vLLM 04 - vLLM v1 version
Official V1 blog
https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
Why V1?
- V0 is slow: CPU overhead is high
- V0 is hard to read and develop
- e.g., V0 scheduler is 2k LOC, V1 is 800 LOC
- V0 code decoupling is bad. Modifying one part can lead to crashes of other parts
- Testing workload is high. Now the full testing suite takes 1h+ on A100/H100
- GPU-cluster based CI/CD is a good startup direction
- e.g., V0 scheduler is 2k LOC, V1 is 800 LOC
- We want V1 to be easy-to-hack
How to push out refactor?
switch after stabilized (private company dev)**
- Was doing MLE in a big tech company
- Need to put v0 into production in 1-2 months after v0 was released
- Based on business needs, 3 ppl need to add customized features on v0 (also model dev and testing)
- when features stabilized, add them to v1 as well
- make v0 and v1 online together, and gradually switch to v1
Switching after finishing dev in vllm: impractical, as new features & new models are coming very fast
vLLM’s most important feature: new model support!!
- candidate1: easy-to-use
- candidate2: performance
- candidate3: new model support
- however, day0 support leads to many technical debt
- some temp code will be used by others, and become harder and harder to remove
- Example1:
prepare_input()was 1000+ LOC - Example2: Attention kernel. Hard to have unified abstraction
vLLM team’s eventual plan
- Stage1: dev V1
- Stage2: V0 & V1 stay together
- Stage3: V1 on by default
- Stage4: V1 has more appealing features than V0
- Stage5: remove V0 completely
Why Pytorch wins Tensorflow?
- What TensorFlow claimed: they had the richest features, best hardware support, and best performance
- The actual reason: researchers preferred PyTorch more as it’s easier to use, and then those researchers graduated
- Note: vLLM v0 is not researcher-friendly enough
Key changes in V1
Scheduler
- Simplified scheduling: chunked prefill by default
- Synchronous scheduling
General architecture
- Scheduler, API server, (de) tokenizer in separate processes
