XLA01 - architecture & workflows
0. Intro
XLA in the whole JAX stack

Source: Yi Wang’s linkedin post
- LLM is basically matmul. XLA (Accelerated Linear Algebra) optimizes linear algebra on multiple decives (TPU / GPU)
- XLA works with n-d arrays of the same data type
- XLA compiler: model code (PyTorch, JAX, Tensorflow) → optimized machine instructions on GPU / TPU / CPU, etc.
- XLA uses MLIR (Multi-Level Intermediate Representation) to build a single compiler toolchain
- MLIR is a hybrid IR infra that allows users to define “dialects” of opes at varying degrees of abstraction and gradually lower between these opsets
- MLIR performs transformations at each level of granularity
- StableHLO and CHLO are two examples of MLIR dialects.
- Example of XLA ops: Add / Abs / AllToAll / AllReduce / CollectivePermute / Sort …
1. XLA input: StableHLO
- model graphs is defined in StableHLO, which is XLA’s input
- HLO = high level operations
- an internal graph representation (IR) for the XLA compiler
- “internal dialect” used by the XLA compiler to perform optimizations
- not designed to be stable. may change frequently
- StableHLO = public-interface HLO
- a portability layer or “bridge” between ML frameworks (JAX / PyTorch) and the compiler
- ML frameworks that produce StableHLO programs are compatible with ML compilers that consume StableHLO programs
- versioned op set of HLOs → model graphs remain valid even as the underlying compiler evolves
- provide backward and forward compatibility
2. XLA workflows
- StableHLO → internal HLO dialect: target-independent optimization on StableHLO. examples
- common subexpression elimination
- target-independent op fusion
- buffer analysis: allocate runtime memory
- HLO sent to backend: target-specific optimization
- example: GPU may optimize op fusion for CUDA streams
- Target-specific code generation: done by backend
3. HLO to excutable (GPU)
- The journey from initial HLO all the way to machine executable
- Depends on the context, HLO can refer to “HLO modules”
- Thunk: a self-contained unit of work that the runtime executes
- LLVM: compiler backend, and a language that it takes as an input
- many compilers generate LLVM code as a first step, and then LLVM generates machine code from it
- allows reusing code that is similar in different compilers
3.1 Pre-optimization HLO
- Pre-optimization HLO: no interal XLA ops (like
fusionandbitcast) included - Ops don’t have a layout at this stage. Or if they do, it will be ignored
- produced by JAX / pytorch
- use
-xla_dump_toXLA flag to dump Pre-optimization HLO to a file ended withbefore_optimizations.txt
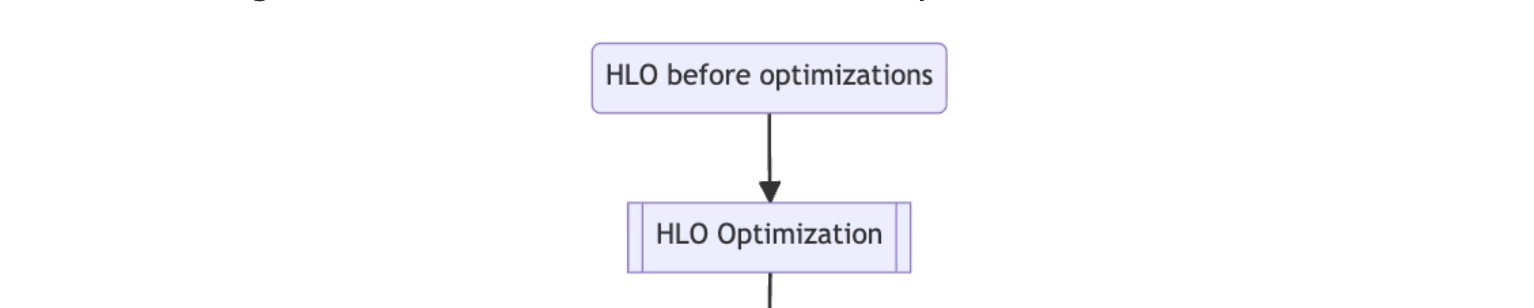
3.2 optimize HLO Module
XLA GPU vs TPU pipeline
| Feature | XLA:GPU Pipeline | XLA:TPU Pipeline |
|---|---|---|
| Lowering Target | Thunks & LLVM IR | TPU-specific Machine Code (Binary) |
| Code Generation | IrEmitterUnnested + LLVM (PTX/HSACO) | Proprietary TPU Compiler Backend |
| Runtime Abstraction | ThunkSequence | TpuExecutable (often via PJRT) |
| Optimization Focus | Kernel fusion, memory coalescing | Systolic array utilization, interconnect scaling |
here we only introcuces XLA:GPU pipeline
pre-optimization HLO → optimized HLO is done by serveral passes
passes execution orders:
- sharding related passes: some passes uses Shardy
- optimization passes: legalization and simplification passes
- collective optimization passes: similar to step2, but for collective ops
- layout assignment passes: each HLO op has a layout like
f32[10,20,30]{2,0,1}→ control how tensor is sotored in memory- layout format: element type, logical dimensions of the shape, layout permutation in minor to major order
- goal: minimize # physical transpositions
- propagate layouts “down” and “up” the graph (w/ certain constraints)
- may have conflicting layouts (one from an operand, one from a user)
copywill be added for conflicting layouts
- layout normalization passes
- try to rewrite shape to default layout
{rank-1, rank-2, …, 0} copy(that changes layout) is rewritten astranspose+bitcast- bitcast: a transpose with a layout that makes it a no-op physically
- some ops may still have non-default layouts, most notably
gatheranddot
- try to rewrite shape to default layout
- post layout assignment optimization passes
- Triton fusions (GEMM fusions + Softmax/Layernorm fusions) or rewrites to library calls.
