MoE history and OpenMoE
Intro
This article is compiled from a livestream.
The guest speaker is Fuzhao Xue, a Google Deepmind Senior Research Scientist and the author of OpenMoE
- Main research areas: Gemini Pretraining, Model Architecture, and Multi-Modal LLM
- Key works: OpenMoE, Token-Crisis, AdaTape, Sequence Parallelism, and LongVILA.
Fuzhao: Seven Takeaways in My PhD
- Engineering is the foundation of research.
- Working with talented individuals is incredibly helpful for improving research taste.
- Aim for a concise and insightful 45-minute presentation rather than a long publication list throughout the PhD.
- Focus on a few key papers and understand them deeply rather than skimming many.
- When onboarding to a new topic, reading papers along the timeline to study the evolution of research trends.
- “supervised practice”: what would I do next based on the current paper?
- Transposition thinking is a highly effective way to improve writing and presentation.
- A PhD degree is helpful but not a prerequisite for a career in LLM research.
OpenMoE
The original MoE
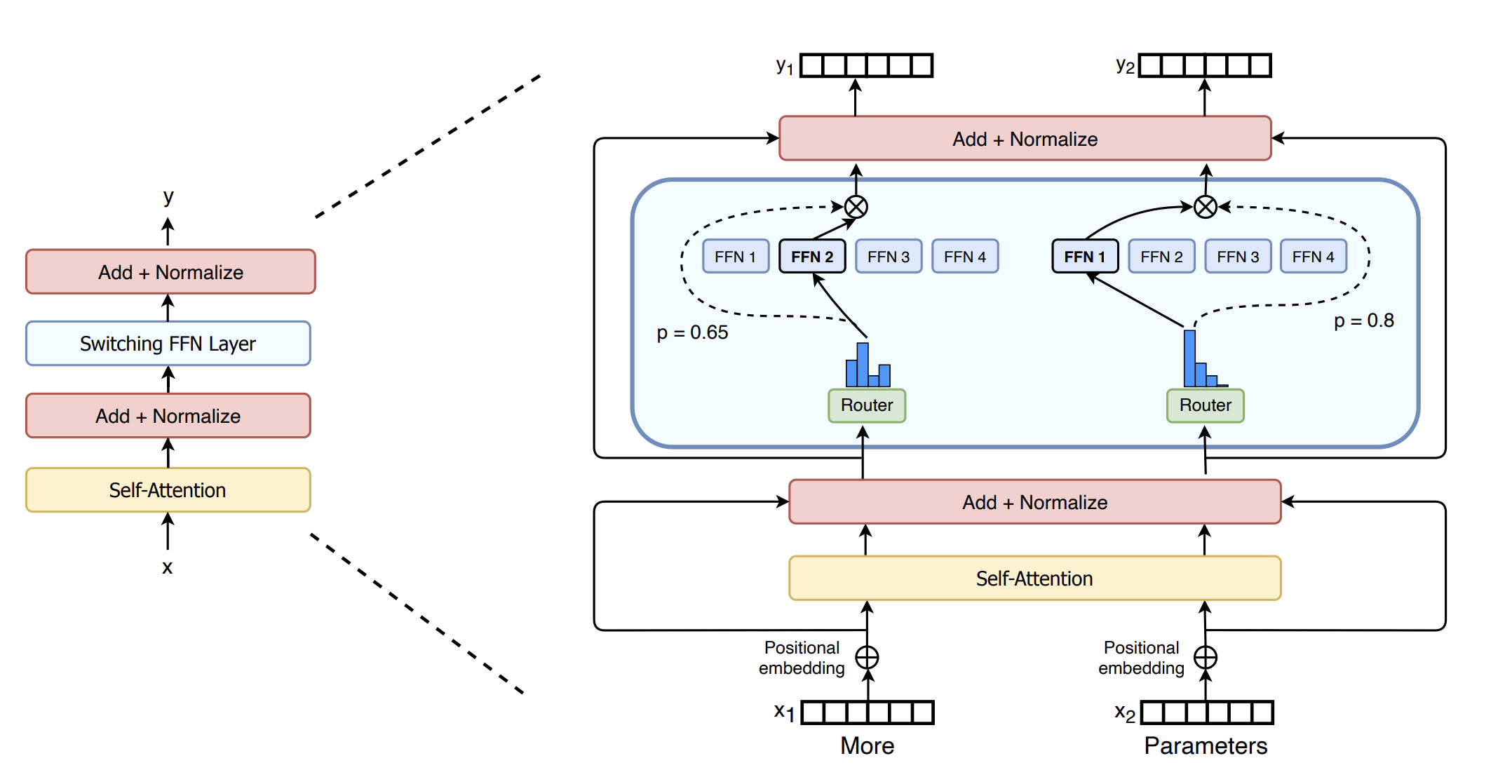
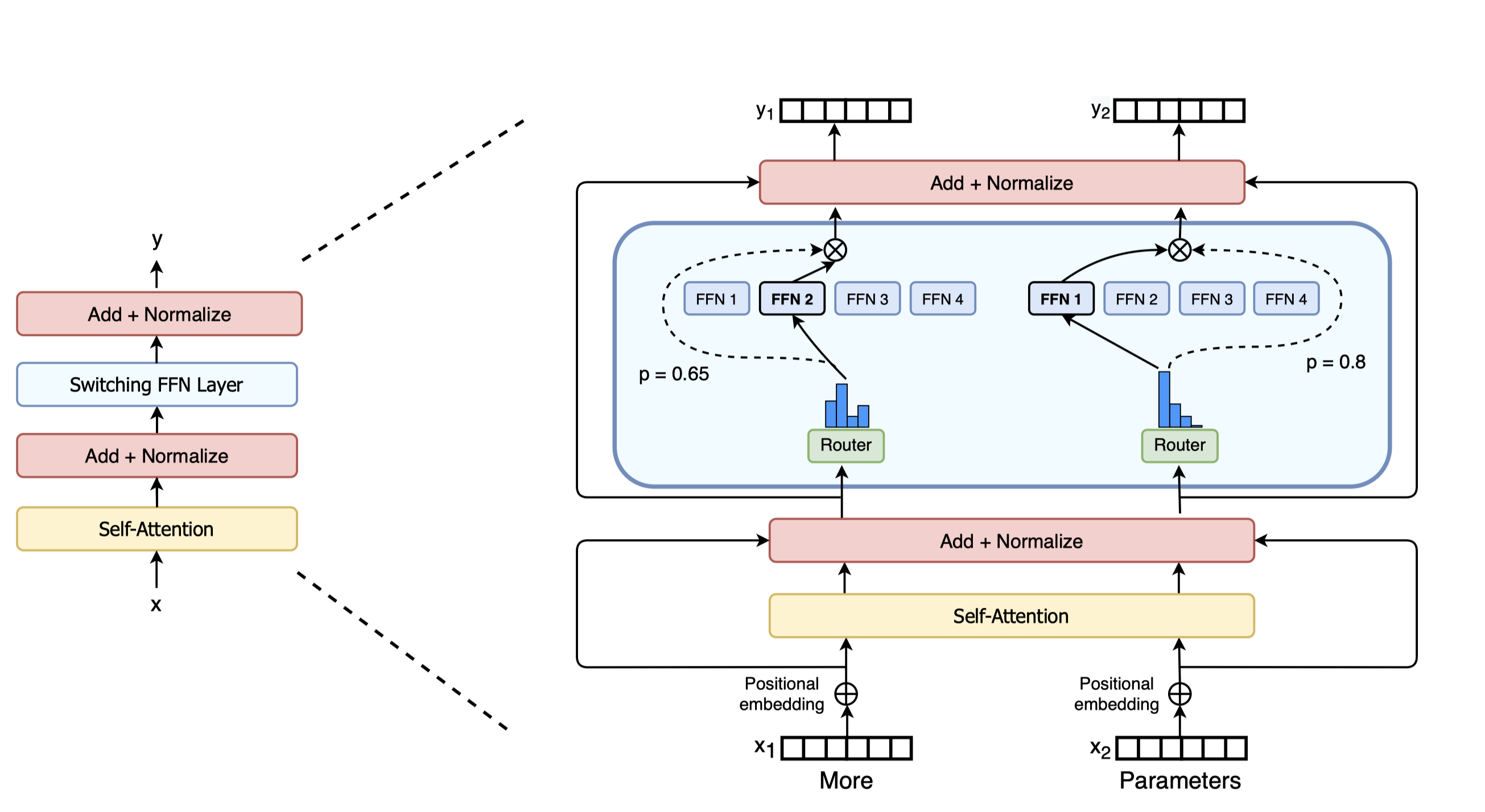
Common misunderstanding: MoE is a mix of many models
Actually, it’s a single model with multiple experts in a FFN layer
Router decides which experts to activate
Router is a simple linear layer doing dot product
Figure from Switch Transformers (2022)
https://arxiv.org/abs/2101.03961
History of MoEs
2017: LSTM + MoE
Gating network
- Naive hard selection is not differentiable.