Worker
- Persistent batching
- Piecewise cuda graph
- Attention kernel
- Simplified configuration
- Cascade inference
Multi-modality
- Embedding as the KV cache reference
- KV cache management (incoming)
- Hybrid memory allocator
1. Simplified Scheduler
Simplified API: how many extra tokens do we schedule for each request compared to last time
→ unified code path for different types of optimizations (prefix sharing, spec decode, …)
| Algorithm | Description | API |
|---|---|---|
| Prefill | Prefill entire prompt at once | {r, 500} |
| Decode | Generate one new token | {r, 1} |
| Chunked prefill | chunk size = 256 | {r, 256}, {r, 244} |
| Prefix caching | r hits 200 cached tokens | {r: 300} |
| Spec decoding | guess 5 tokens per step | {r: 5} |
| Multi-modality | r is a seq of 100 text tokens + 500 img tokens + 100 text tokens | {r: 100}, {r: 500}, {r:100} |
Again, for different optimization algorithms, you just need to figure out how many new tokens to schedule
[Public] vLLM x Ollama Meetup @ YC https://docs.google.com/presentation/d/16T2PDD1YwRnZ4Tu8Q5r6n53c5Lr5c73UV9Vd2_eBo4U/

scheduler path: vllm/v1/core/sched/scheduler.py
- much easier to read than V0 scheduler
vllm/core/scheduler.py
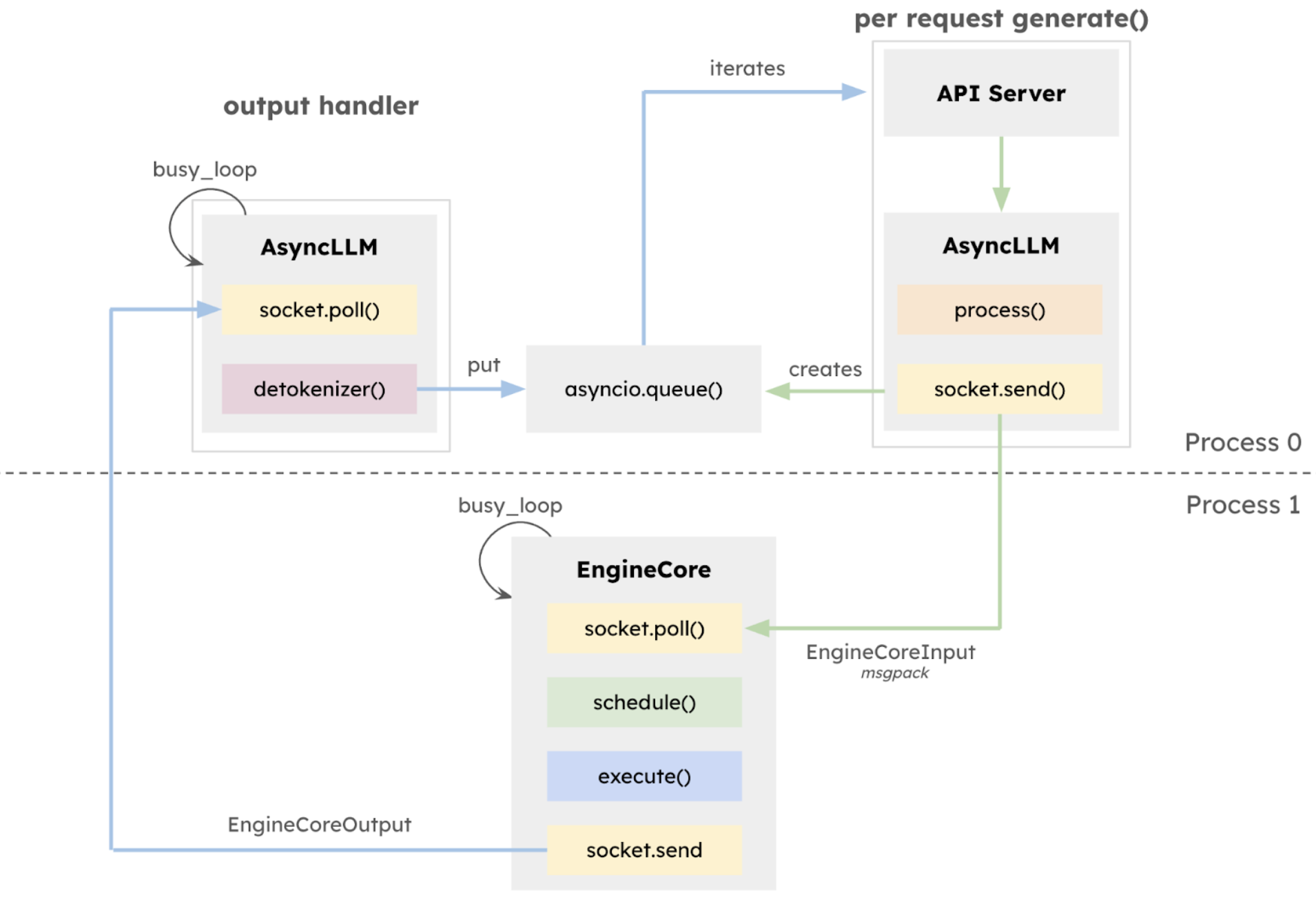
2. General arch: separate processes
2.1 b/w API/scheduler/(de) tokenizer
EngineCore will not be slowed down by others
Lessons
- Backend optimization is still important!
- However, backend guys don’t really know frontend logic.
- LLM guys need to tell backend guys what to optimize.
- Efficient communication is hard but critical.
Open discussion: microservice for LLM?
Microservice will increase communication for better scalability. However, communication regarding LLM inference involves tensors → large overhead
When scalability issue is really bad, microservice will be more popular.
- Prediction: it will be popular in 2-3 years
- Time Machine Theory: an investment strategy that leverages time gaps between markets by replicating successful business models from advanced economies in emerging ones.