- autotuning: e.g., finds the best tiling for fusions
- fusion passes:
PriorityFusion+Multi-Outputfusion- PriorityFusion: fusions guided by the cost model
- fusing ops/fusions that share an operand
- common subexpression elimination
- several post-fusion passes
- turning them to async, or enforcing a certain relative order of collectives, ect.
- CopyInsertion: add copies to ensure that in-place ops don’t overwrite data needed elsewhere
if adding -xla_dump_to XLA flag, you’ll see a file ended with after_optimizations.txt
3.3 scheduling
- for the HLO graph, any topological sort order is valid
- scheduling determines the actual orders
- goal: reduce peak memory given the tensor lifetime

3.4 buffer assignment
- assign buffer slices to each instruction in the HLO graph
- this happens right before lowering to LLVM IR
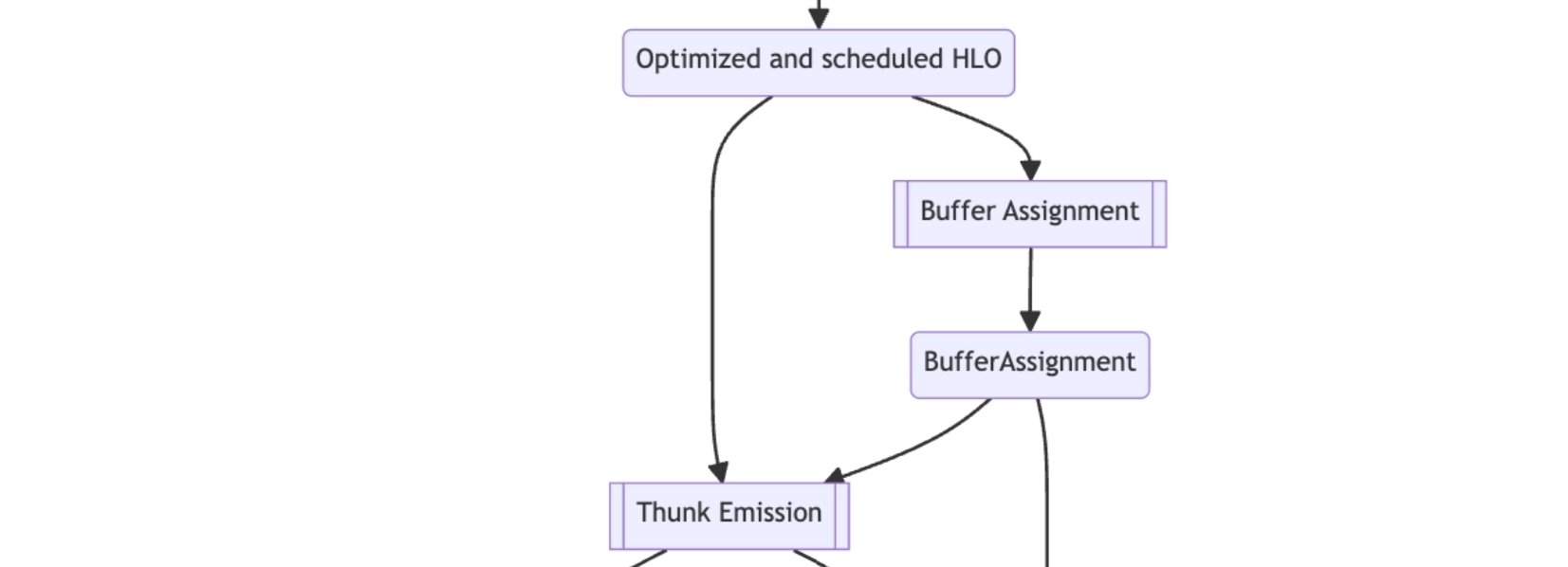
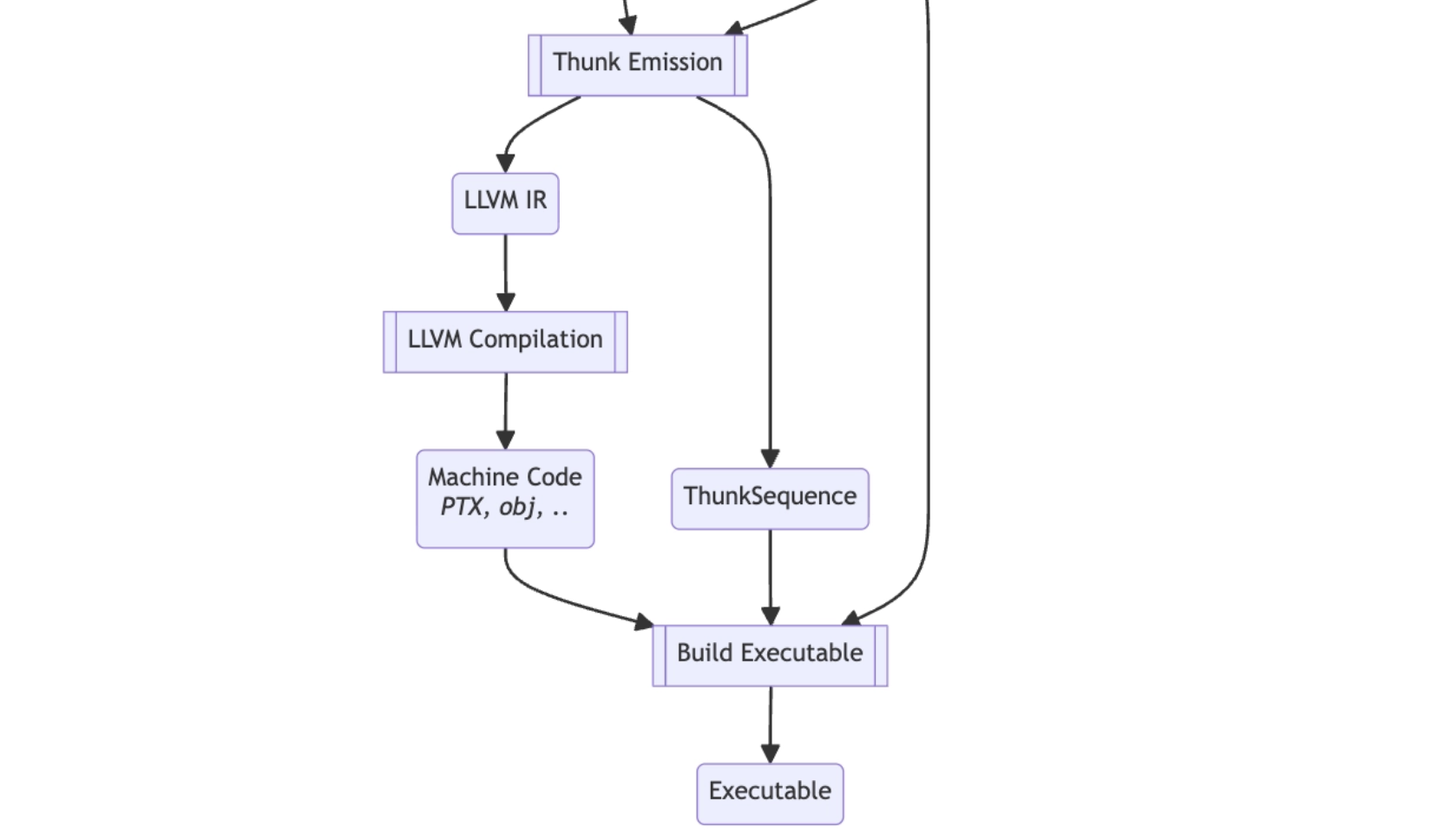
3.5 thunks
- lower HLO graph to a seq of thunks for a specific backend (CPU or GPU)
- Thunk: self-contained executution unit
- compiled kernel launch
- specific op
- library call
- control-flow construct
- collective communication
- …
- thunk emission: scheduled HLO → thunk sequence
- command buffers: optimizing GPU execution
- CUDA graph: we can record a seq of GPUs ops (kernel launches, mem copies, etc) to reduce CPU overhead
- command buffer: abstraction of CUDA Graphs or HIP Graphs
3.6 executable
- final product: bridge btw compiler and runtime
- includes all the info needed to run the compiled program on a target device (CPU / GPU)
- modern runtimes like PJRT use slightly higher-level abstractions (see PjRtExecutable), but these ultimately wrap a backend-specific executable
- what’s included?
- compiled code
- CPU: object files
- GPU: PTX or HSACO code
- execution Plan (ThunkSequence)
- memory layout (BufferAssignment)
- (optional) final, optimized HLO Module: for debugging and profiling
- compiled code
XLA01 - architecture & workflows
https://gdymind.github.io/2026/02/25/XLA01-architecture-workflows/