- This work used some tricks to make it differentiable.
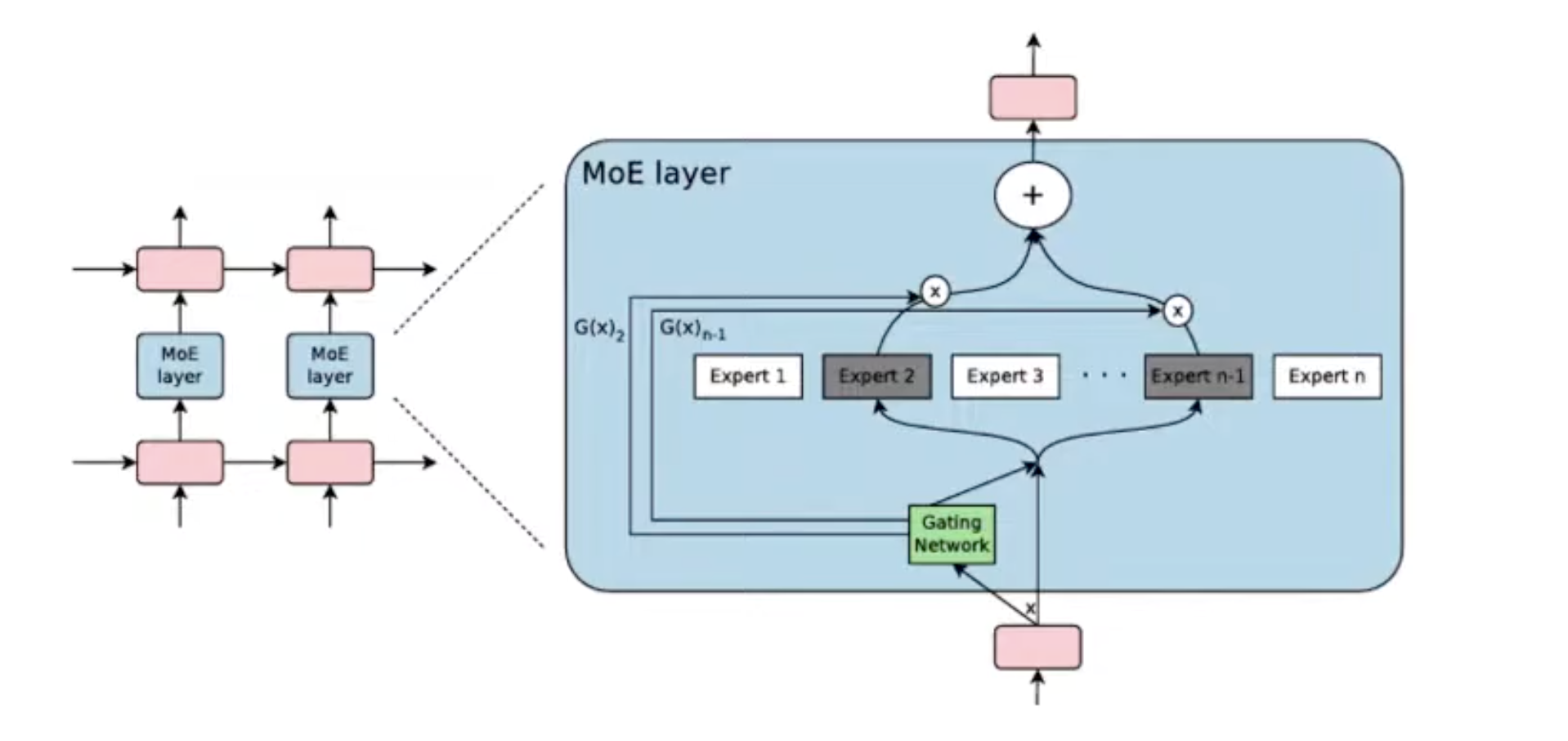
2021: Gshard from Google (MLSys)
MoE: increase # parameters without increasing FLOPs → more sparse → more memory
Expert parallelism: different E on different GPUs
introduces extra all-to-all communication overhead
2021: Switch Transformer
The first open-source MoE. Very important work.
Built atop T5. Because T5 is too large, not many ppl used it.
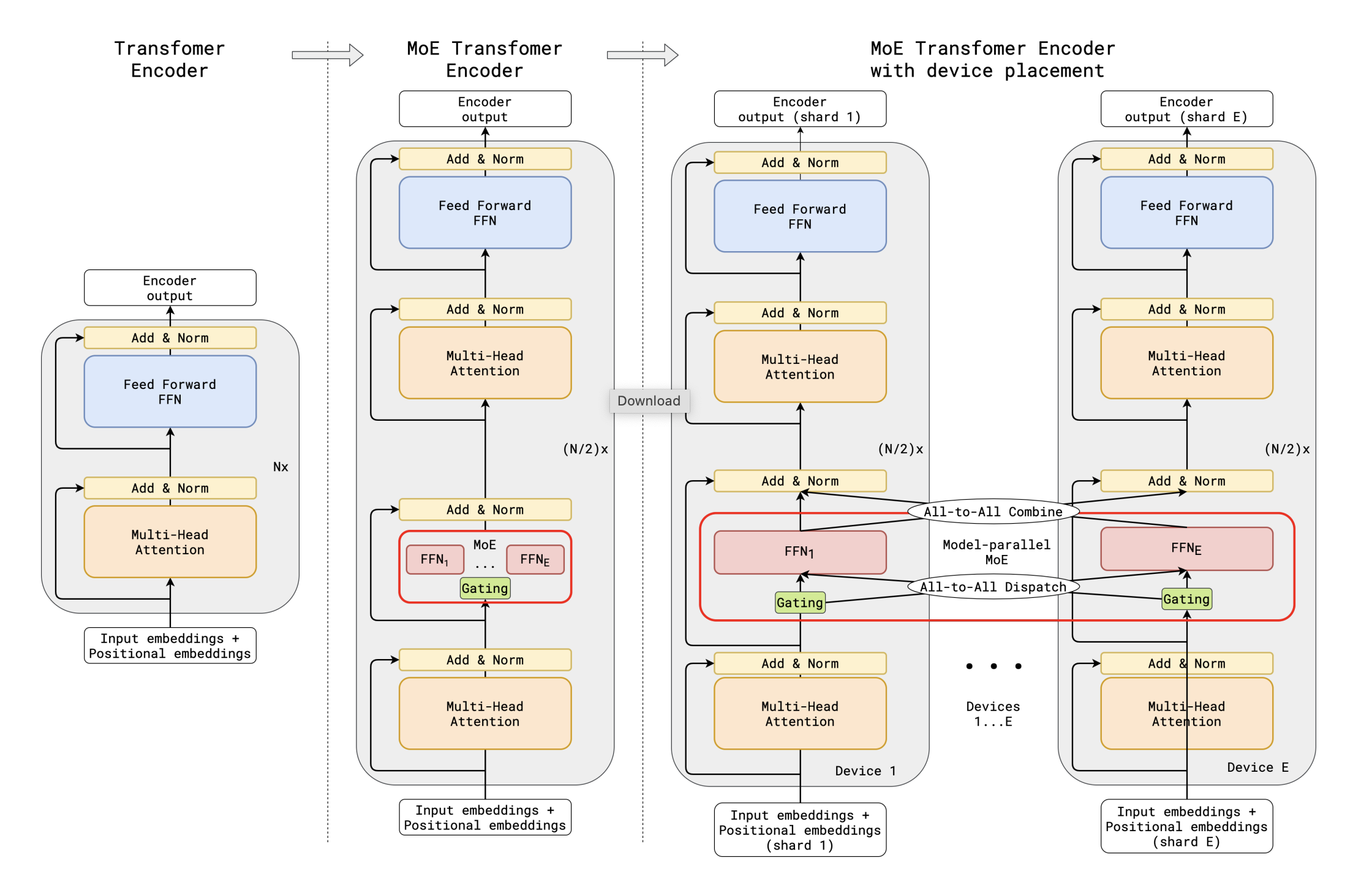
Later works: GLaM, ST-MoE…
Awesome-mix-of-experts: 10 must-read papers https://github.com/XueFuzhao/awesome-mixture-of-experts
Google did lots of works at that time.
2023: OpenMoE → a family of open-sourced MoE models
GPT4 used MoE
Why Fuzhao chose MoE then: when scaling up, MoE still worked well
Trained for one year on TPU.
performance is so so nowadays. The main contributions are insights with visualizations.
MoE will be more popular as it’s cost-effective. vLLM is trying to support MoE more efficiently
Summary
- 2017: LSTM + MoE
- 2021: Gshard (MoE MLSys)
- 2021: Switch Transformer (MoE)
- GLaM, ST-MoE
- 2023: OpenMoE, Mixtral
- 2024: DeepSeek-MoE, OLMoE https://github.com/allenai/OLMoE?tab=readme-ov-file
- 2025: LLaMA-4
MoE was hard to train
Formal definition
Given E experts:
where
Usually, both
TopK selection
To ensure sparse routing TopK() is used to select the top ranked experts.
