Truncated Importance Sampling (TIS) in RL
truncated importance sampling (tis)
this blog is from feng yao (ucsd phd student)’s work. i added some background and explanations to make it easier to understand.
slides: on the rollout-training mismatch in modern rl systems
notion blog: your efficient rl framework secretly brings you off-policy rl training
veRL/OpenRLHF/Slime adopts hybrid engines
- rollout: advanced LLM inference engines (vLLM, SGLang)
- training: modern LLM training backends (FSDP, Megatron)
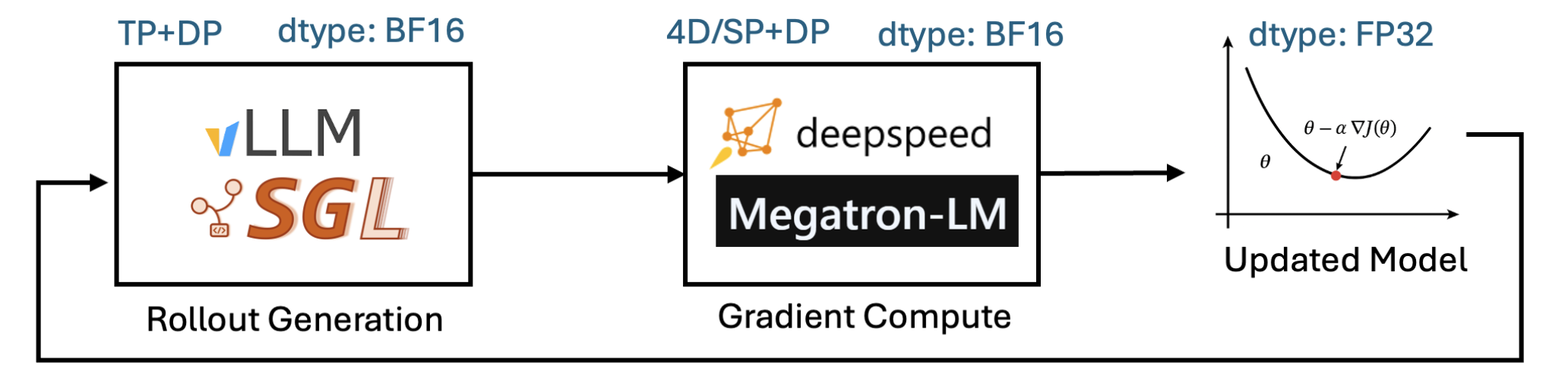
the logprob produced between sampler (vLLM, SGLang, etc.) and trainer (DeepSpeed, Megatron-LM, etc.) are not exactly the same.

formula explanation:
: weights; : learning rate : policy function, which is the token distribution from the LLM : action, which is the token that LM generates : the token generated following the distribution of the LLM : reward : gradient : the average reward-weighted policy gradients (follow the LLM distribution)
now the policy function is mismatched between the training (
) and inference ( ) engine. this makes RL off-policy. why does rollout-training mismatch occur?
- two common beliefs
- inaccessible true sampling probabilities: add additional gap
- during rollout, the model generates tokens by sampling from its probability distribution, but during training, we cannot precisely access the true probability with which each token was sampled.
