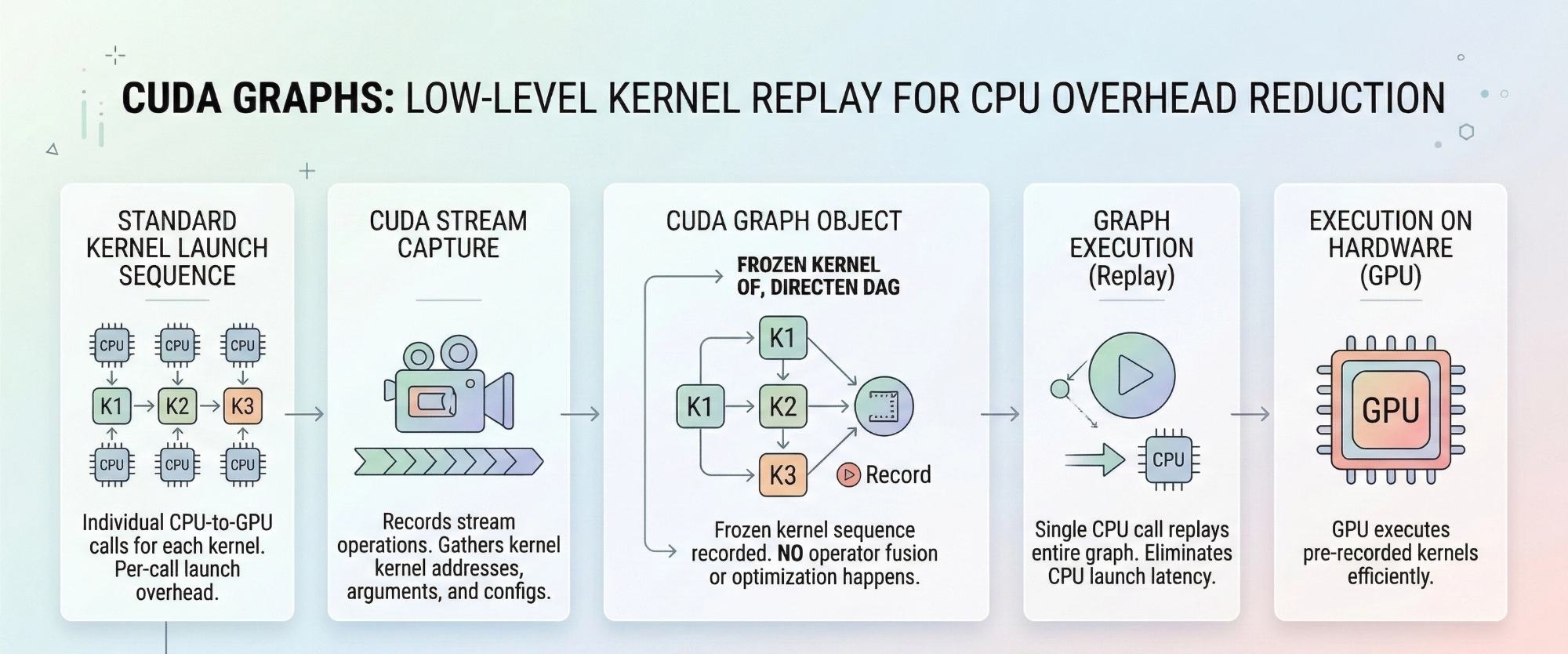
- CUDA graphs are a much lower-level concept.
- They record a sequence of already-compiled GPU kernel launches (with their exact memory addresses) and replay them.
- There’s no operator fusion or optimization happening. You’re just eliminating CPU-side launch overhead.
- Think of it as “record the driver calls and replay them.” It’s very restrictive (fixed memory addresses, no dynamic shapes, no CPU-dependent branching).
4. Summary
jax.jit= tracing + full compiler optimization + dispatch elimination (all three)torch.compile= tracing + compiler optimization + dispatch elimination (all three, but with graph breaks as an escape hatch)- CUDA graphs = dispatch elimination only (no optimization, just replay)
jax.jit, torch.compile & CUDA graph
https://gdymind.github.io/2026/03/07/jax-jit-torch-compile-CUDA-graph/