The formula shown is:
where
Balanced loading
EP: if one expert is hot out of 4, 3 GPUs are often idle → 3 E are wastes of weights
An unbalanced token assignment can reduce the MoE model’s throughput and performance.
To prevent this, two issues need to be avoided:
- Too many tokens being sent to a single expert
- Too few tokens being received by a single expert
1. Too many tokens being sent
To address the first issue, they define a buffer capacity B:
Where:
is the capacity ratio is the number of selected experts per token is the batch size on each device is the sequence length
For each expert, they preserve at most B tokens regardless of how many tokens are dispatched to that expert.
2. Too few tokens being received
To solve the second issue, the following auxiliary loss is added to the total model loss during training:
m_i: the fraction of tokens dispatched to expertiP_i:the softmax output for the i-th expert inside the router (i.e., a probability value).
L: Total number of tokens (batch size × sequence length).h(x_j)_i: For the j-th token, it indicates whether the token is dispatched to expert(1 if yes, 0 otherwise).
So m_i is:
- Counting how many tokens are routed to expert i,
- Then normalizing by the total number of tokens, resulting in the fraction of load on expert i.
m is non-differentiable. Therefore, we define a differentiable P_i as:
When we minimize l_{balance}, we can see both m and P would be close to a uniform distribution.
Note: P_i is the input of Top K within router g()
At that time, MoE can save 50% FLOPs. Now maybe it can be better.
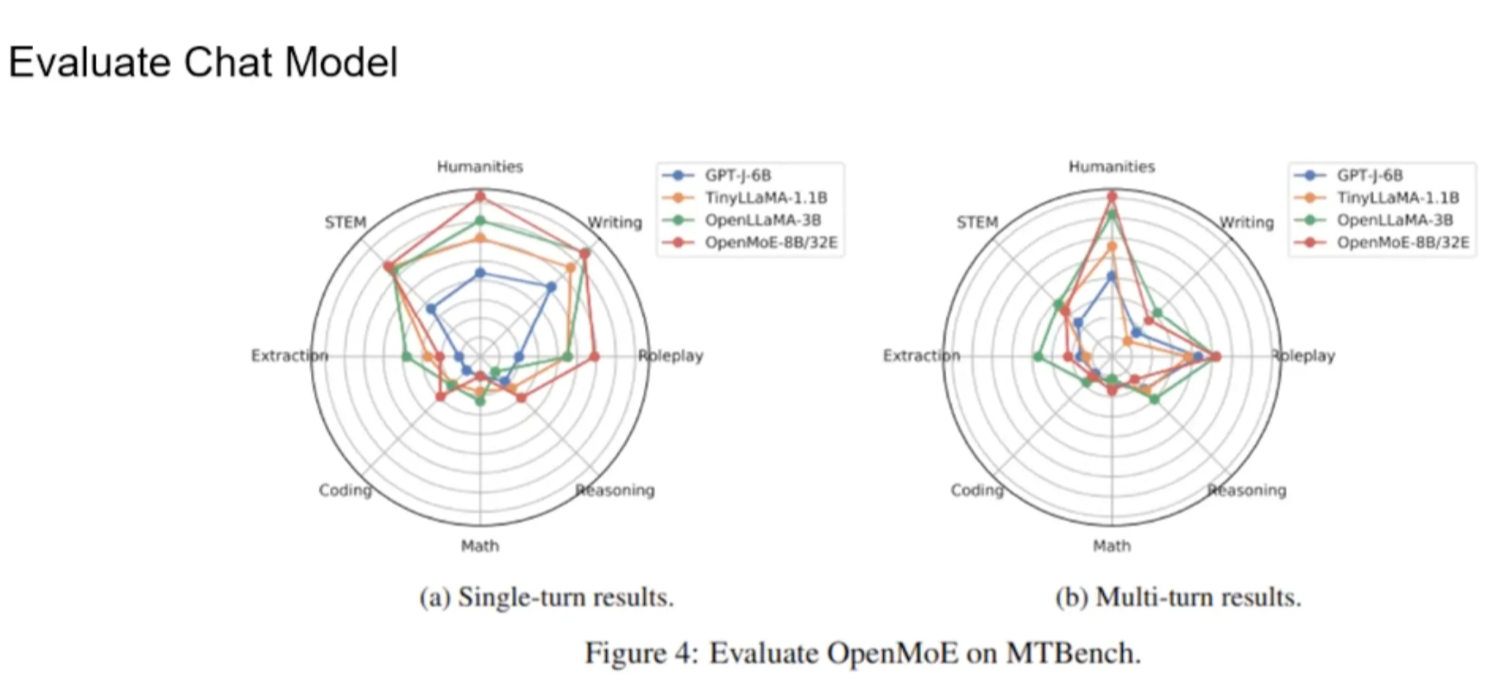
Training on MoE: multi-turn is worse??
MTBench: an early multi-turn conversation benchmark.
multi-turn results are worse than single-turn results. Similarly, few shot is worse than zero shot. The reason will be discussed later
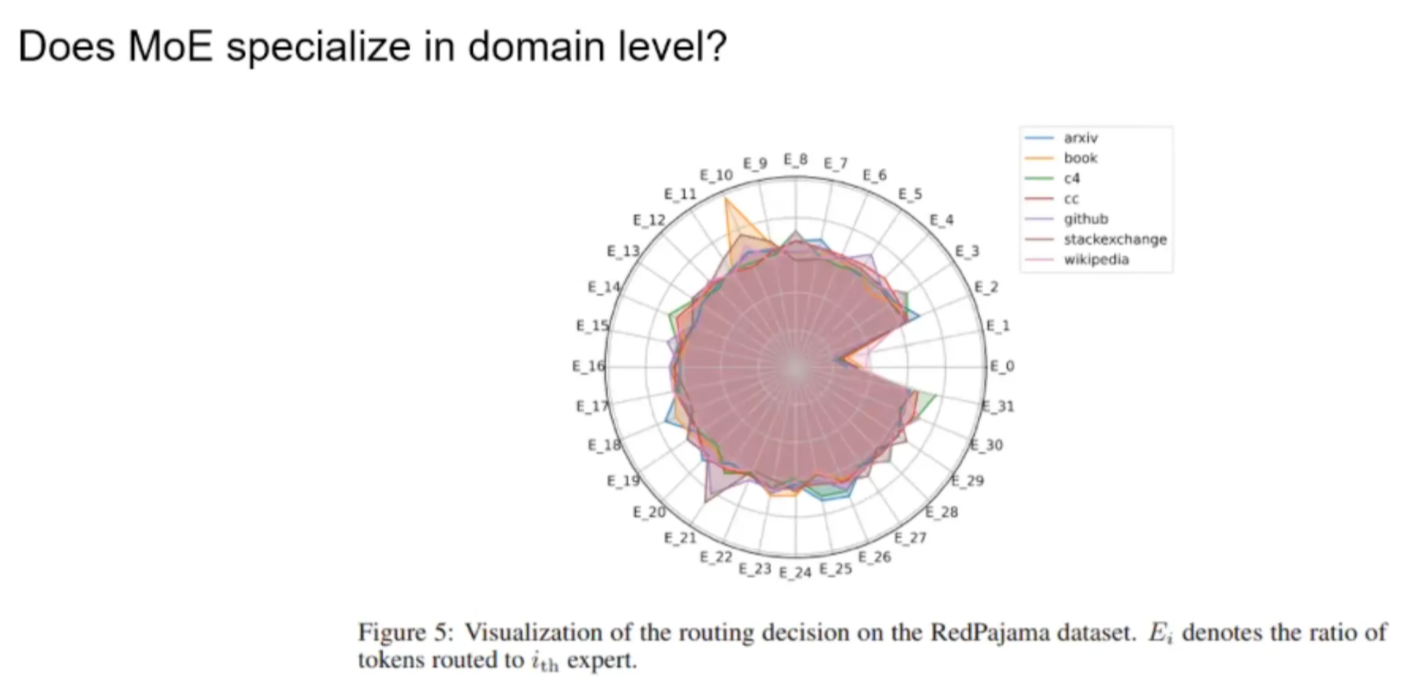
Does MoE specialize?
Domain level? No specialization. Tokens are dispatched to different E uniformly.