P/D disaggregation is a kind of microservice. P service + D service
P/D disaggregation works well, but when other types of microservices work is still not clear
MoE disaggregation
Spec decoding disaggregation
Open discussion: LLM API will not be popular
- API essentially mixes different workloads
- Different LLM workloads will interfere with each other
- For example, if you put prefill-heavy workload and decode-heavy workloads together
- prefill TTFT will be worse
- decode ITL will be worse
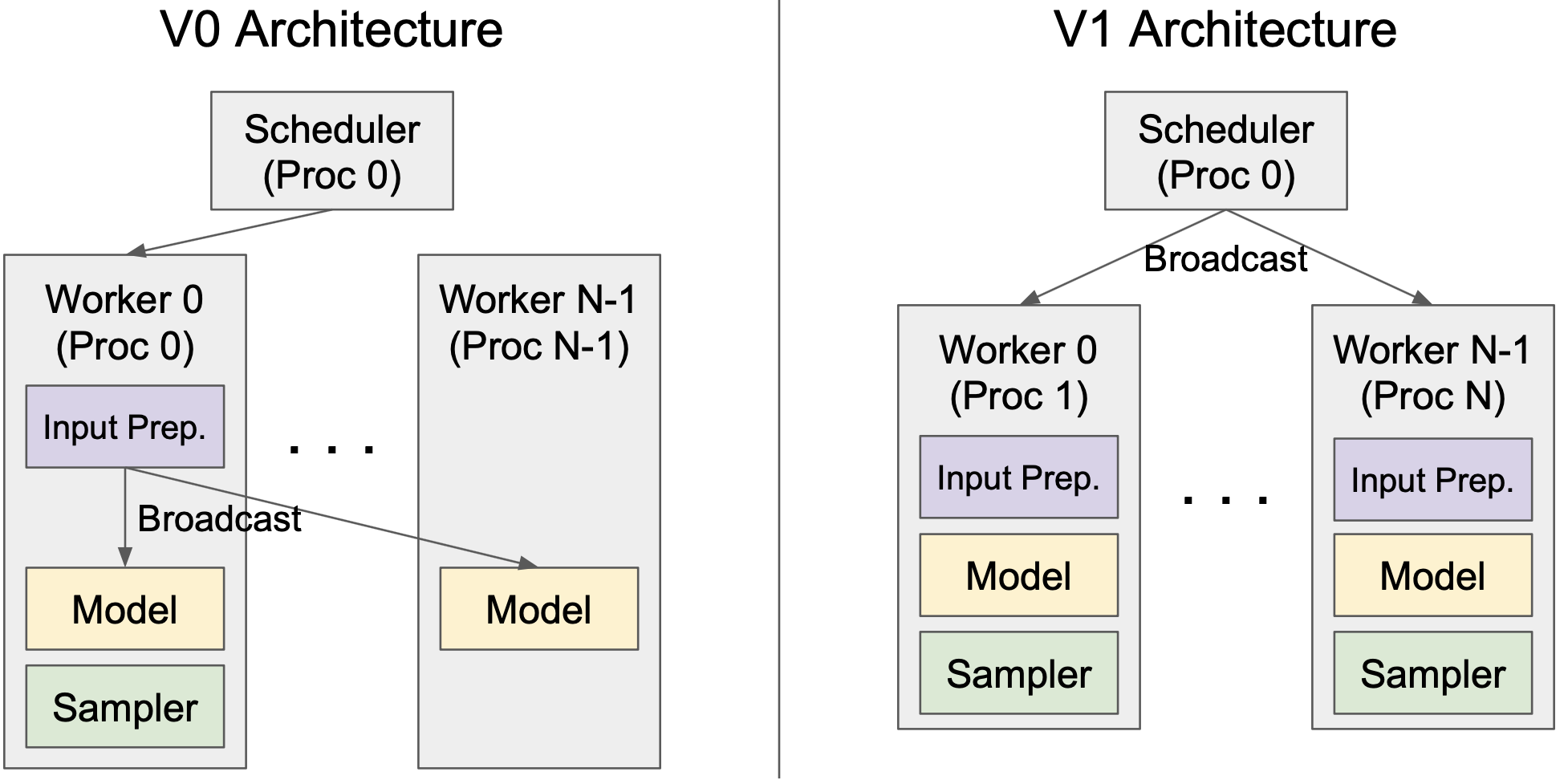
2.2 between scheduler/worker for TP
V0: Scheduler & Rank0 worker co-locate in the same process (previously in v0)
- Process 0 will broadcast the input → large overhead
V1: Scheduler & Worker in separate process.
