KV cache in sliding-window attention
1. Longformer
https://arxiv.org/abs/2004.05150
- it was the 1st sliding-window attention (SWA) paper. published in 2020
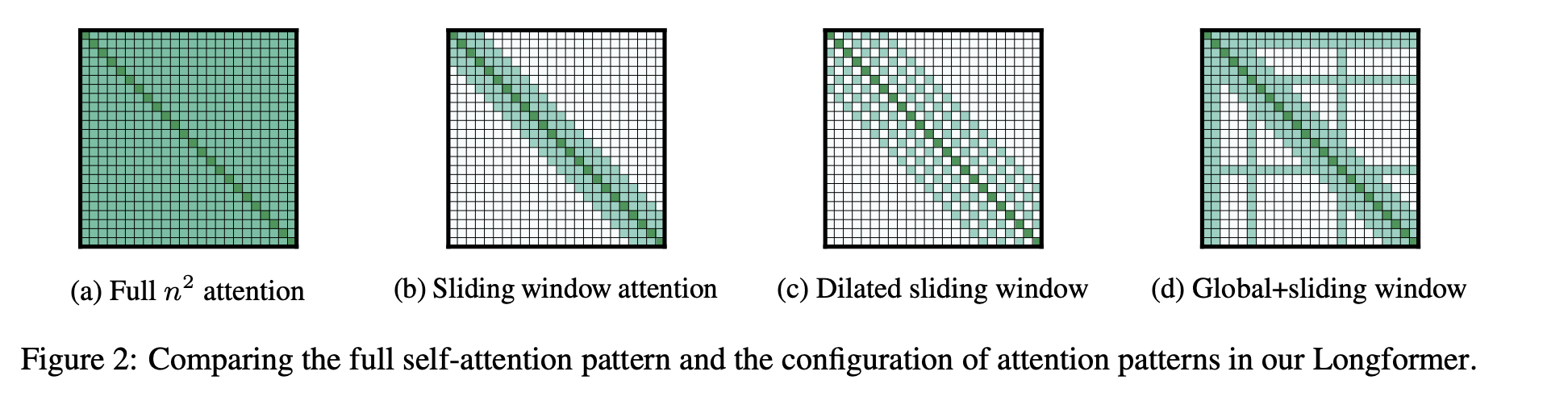
- traditional full attention: compute complexity $O(n^2)$, memory $O(n^2)$, where $n$ is seq len
- SWA: compute complexity $O(nw)$, memory $O(nw)$, where $w$ is window size
- receptive field of the top layer = $lw$, where $l$ is # of layers
- activations are still $n\cdot d$ (where $d$ is the hidden dimension), but we only need to keep the last $w$ tokens’ KV cache (shape
wxdfor each K / V)
2. Gemma2: local-global hybrid attention
https://arxiv.org/abs/2408.00118
- Local sliding window and global attention
- alternate local and global in every other layer
- local window size = 4k; global context limit = 8k
- Post-norm and pre-norm with RMSNorm
- Logit soft-capping
- in each attention layer and the final layer
- value of the logits stays between −soft_cap and +soft_cap
- Grouped-Query Attention
KV cahce in different phases
| Phase | Global layer | Local layer |
|---|---|---|
| Prefill | computed: all tokens (nxd); stored: all tokens (nxd) |
computed: all tokens (nxd); stored: last w tokens (wxd) |
| Decode | computed: last token (1xd); stored: last token (1xd) |
computed: last token (1xd); stored: last token (1xd); removed: 1st token in the window (1xd). as a result, window size remains constant |
KV cache in sliding-window attention
https://gdymind.github.io/2026/03/02/sliding-window-attention/