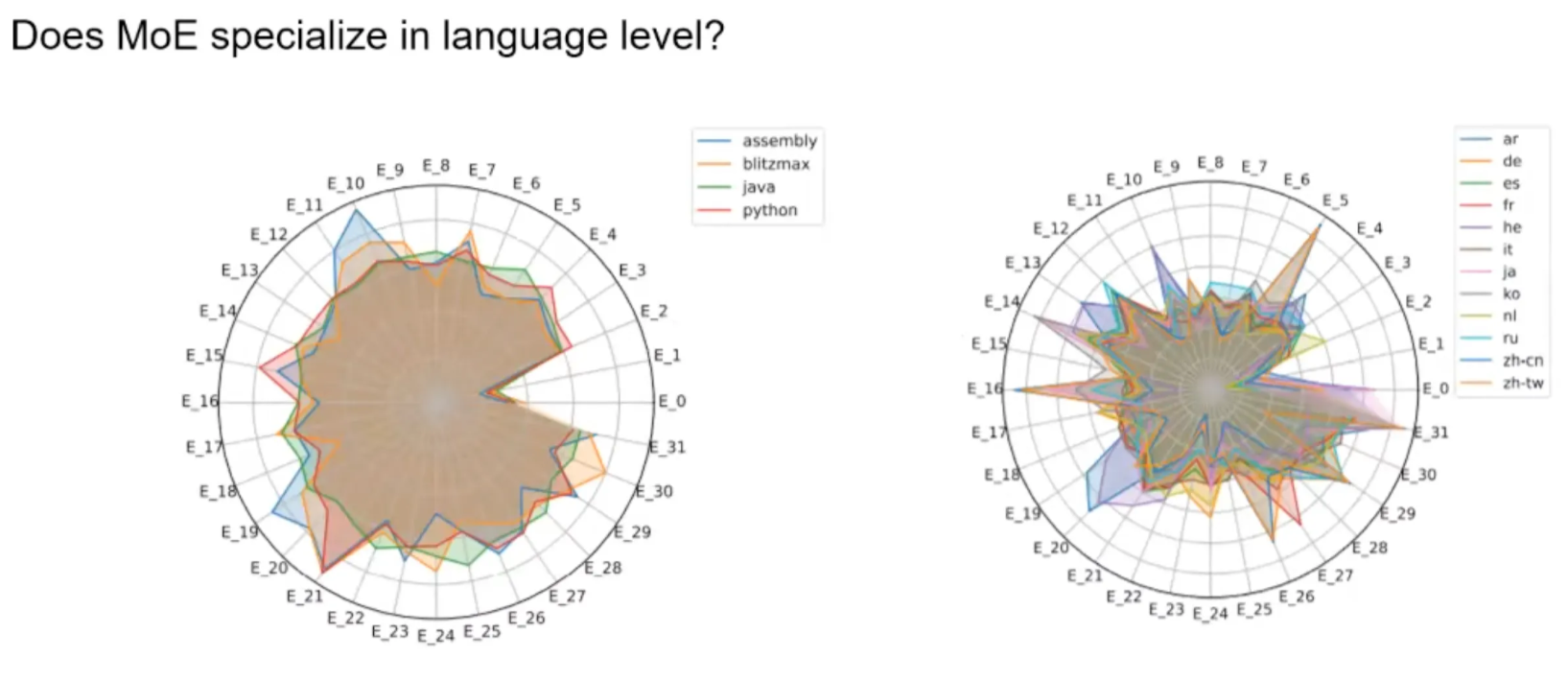
Coding language? No
Natural language? To some degree, yes. Also similar languages to similar Es.
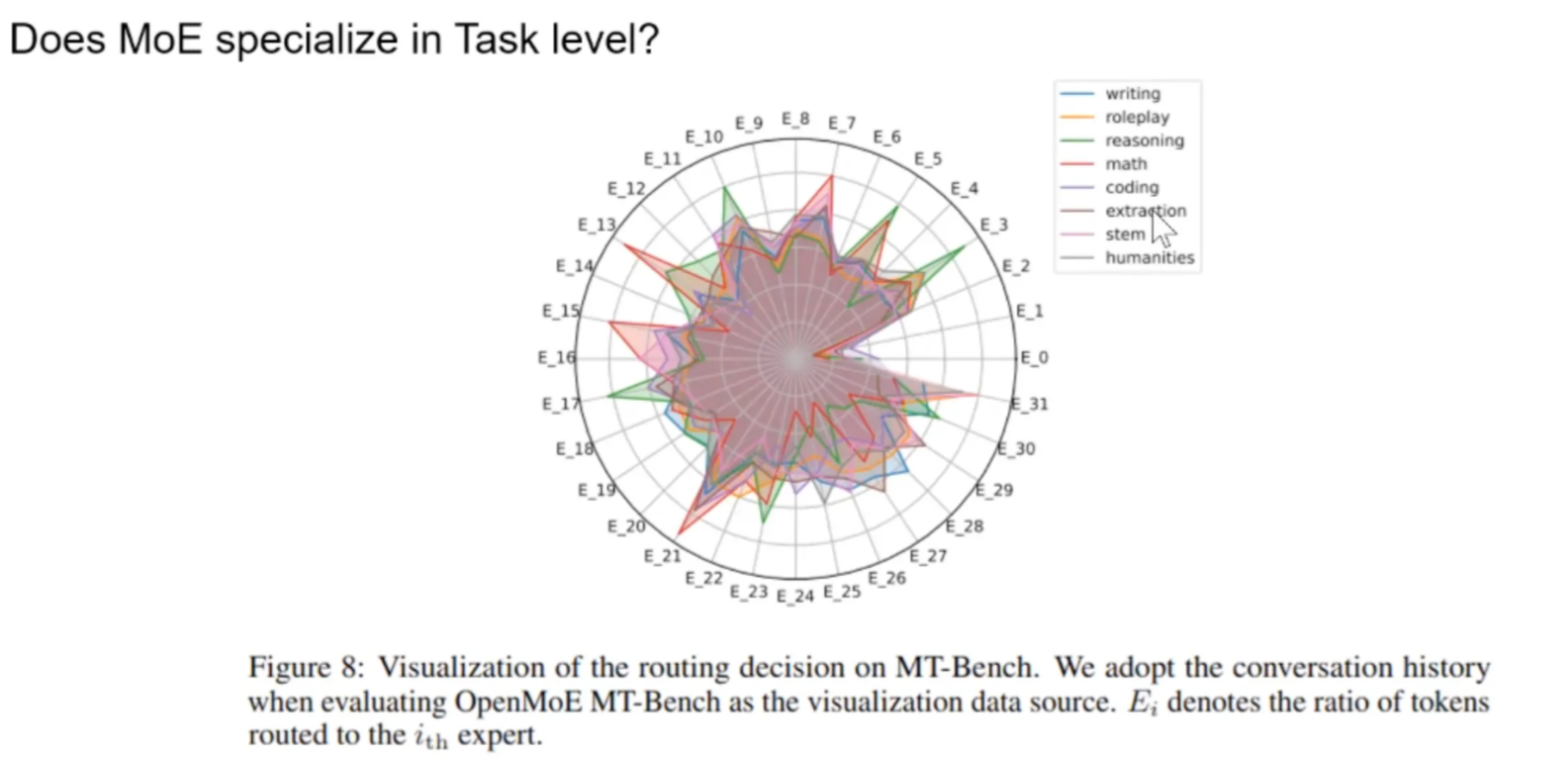
why some E are served for many tasks.
- one possible case is that E handles system prompts
is MoE just lazy and dispatching based on positions? No clear pattern.