- Only broadcast the scheduling decision (a tiny object).
- No input broadcast. Good for TP.
V1: strict SPMD (Single Program, Multiple Data) among workers
- Necessary for RLHF
3. Worker
3.1 Persistent batching
- We only send the delta between the GPU tensors of previous batch and the GPU tensors of this batch from CPU to GPU.
- We don’t construct all tensors from input requests each time
- This technique is not new (maybe from LightLLM)
An extreme example
- a request has 1M tokens, and each time one more token is added
- in this case, we need to serialize 1M tokens each time
- and we need to transfer those tensors from CPU to GPU
- with persistent batching, only one token tensor is transferred to GPU
Code path
vllm/v1/worker/gpu_input_batch.pyvllm/v1/worker/gpu_model_runner.py
Sample code from gpu_input_batch.py
1 | |
The InputBatch class:
Holds persistent, pinned-CPU buffers for every live request (prompt + already-generated tokens)
token_ids_cpu_tensor(and its NumPy view);num_computed_tokens_cpu_tensora
BlockTablefor tracking KV-cache block IDsper-request sampling parameters (temperature, top-p/k, penalties, logit-bias, etc.) in CPU & device tensors
LoRA mappings, prompt-token tensors, generator handles, etc.
Exposes methods to add or remove a request
add_request(request)copies only that request’s prompt + output token IDs into the CPU buffers, updates the block table and all sampling/LoRA metadataremove_request(req_id)+condense(empty_indices)will clear out finished slots and pack the live ones into a dense batchLets the GPU runner do incremental H2D transfers
In each
_prepare_inputscall, GPUModelRunner simply- a) re-indexes into the same pinned-CPU tensor (via
torch.index_selecton the flattened buffer) to gather “new” tokens for all requests - b) non-blocking-copies only those slices into the pre-allocated GPU input tensors
- c) reuses the same block-table and sampling-metadata tensors on device
- a) re-indexes into the same pinned-CPU tensor (via
It is especially useful for long-running or streaming requests where only a small part of the input changes at each step.
3.2 Piecewise CUDA graph
CUDA graph basics:
Records a series of CUDA kernel operations to replay later
While CPU launching CUDA kernel is slow, individual CUDA kernels can be very fast
Benefit: creates an abstraction to launch the whole sequence of kernels as one operator → significantly reduces CPU-GPU communication (each communication is close to 1 ms)
Limitation: Does not record CPU operations, which reduces flexibility.
- No dynamic tensors are allowed.
- Tensor shapes must be static.
- Index ops must be in GPU.
- Hard to debug. For example, some ops are wrongly put on CPU (while you think they are on GPU) and will not be recorded.
Key observation: Flexibility is typically needed in attention layer, not MLP layer
- For example, you may wanna switch to sparse attention, Mamba attention, RAGAttention, etc. and customize them
Solution: Piece-wise CUDA Graph - only records CUDA graph for MLP layers while keeping attention in PyTorch eager mode
How to deal with LoRA?
- Put index to GPU buffer.
- MLP layer: load corresponding LoRA adapter based on GPU buffer index
The philosophy behind this solution (classical system engineering technique) :
- FeatureA is easy to use, but slow
- FeatureB is fast, but hard to use
- Hybrid solution (FeatureA + FeatureB) is preferred
4. Attention kernel
4.1 simplified configuration
Before: vLLM will prepare ~20 attention-related tensors
Key observation: the info needed for each attention kernel is only 6-7 tensors
Solution: only construct those key 6-7 tensors, and let the kernel do the rest
4.2 Cascade inference
Useful for the following scenarios:
System prompt: 10k tokens
10 user chats: each chat with 100 tokens
Normal attention: how many memory reads?
- (10k + 100) * 10 tokens
Cascade inference: Common prefix is read only once
- 10k + 100 * 10 tokens
vLLM has a performance model to decide when to use cascade inference
code path: vllm/v1/attention/backends/flash_attn.py
1 | |
5. Multi-modality
- Embedding as the KV cache reference
- KV cache management (incoming)
- Hybrid memory allocator
Source