- vLLM v1 engine didn’t support directly returning the adjusted probabilities used for sampling, introducing an additional gap (now it’s fixed)
- backend numerical differences: hard to fix
- inaccessible true sampling probabilities: add additional gap
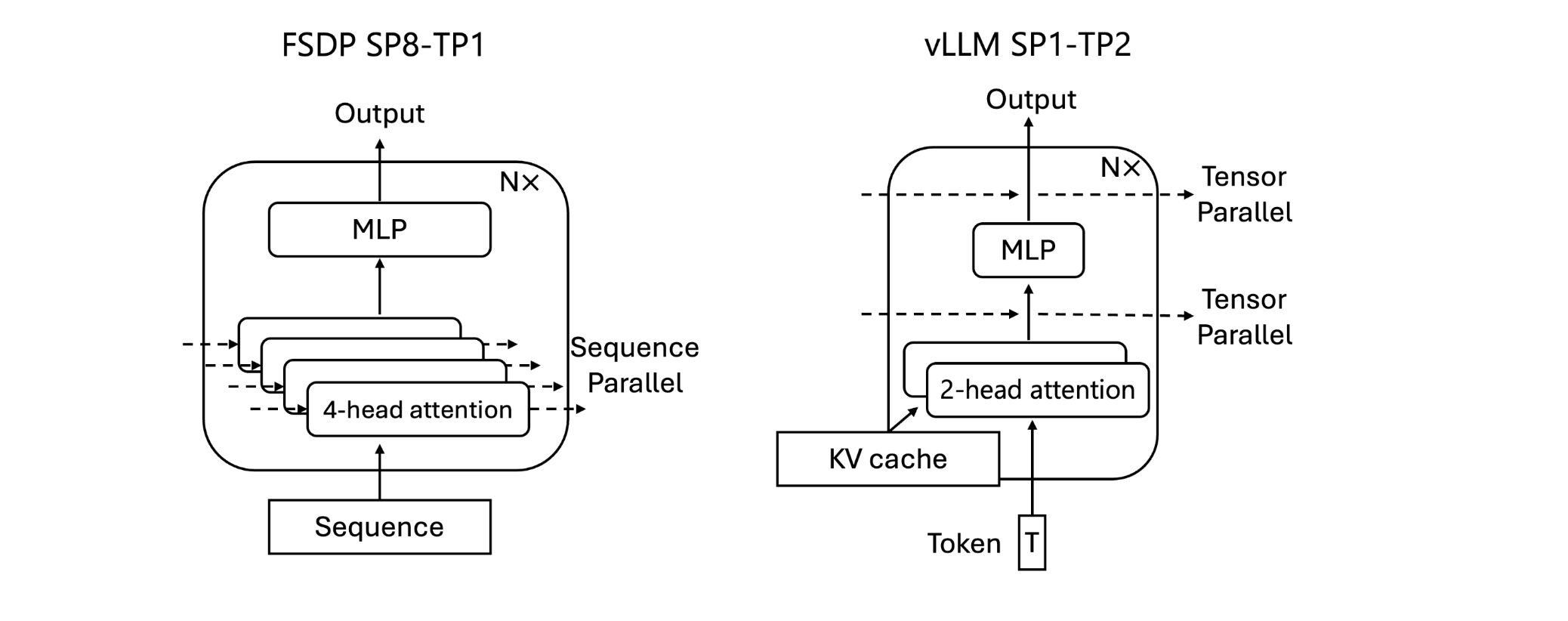
- hybrid engine & error propagation: different compute patterns via different backends & parallelism
- the vanilla importance sampling: use the ratio between trainer and sampler’s probability as part of the weights

- the importance ratio can be too large and makes the training crash. in practice, we cap the importance ratio to make it more stable
- two common beliefs
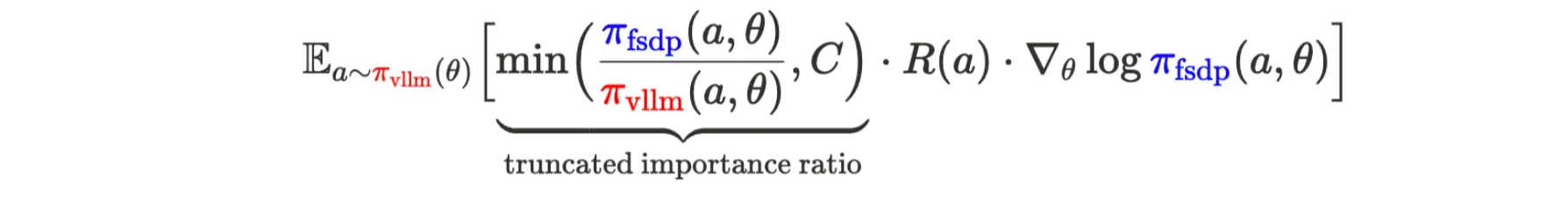
Truncated Importance Sampling (TIS) in RL
https://gdymind.github.io/2025/11/08/Truncated-Importance-Sampling-TIS-in-RL/