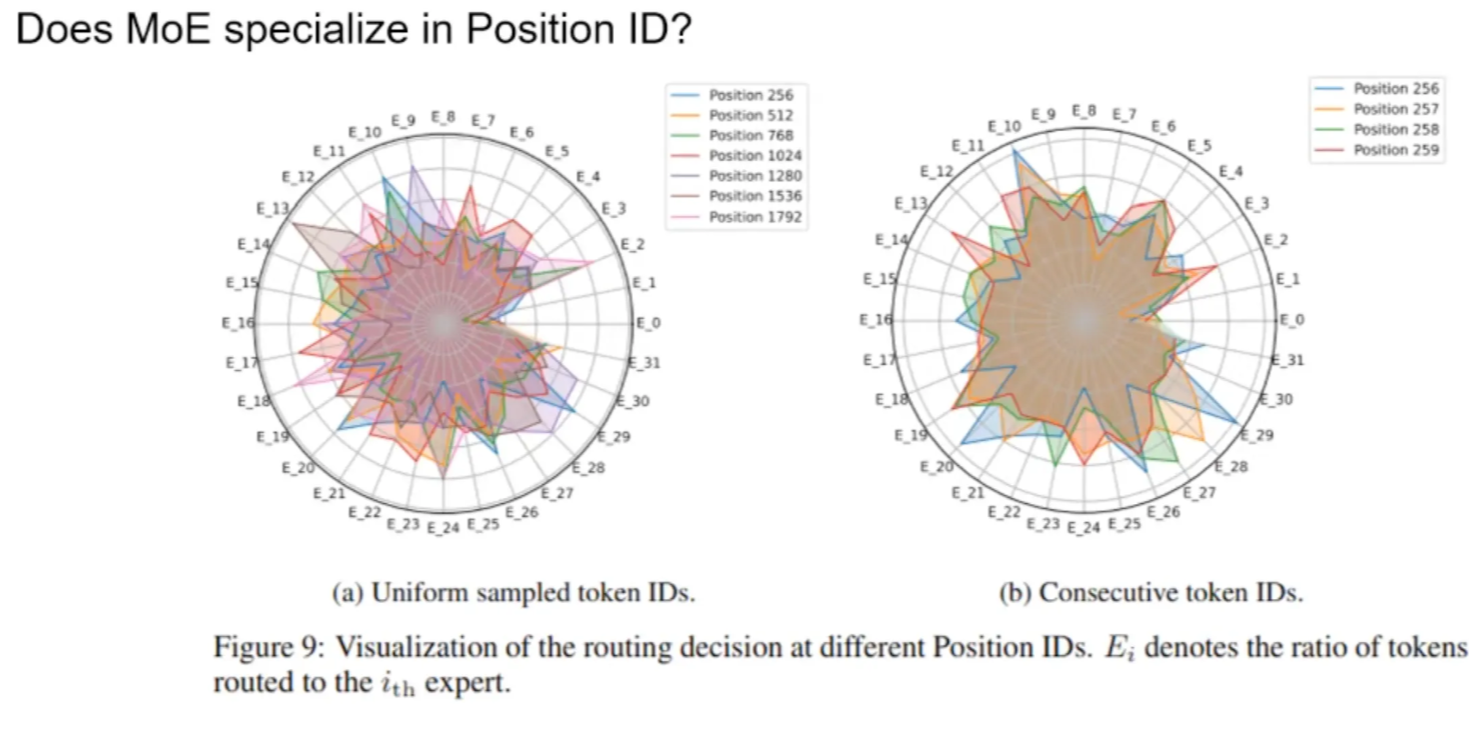
Context-independent specialization
Specialize in Token ID? YES
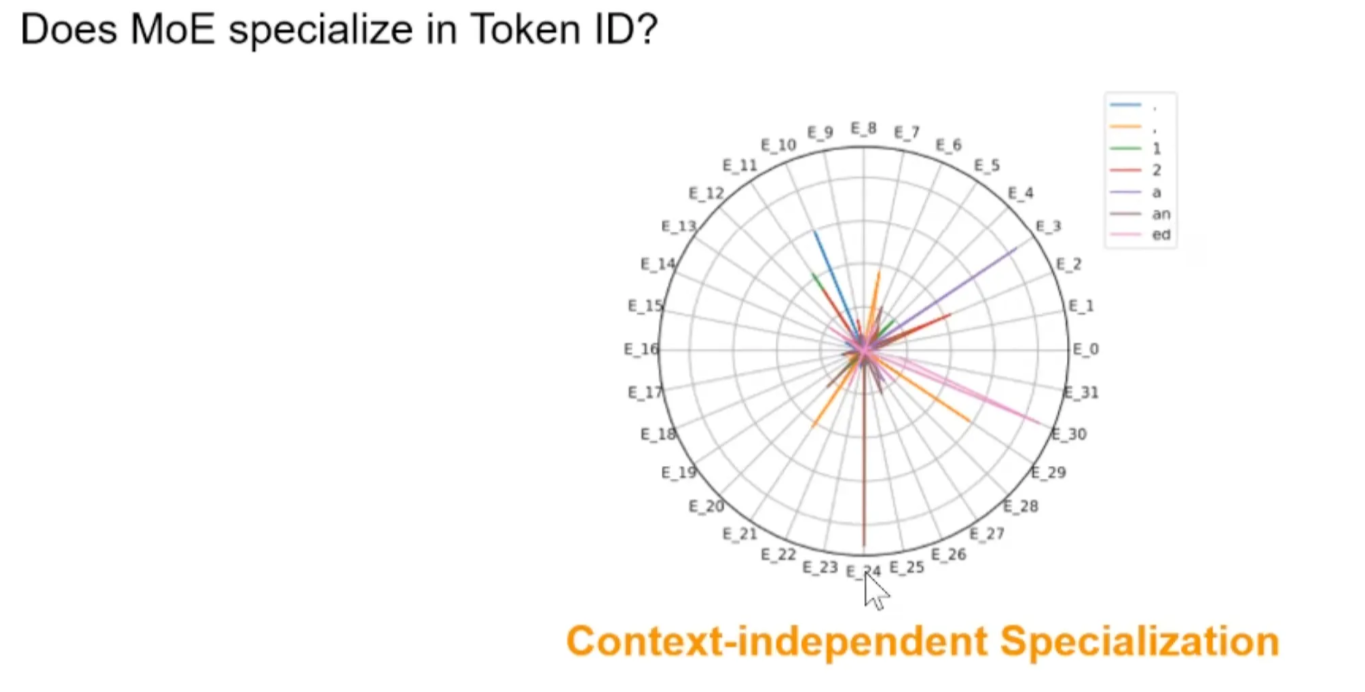
router is just a linear layer. Not learning high-level things. Just routing based on token IDs.
Deepseek V2 is also like this. Deepseek V3 is not tested yet.
From audience: Deepseek R1 has no token specialization
Are experts clustering similar tokens?
Yes

E21 likes coding tokens
E31 likes modal verbs
E0 and E1 like garbage \n
Why Context-independent? Early routing learning
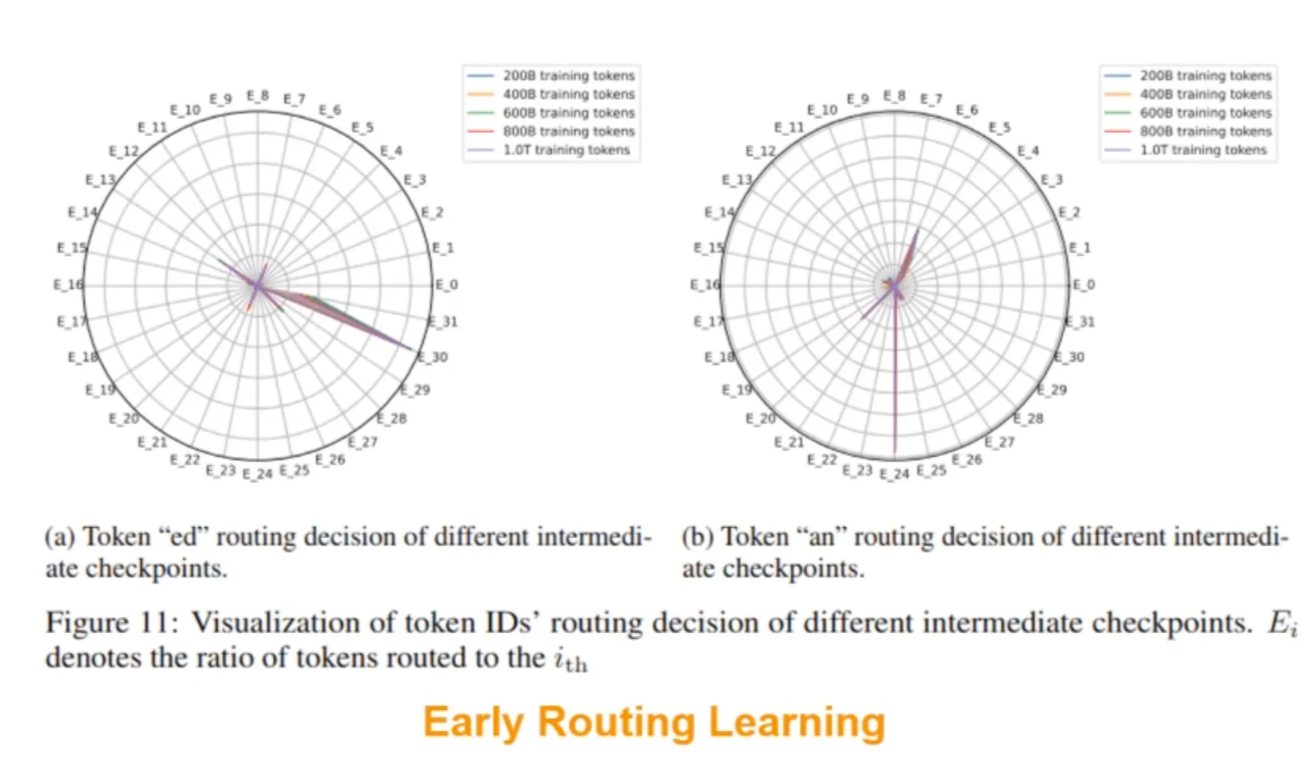
routing decision is learned very early when high-level semantics has not been learned well.
QA: MoE on consumer GPU
- Es are frequently swapped in and out with CPU memory/disk
- How to reduce I/O?
- prefetching E based on some correlations. For example, if Ex is activated in layer i, then Ey is likely to be activated in layer i+1.
Task specialization is actually token specialization:
- Coding expert: like coding tokens
- Math expert: like number tokens
- …
A Survey on Inference Optimization Techniques for Mixture of Experts Models
Drop towards the End
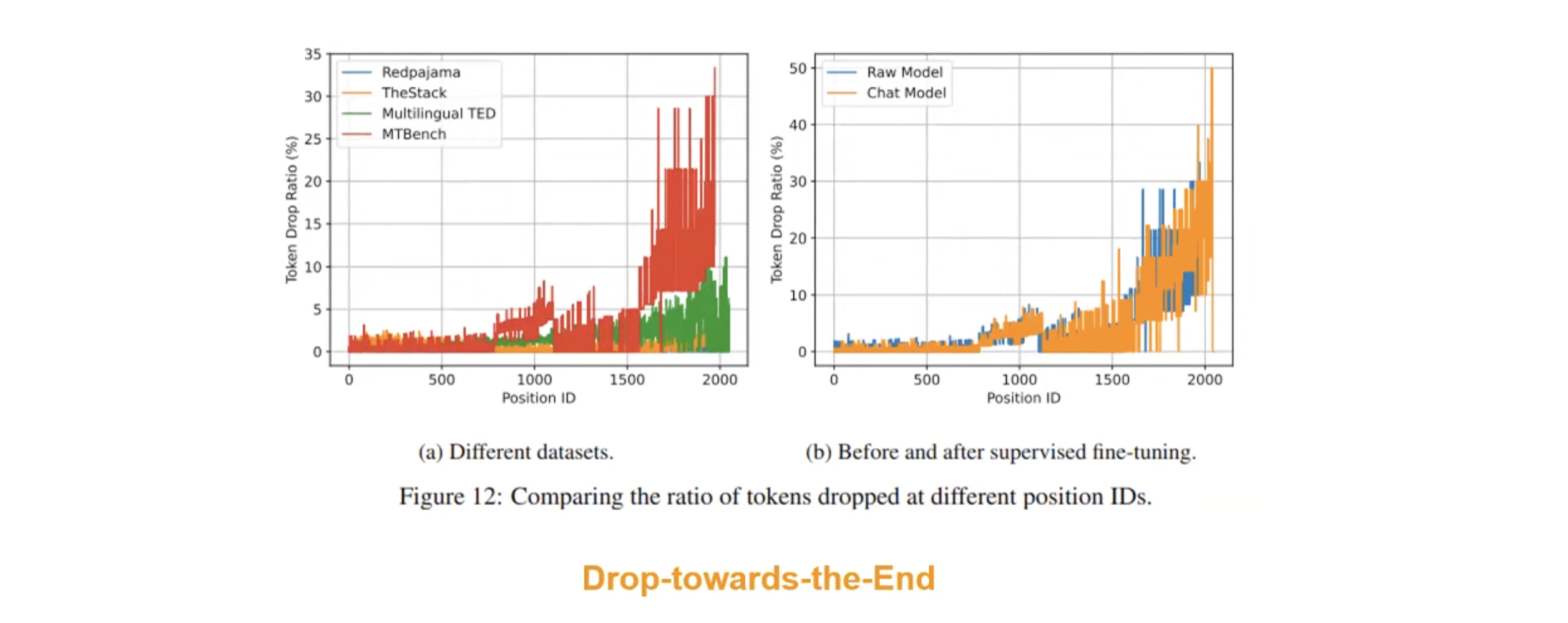
why multi-turn worse? Why few shots worse? Looks like it’s worse with longer context length.
recall we have capacity ratio: if E receives too many tokens, it will drop the latter ones.
Even with load balancing, tokens dispatched to a specific E can be still too many.
- Inference distribution can be very different from training distribution. E.g., we can have a bunch of coding tasks coming in a short period of time.
with longer context length, the load can be more imbalanced.
can this be solved during SFT? Tried but failed.
now with Megablock work, there is no C costraint anymore
Recent milestone: Megablock
Recent MoEs remove capacity ratio C → dropless-MoE (dMoE) → load is imbalanced
- → reduce EP. For example, 8 or 16 experts per GPU
- → MegaBlocks: convert dense batched matmul to sparse ones
https://github.com/databricks/megablocks
https://arxiv.org/abs/2211.15841
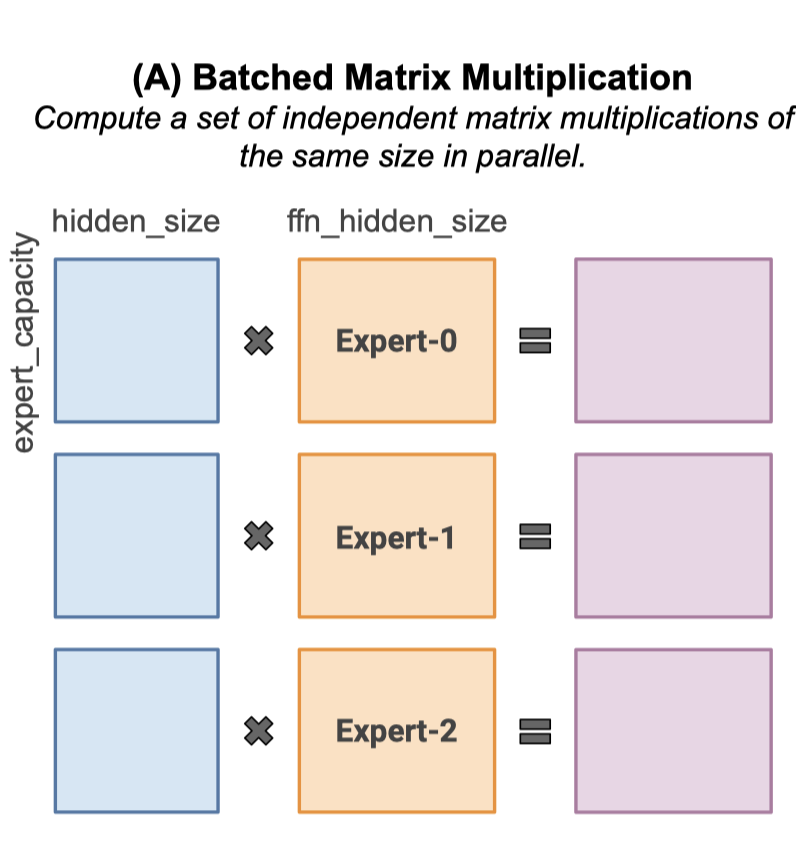
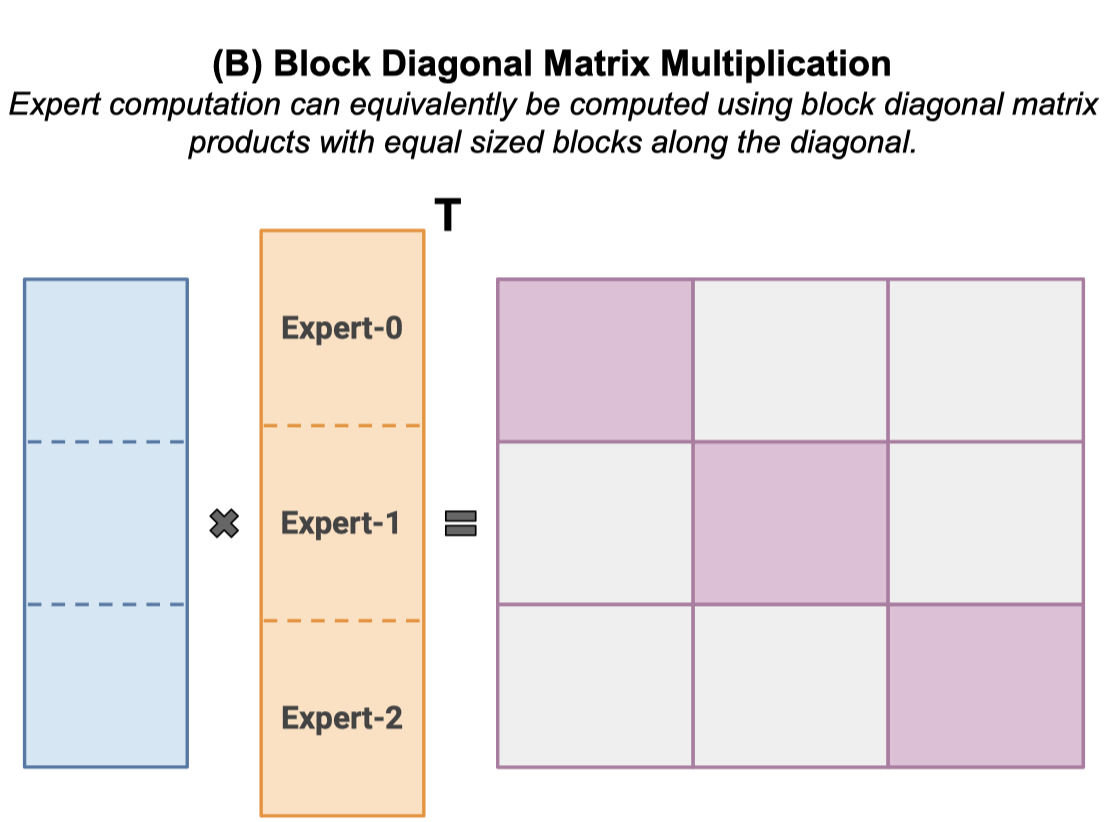
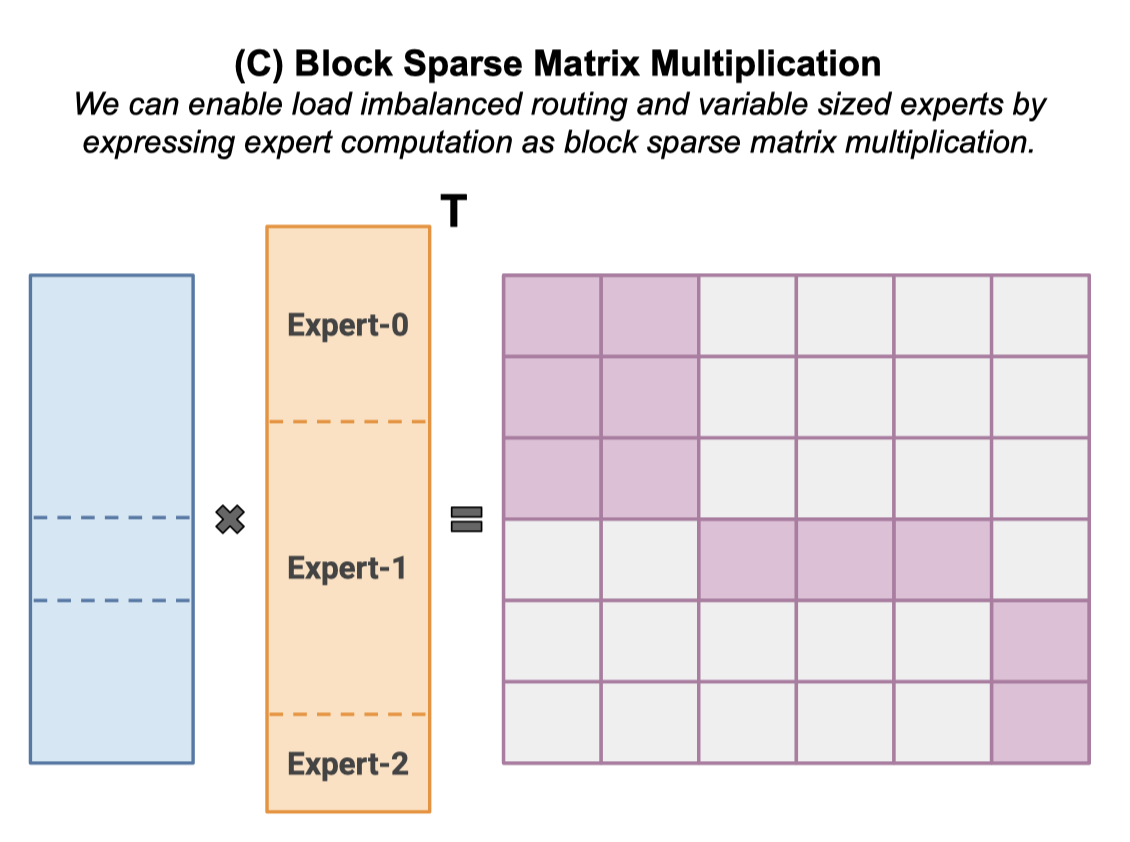
Figure 3. Expert Computation in an MoE Layer. Shown with num expert=3.
(A) State-of-the-art MoE implementations use batched matrix multiplication to compute all experts within a layer in parallel. This introduces the constraints that all experts are assigned the same number of tokens and that all experts have the same shape.
(B) Expert computation can be analogously posed in terms of block diagonal matrix multiplication with identically sized blocks.
(C) In order to relax these constraints, we can construct a block diagonal matrix with variable sized blocks made up of many smaller blocks. We can compute this matrix efficiently using block-sparse matrix multiplication.
there are many ways to compute block-sparse matmul efficiently.
A new trend: attention-MoE disaggregation
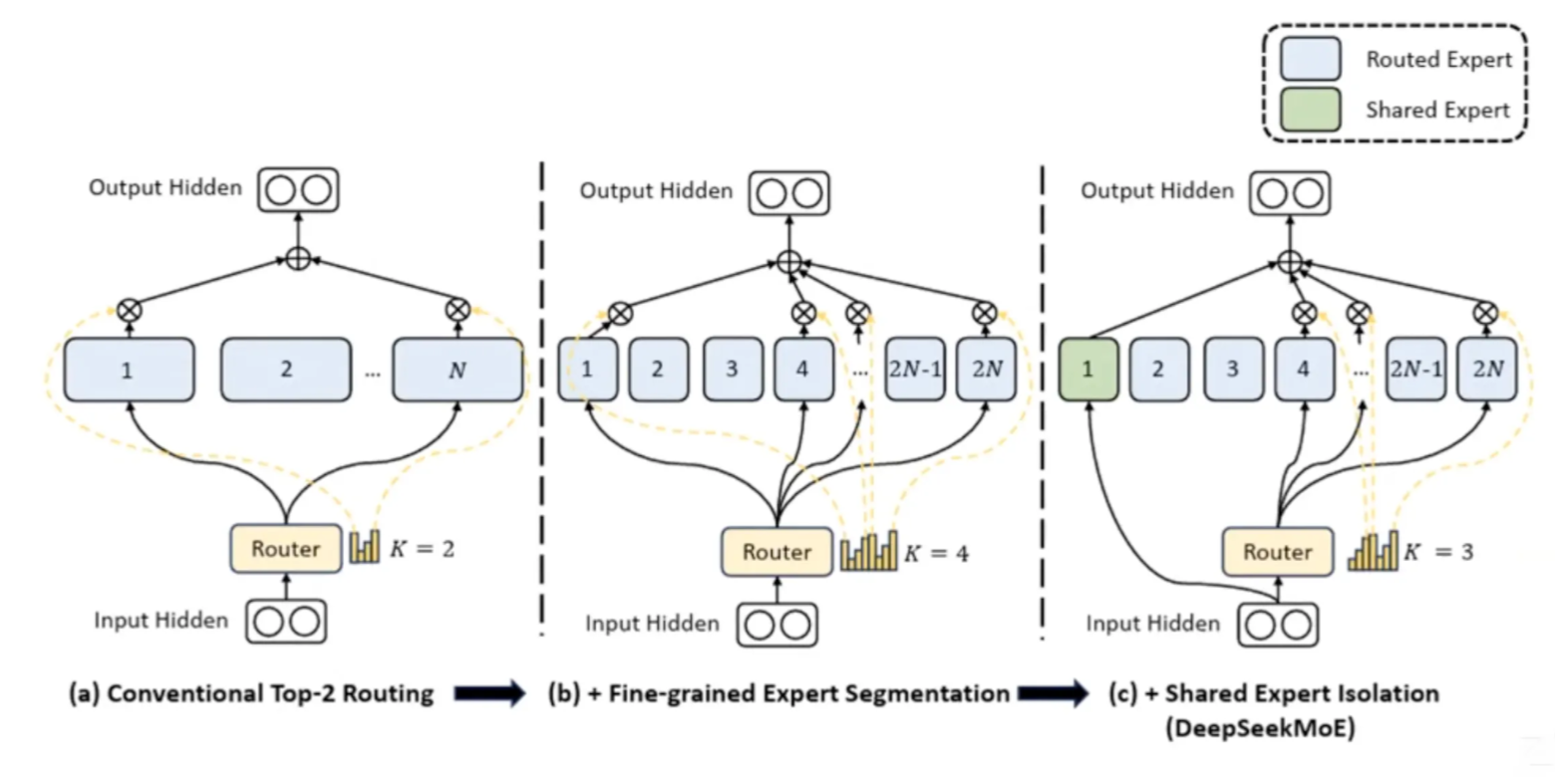
DeepSeek MoE
- More Es, and each E is smaller: more smooth routing
- More Es are activated
- Shared E: always on
- w/ EP, at least a GPU is not idle (it can do shared E computing)
KTransformers: attention on GPU, MoE on CPU
https://kvcache-ai.github.io/ktransformers/en/deepseek-v2-injection.html
https://github.com/kvcache-ai/ktransformers
More Thoughts
- MoE is tricky to train (load balance, training stability)
- Example: UL2 on OpenMoE becomes unstable at 34B parameters, limiting its use to 50B tokens on OpenMoE 34B
- MoE is more data hungry
- MoE models are prone to overfitting when trained on limited or repeated data
- MoE is more sensitive to data diversity
DeepSeek
- expert level lossless routing
- device level: 4 Es per GPU. load is balanced among GPUs. Es within the same GPU can be imbalanced
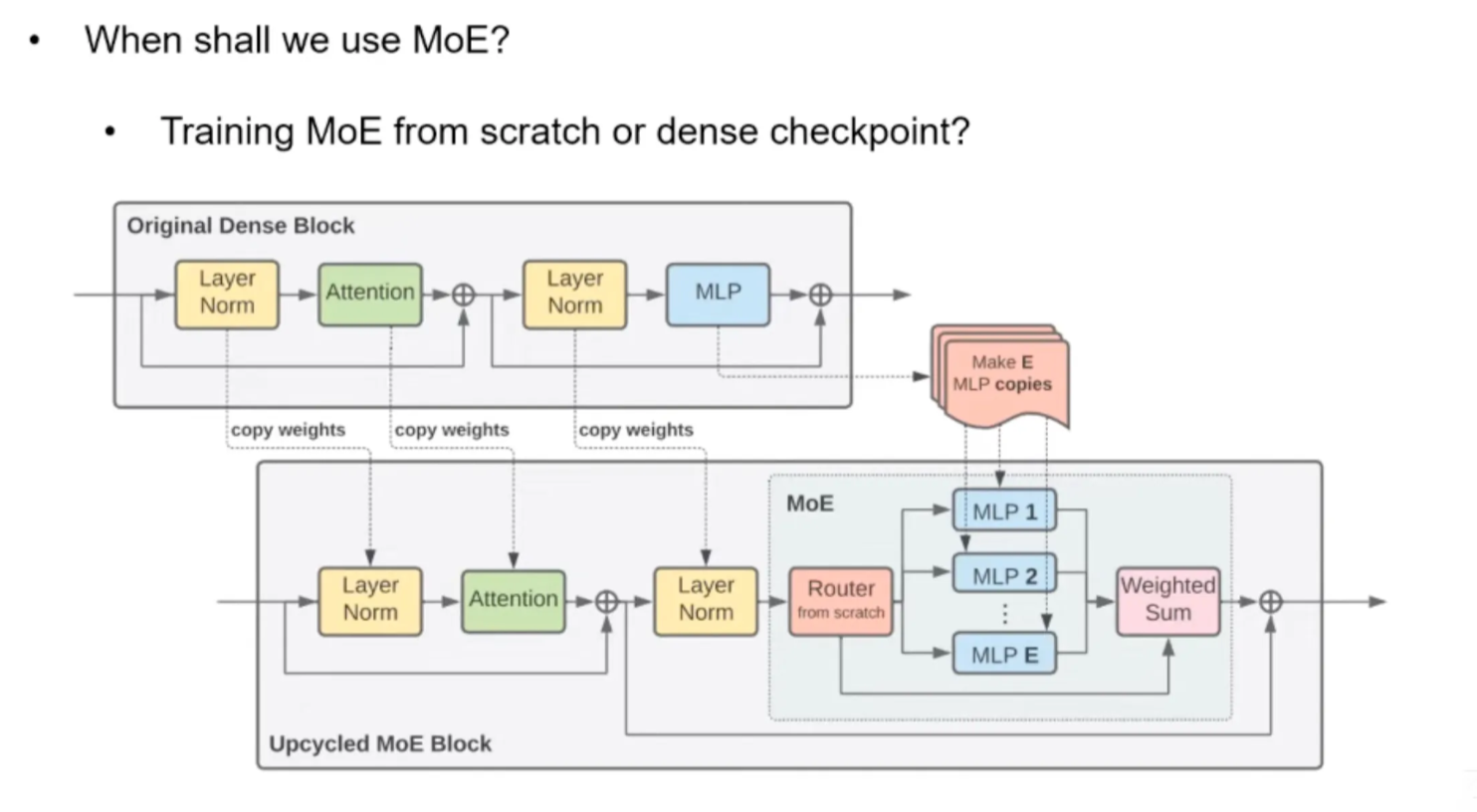
Dense upscaling: routing is more balanced as semantics are already learned in dense models
Token-choice vs expert-choice MoE
- Token-choice: choose E for each token
- Expert-choice: all tokens come, each E will choose which token to accept
- Context leak issue. Cannot be used in decoders
- Unless ur batch size is super large, and only select on the batch dimension
- Context leak issue. Cannot be used in decoders
Takeaways at that time
- Strength
- MoE can save around 50% training cost. (and more nowadays)
- MoE can save less than 50% inference cost.
- Weakness
- MoE is tricky to train (load balance, training stability).
- MoE is more data hungry.
- MoE is more sensitive to data diversity.
- MoE is more communication expensive (EP. not that hardware friendly).
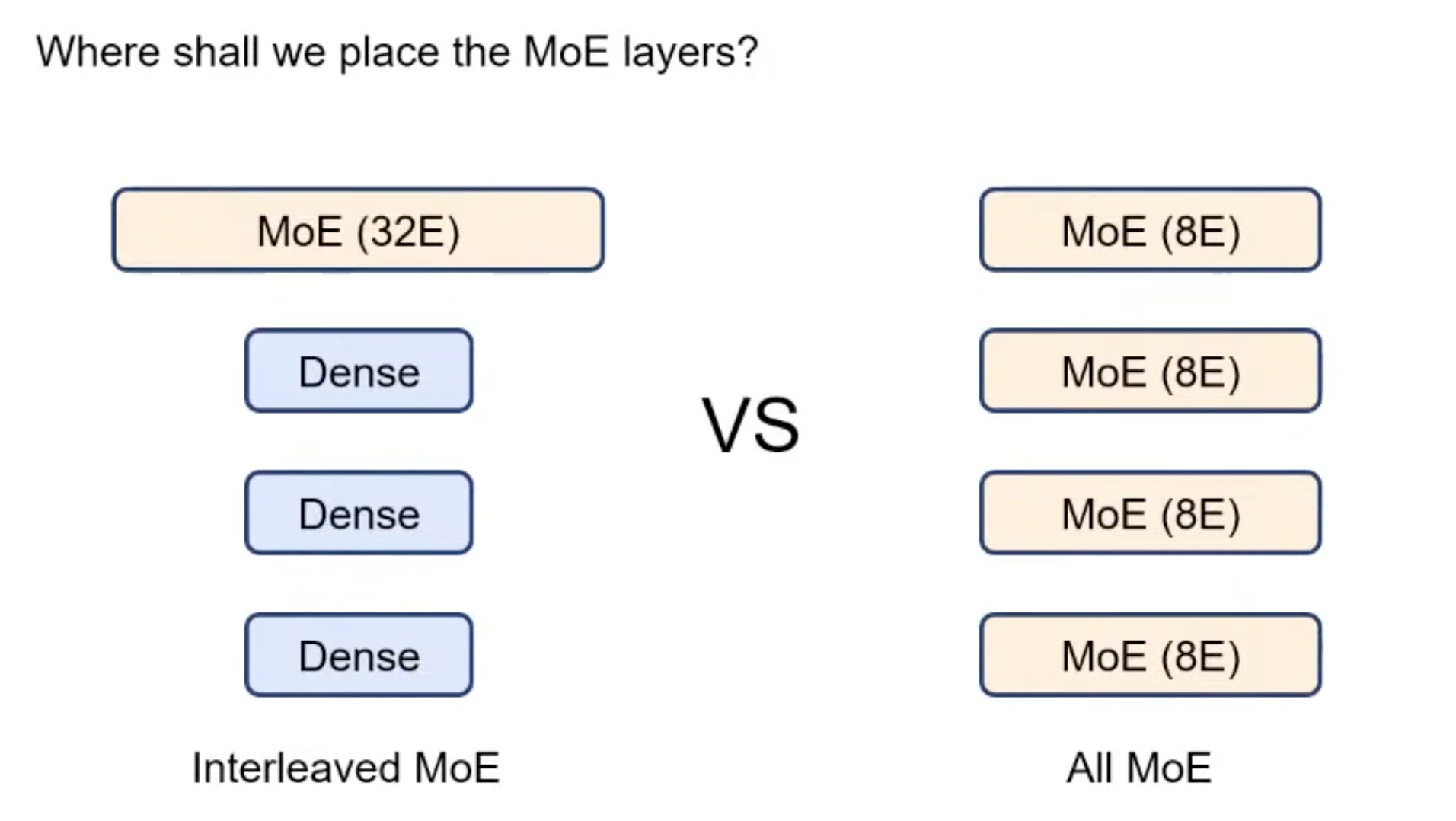
When shall we use MoE?
- Knowledge is important -> We use more parameters to store the knowledge
- A lot of queries in parallel -> We can utilize more experts efficiently.
- When we have enough data.
- When we have more time to debug (at least in this stage) 😊
vLLM MoE support
Core: handling EP
Route → MoE → Route back
Source